wejh
2.4K posts














Bittensor founder @const_reborn on training a 1 trillion parameter LLM “It took them 1 year to train 30B, we are going to do it in 1 month.” On the Teutonic (ex-templar) subnet


Used autoresearch to make @grail_ai GRPO trainer 1.8x faster on a single B200. I kept postponing this for weeks since the bottleneck in our decentralized framework was mainly communication. But after our proposed technique, PULSE, made weight sync 100x faster, the training update itself became the bottleneck. Even with a fully async trainer and inference, a slow trainer kills convergence speed. A task that could've eaten days of my time ran in parallel while I worked on other stuff. Unlike original autoresearch, where each experiment is 5 min, our feedback loop is way longer (10-17 min per epoch + 10-60 minutes of installations and code changes), so I did minimal steering when it was heading in bad directions to avoid burning GPU hours. The agent tried so many things that failed. But, eventually found the wins: Liger kernel, sequence packing, token-budget dynamic batching, and native FA4 via AttentionInterface. 27% to 47% MFU. 16.7 min to 9.2 min per epoch. If you wanna dig deeper or contribute: github.com/tplr-ai/grail We're optimizing everything at the scale of global nodes to make decentralized post-training as fast as centralized ones. Stay tuned for some cool models coming out of this effort. Cheers!


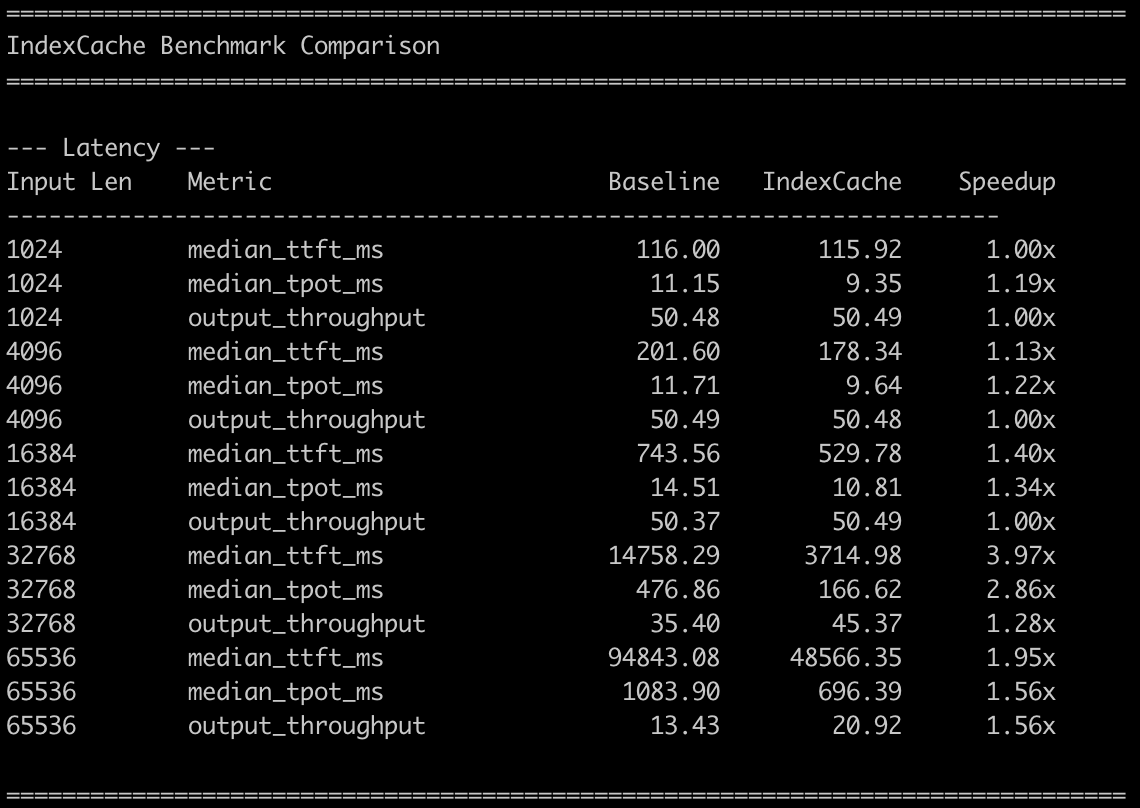
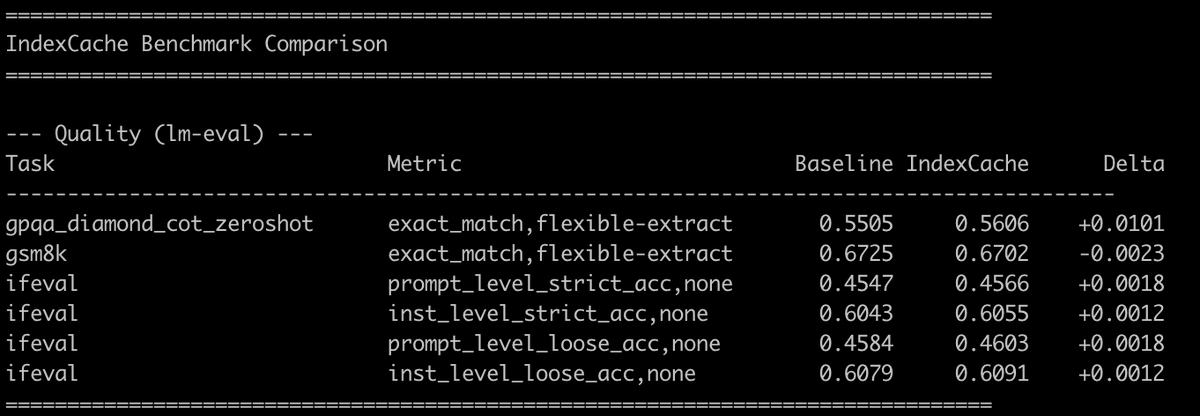
🧵 1/4 Still waiting for DeepSeek-V4? We (@Zai_org) made DSA 1.8× faster with minimal code change — and it's ready to deliver real inference gains on GLM-5. IndexCache removes 50% of indexer computations in DeepSeek Sparse Attention with virtually zero quality loss. On GLM-5 (744B), we get ~1.2× E2E speedup while matching the original across both long-context and reasoning tasks. On our experimental-sized 30B model, removing 75% of indexers gives 1.82× prefill and 1.48× decode speedup at 200K context. How? 🧵👇 #DeepSeek #GLM5 #Deepseekv4 #LLM #Inference #Efficiency #LongContext #MLSys #SparseAttention
🔒The full client-side E2E encryption framework is ready to be deployed, along with a boatload of other updates. Hope to start rolling it out tomorrow morning. github.com/chutesai/chute… This will likely be the most secure and verifiable inference anywhere on the planet, with zero (well, let's say infinitesimally small) risk of evesdropping or prompt leakage/etc. So, TEE node spins up, creates ephemeral quantum-safe encryption key, client gets the quote for instances to verify the secure enclave, gets the public key for an instance, encrypts their request for exactly that one instance and sends along a response encryption key. Only the client and that TEE pod will ever see the request, no evesdropping even possible, and being TEE nodes with in-memory keys no chance of decrypting or seeing the traffic regardless even with physical access to host. The other PRs: github.com/chutesai/chute… github.com/chutesai/chute… (and like 100k lines of C code part of our proprietary aegis library) The amount of stuff in aegis (and then our proprietary virtualization/obfuscation/packing/crypto/etc. lib) is quite extensive. Everything is stable in dev 🚀






