
YouAndYourBS
7.7K posts


Why do people keep comparing today’s market to 1999-2000? I’ve genuinely tried to find the similarities and I’m struggling. Can anyone explain the top conspiracy theories behind why this is supposedly the same environment?
English
@dampedspring @JC_ParetsX I’m old, lived through it.
They don’t feel the same at all. And have virtually nothing in common.
Internet companies weren’t taking in billions in real user revenues. Industries weren’t being transformed.
1999 was about the promise that this would happen. It took time.
English

@JC_ParetsX A big difference is you were in high school. Having not lived through the experience is probably quite confusing to you.
English
@thedimitri @johnthenoticer Wouldn’t a systemically racist society not have people of similar competence have similar outcomes if it was specifically in regards to a race that is being marginalized and oppressed?
English

@johnthenoticer This doesn't really disprove anything about systemic racism's existence, it proves that if two people are essentially equally competent they'll have similar outcomes.
English

In the United States, white people earn significantly more than black people on average.
But as soon as you compare blacks and whites with the same IQ, that gap disappears like magic...
This is one of the clearest pieces of evidence that systemic racism isn't what's driving the raw overall income disparity between the two groups.

English
@marceelias Stop LARPing as a 70s revolutionary.
You’re not fighting for democracy, you’re hoping republicans don’t even exist and your team can run everything.
English

I often say that the fight for democracy is the fight of our generation. But let me be clear, if you aren’t fighting for Black voting rights right now then you aren’t really fighting for democracy.
English

so instead of saying “funky cabins within 2 hour drive”
i will have to keep filling out your patient intake form
Brian Chesky@bchesky
@benhylak The ChatGPT interface doesn’t work for this. We’ve already tried it.
English
@james_roe @SwannMarcus89 Right. We just weren't progressive enough. We really gotta ratchet it up even more.
English

@SwannMarcus89 The West Coast is a neoliberal utopia, not a progressive one.
English

I swear to Christ the Democratic Party’s message at this point is “all of the most progressive places are unaffordable shitholes where nobody can afford an apartment, therefore you should vote for us”

English

This interaction by @eliguerron is so cool, here’s my iteration, thought a way to delete the entire page could be useful
Elí Guerrón@eliguerron
When I was at Apple, I loved working on micro interactions that you see all over the OS. Now that I’m not an apple I still like to solve for these little problems that really annoyed me. In this case, I designed a backspace button with a speed controller, so by just pressing it you can delete by letter and then immediately by word as you stretch it, without having to wait (like it usually does on the OS) and then if you stretch a little more, you can speed delete through words… I’m also working on another one where you can repair the words if you over-deleted it by accident 😜 (it also has haptic feedback, which makes it really fun)
English

MrBeast: "If my mental health was a priority I wouldn't be as successful as I am"
"I obviously never would have buried myself alive for seven days. There's a reason no one makes videos like me, not even close. Because no one wants to live the life I live"
"There were months I'm flying 200 days a year on a plane. To get these videos done I do everything"
"Something I always tell myself is how you feel right now is why no one else does what you do. If you push through this that's just even more of a reason why no one will ever be who you are"
"Once you make a couple million dollars why would you live the life I live? Why would you not take weekends off? Why would you not prioritize your sanity? It makes no sense. But that's why no one else does it"
English

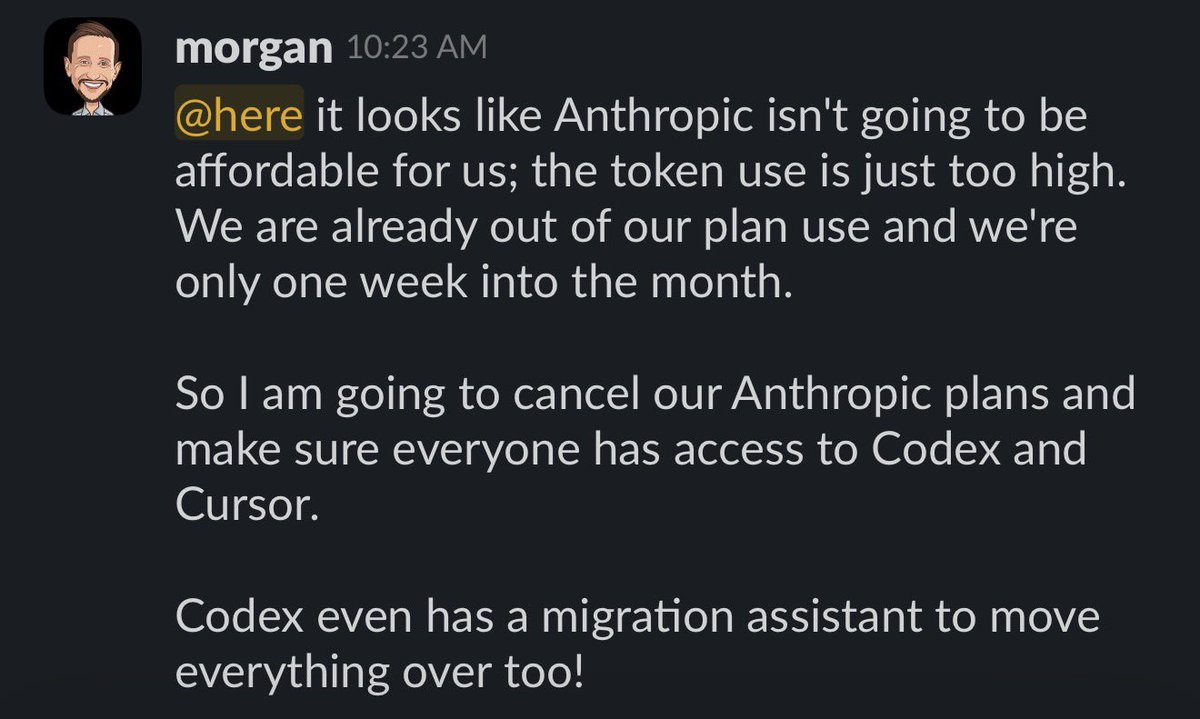
Officially canceling our Anthropic plan, it’s Codex + Cursor for my little 16 person eng team.
Anthropic is great for companies that can spend $2,000/mo and up per engineer, but not affordable for us.
Codex really upped their game recently, and with GPT 5.5, it’s just so good, and so token efficient.
Still using Cursor plenty, my team still looks and reviews a lot of code.
But with Cursor, we’ve never hit a limit, and Composer 2 is pretty awesome for most stuff.
Testing out Droid as well and see some good early results with Droid + GLM 5.1, but still more testing to do before rolling it out to the whole team.
My guess is many more engineering leaders will be sending messages like this. Anthropic makes great stuff but phew, it’s so darn token hungry.
My team loves Codex and Cursor, onward!
English

@G_S_Bhogal This optimistic take reminds me of when I was a kid and the internet was brand new, and I thought to myself “this will end human ignorance.”
Still hope you are right though.
English


orchestrate a swarm of agents
here's a visualization of the swarm and how it's using multiple planners, verifiers, and workers
try it today with /add-plugin orchestrate and then /orchestrate [goal]
Cursor@cursor_ai
Introducing /orchestrate, a skill that recursively spawns agents to tackle your most ambitious tasks with the Cursor SDK. We’ve used it to: - Autoresearch our internal skills, cutting token use by 20% while improving evals - Cut cold start times on our internal backend by 80%
English

@Noahpinion If you did you wouldn't talking about millionaires and billionares as if they are the same.
English

I am concerned that the Dems are becoming the party of "millionaires who resent billionaires".
"I made my millions fair and square, but you cheated and exploited the workers to make your billions, you capitalist pig!"
Marco Foster@MarcoFoster_
AOC: “There’s a certain level of wealth and accumulation that is unearned. You can’t earn a billion dollars. You just can’t earn that. You can get market power, you can break rules, you can abuse labor laws, you can pay people less than what they’re worth, but you can’t earn that”
English
@Jason We used to have a bunch of people in my company's Slack using them. Just checked, no one is.
That fad (that was a morale imperative and showed you were a good human being!) sure died fast.
English

Had someone at one of my companies using pronouns in their communications, and I was like, "dude, you know this looks immature and silly to 90% of our partners."
He quit a couple of months later.
ZUBY:@ZubyMusic
The incidence of pronouns in social media bios and email signatures is down at least 70% since the peak in 2020.
English
@katieporterca Stop taking your life's failures out on others.
English

I’m Katie Porter and I approve this message.
Fox News@FoxNews
“Yes!” Democrat Katie Porter enthusiastically said she supports taxpayer-funded healthcare for illegal immigrants during a California gubernatorial primary debate. The former congresswoman insisting that restoring that coverage to undocumented migrants is “what Californians deserve.” Porter gained momentum in the polls after frontrunner and fellow Democrat Eric Swalwell suspended his campaign following a number of sexual misconduct allegations.
English
@privetavdey irritating way to select something that I'd like to toggle quickly
English


And now it's time to see what my little brother has been working on for the past couple years: An AI model fully built on sub-quadratic sparse-attention architecture.
Result?
12 million token reasoning model
150 tokens/second
1/5 the cost of Opus
Alexander Whedon@alex_whedon
Introducing SubQ - a major breakthrough in LLM intelligence. It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA), And the first frontier model with a 12 million token context window which is: - 52x faster than FlashAttention at 1MM tokens - Less than 5% the cost of Opus Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention). Only a small fraction actually matter. @subquadratic finds and focuses only on the ones that do. That's nearly 1,000x less compute and a new way for LLMs to scale.
English
@DanielMiessler Agree with this take.
This is all preliminary.
English

I don’t know how good this new 12 million context system is, or if it’s hype or whatever, but I think it definitely shows a point I’ve been making since 2023.
We really suck at everything.
- The chips are primitive
- The research and training and inference systems are primitive
- Our RL approaches are primitive
- We’ve barely started building harnesses
Everything we’re doing is massively inefficient right now.
And there are thousands of vectors for improvement.
And many of them are multiplicative.
Most people think we’re at like 88% of AI’s capabilities, and we’re pushing to hit 92% or eventually 97% or something.
Nah. This is us at .0003%
Everything we have is Punch Card AI.
And as the AI gets better it will reveal that it’s similar for our understanding of medicine, physics, chemistry, etc.
This barely even day 0. This is pre-history.
Alexander Whedon@alex_whedon
Introducing SubQ - a major breakthrough in LLM intelligence. It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA), And the first frontier model with a 12 million token context window which is: - 52x faster than FlashAttention at 1MM tokens - Less than 5% the cost of Opus Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention). Only a small fraction actually matter. @subquadratic finds and focuses only on the ones that do. That's nearly 1,000x less compute and a new way for LLMs to scale.
English
@alex_whedon You're giving Martin Shkreli a run for his money.
This is so obviously bs. You're telling me you beat OpenAI and Anthropic and Google at this breakthrough that is (checks notes) 1,000x less compute?
You're going to jail.
English

Introducing SubQ - a major breakthrough in LLM intelligence.
It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA),
And the first frontier model with a 12 million token context window which is:
- 52x faster than FlashAttention at 1MM tokens
- Less than 5% the cost of Opus
Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention).
Only a small fraction actually matter.
@subquadratic finds and focuses only on the ones that do.
That's nearly 1,000x less compute and a new way for LLMs to scale.
English
@daniel_mac8 Transparently Theranos.
If they had this, they would be releasing it and blowing peoples minds.
English

SubQ is either the biggest breakthrough since the Transformer...
> 52x faster than FlashAttention at 1mm tok context
> 20x cheaper than Opus
...or it's AI Theranos.
Requested early access so hopefully can investigate soon.

Alexander Whedon@alex_whedon
Introducing SubQ - a major breakthrough in LLM intelligence. It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA), And the first frontier model with a 12 million token context window which is: - 52x faster than FlashAttention at 1MM tokens - Less than 5% the cost of Opus Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention). Only a small fraction actually matter. @subquadratic finds and focuses only on the ones that do. That's nearly 1,000x less compute and a new way for LLMs to scale.
English