
Adrien Carreira
467 posts

Adrien Carreira
@XciD_
Head of Infrastructure @huggingface
Lyon, France Katılım Haziran 2011
669 Takip Edilen624 Takipçiler

Announcing a new Claude Code feature: Remote Control. It's rolling out now to Max users in research preview. Try it with /remote-control
Start local sessions from the terminal, then continue them from your phone. Take a walk, see the sun, walk your dog without losing your flow.
English
Finally updated the org chart. Yes, Claude gets a @huggingface.co email. No, we're not discussing their compensation.
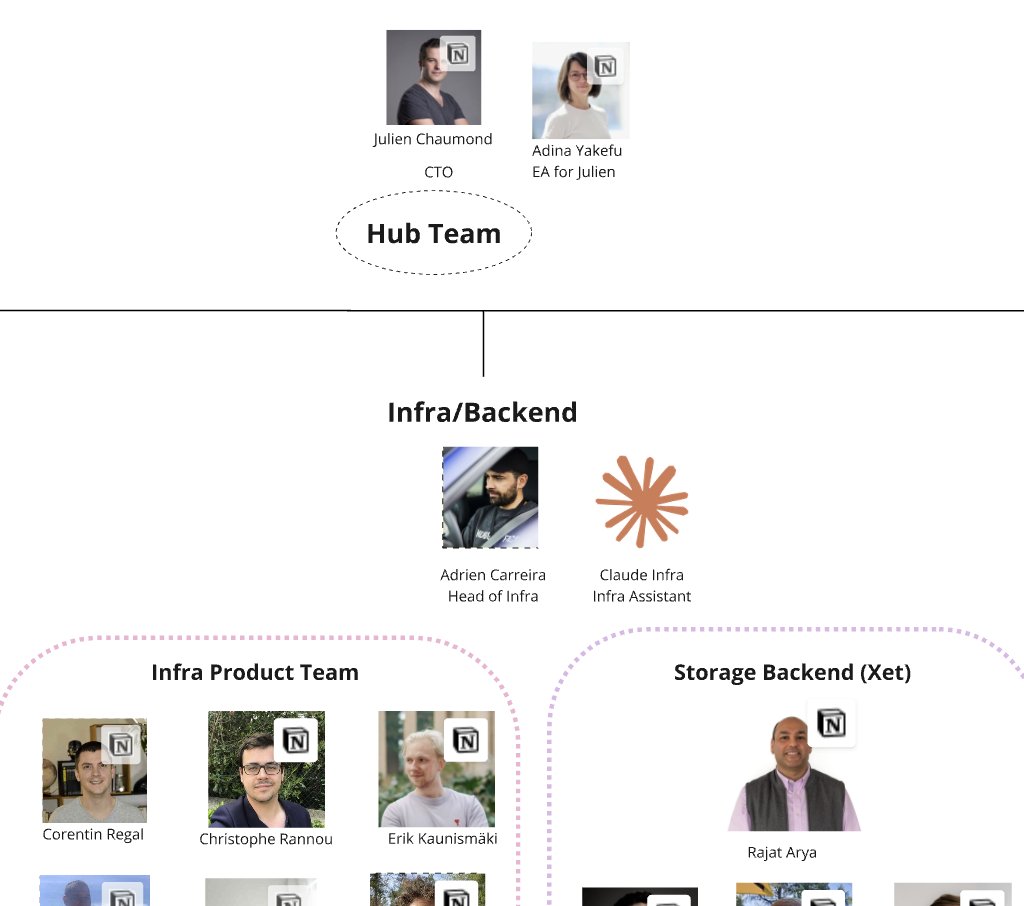
English
Adrien Carreira retweetledi

Virus Total is now integrated to HF, LET'S GO
This is kind of recursive when you think about it, VT runs ClamAV as well 🤓
In any case, it's a great move to further secure artefacts pushed to the Hub, as VT has a very comprehensive suit of AVs running all at once (>70)!
Kudos to @XciD_ and @bquintero for making the integration happen!!

English
Adrien Carreira retweetledi

Wanna upgrade your agent game?
With @AIatMeta , we're releasing 2 incredibly cool artefacts:
- GAIA 2: assistant evaluation with a twist (new: adaptability, robustness to failure & time sensitivity)
- ARE, an agent research environment to empower all!
huggingface.co/blog/gaia2
English
Adrien Carreira retweetledi

When @sama told me at the AI summit in Paris that they were serious about releasing open-source models & asked what would be useful, I couldn’t believe it.
But six months of collaboration later, here it is: Welcome to OSS-GPT on @huggingface! It comes in two sizes, for both maximum reasoning capabilities & on-device, cheaper, faster option, all apache 2.0. It’s integrated with our inference partners that power the official demo.
This open-source release is critically important & timely, because as @WhiteHouse emphasized in the US Action plan, we need stronger American open-source AI foundations. And who could do that better than the very startup that has been pioneering and leading the field in so many ways.
Feels like a plot twist.
Feels like a comeback.
Feels like the beginning of something big, let’s go open-source AI 🔥🔥🔥

English
Adrien Carreira retweetledi

Please don’t download the weights all at once 🙏 or our servers will melt

English
Adrien Carreira retweetledi
I'm notorious for turning down 99% of the hundreds of requests every months to join calls (because I hate calls!). The @huggingface team saw an opportunity and bullied me in accepting to do a zoom call with users who upgrade to pro. I only caved under one strict condition: everyone gets crammed into a single chaotic group call. So… here we are: huggingface.co/pro?promo=zoom…
Please don’t upgrade. I still very much do not want to do Zoom calls 😂😂😂

English
Starting today you can run any of the 100K+ GGUFs on Hugging Face directly with Docker Run!
All of it one single line: docker model run hf.co/bartowski/Llam…
Excited to see how y'all will use it

English
Adrien Carreira retweetledi

Thrilled to finally share what we've been working on for months at @huggingface 🤝@pollenrobotics
Our first robot: Reachy Mini
A dream come true: cute and low priced, hackable yet easy to use, powered by open-source and the infinite community.
Tiny price, small size, huge possibilities. A robot built to code, learn, share with AI builders of all ages, all around the globe, using the latest vision, speech and text AI model. A first robot for today's and tomorrow's AI builders.
Read more and order now at hf.co/blog/reachy-mi…
First deliveries expected right after the summer.
English
@ibuildthecloud @julien_c yeah strange from cloudfront to
trim it. currently investigating with them to fix it
English
Adrien Carreira retweetledi
Today is a big day, we're introducing the first version of the HF MCP server 🔥
🧵

English
@ibuildthecloud @julien_c Hey Darren, you're right — huggingface.co uses CloudFront, which seems to trim duplicate headers for now. You can bypass it by combining values in one header:
-H 'Accept: application/json, text/event-stream'
Hope that helps!
English

There's something weird about huggingface.co/mcp vs hf.co. hf.co/mcp works vs huggingface.co/mcp doesn't work and your docs refer to the later. This can be reproduced with the two curl commands. You can't reproduce this with MCP inspector
WORKS:
curl -H "Authorization: Bearer doesntmatter" -X POST -H 'Accept: application/json' -H 'Content-Type: application/json' --data '{}' -H 'Accept: text/event-stream' hf.co/mcp
FAILS:
curl -H "Authorization: Bearer doesntmatter" -X POST -H 'Accept: application/json' -H 'Content-Type: application/json' --data '{}' -H 'Accept: text/event-stream' huggingface.co/mcp
The later will return
{"jsonrpc":"2.0","error":{"code":-32000,"message":"Not Acceptable: Client must accept both application/json and text/event-stream"},"id":null}
And the headers are clearly set. I'm guess you are going through some proxy and maybe you added some special user-agent logic that MCP inspector sets but basic curl doesn't. I have a custom client and this is failing for me.
English
Adrien Carreira retweetledi

Continuing to move all the LFS bytes into Xet storage on Hugging Face! Currently up to:
🤗 5,500 users and orgs with Xet access
🚀 150,000 Xet-backed models and datasets
🤯 4+ PB managed by Xet
How much more to go? If the Hub's top storage users are any indication: many bytes

English
Adrien Carreira retweetledi

A quick update on the future of the `transformers` library!
In order to provide a source of truth for all models, we are working with the rest of the ecosystem to make the modeling code the standard.
A joint effort with vLLM, LlamaCPP, SGLang, Mlx, Qwen, Glm, Unsloth, Axoloth, Deepspeed, IBM, Gemma, Llama, Deepseek, microsoft, nvidia, internLM, Llava, AllenAI, Cohere, TogetherAI.....
English
Adrien Carreira retweetledi
The entire Xet team is so excited to bring Llama 4 to the @huggingface community. Every byte downloaded comes through our infrastructure ❤️ 🤗 ❤️ 🤗 ❤️ 🤗
Read the release post to see more about these SOTA models.
huggingface.co/blog/llama4-re…
English
Adrien Carreira retweetledi

Meta COOKED! Llama 4 is out! Llama 4 Maverick (402B) and Scout (109B) - natively multimodal, multilingual and scaled to 10 MILLION context! BEATS DeepSeek v3🔥
Llama 4 Maverick:
> 17B active parameters, 128 experts, 400B total parameters > Beats GPT-4o & Gemini 2.0 Flash, competitive with DeepSeek v3 at half the active parameters > 1417 ELO on LMArena (chat performance). > Optimized for image understanding, reasoning, and multilingual tasks
Llama 4 Scout:
> 17B active parameters, 16 experts, 109B total parameters
> Best-in-class multimodal model for its size, fits on a single H100 GPU (with Int4 quantization)
> 10M token context window
> Outperforms Gemma 3, Gemini 2.0 Flash-Lite, Mistral 3.1 on benchmarks
Architecture & Innovations
> Mixture-of-Experts (MoE):
First natively multimodal Llama models with MoE
> Llama 4 Maverick: 128 experts, shared expert + routed experts for better efficiency.
Native Multimodality & Early Fusion:
> Jointly pre-trained on text, images, video (30T+ tokens, 2x Llama 3)
> MetaCLIP-based vision encoder, optimized for LLM integration
> Supports multi-image inputs (up to 8 tested, 48 pre-trained)
Long Context & iRoPE Architecture:
> 10M token support (Llama 4 Scout)
> Interleaved attention layers (no positional embeddings)
> Temperature-scaled attention for better length generalization
Training Efficiency:
> FP8 precision (390 TFLOPs/GPU on 32K GPUs for Behemoth)
> MetaP technique: Auto-tuning hyperparameters (learning rates, initialization)
Revamped Pipeline:
> Lightweight Supervised Fine-Tuning (SFT) → Online RL → Lightweight DPO
> Hard-prompt filtering (50%+ easy data removed) for better reasoning/coding
> Continuous Online RL: Adaptive filtering for medium/hard prompts
All model on Hugging Face - time to COOK!

English
Adrien Carreira retweetledi


Adrien Carreira retweetledi

Adrien Carreira retweetledi
I analyzed all public GGUF models on the Hub for the llama-cpp-python chat template vulnerability. Good news: out of 116K+ GGUF models, none are currently dangerous! 🧵
English
Adrien Carreira retweetledi

Text Generation Inference v2.0.0 is the fastest open-source implementation of Cohere Command R+!
Command R+ is the best open-weights model.
Leveraging the power of Medusa heads, TGI achieves unparalleled speeds with a latency as low as 9ms per token for a 104B model!
GIF
English