
Mark
290 posts
Mark
@_M_Weber
PhD student at the Dynamic Vision and Learning Group, and the Computer Vision Group, TU Munich; Computer Vision research
Katılım Kasım 2020
313 Takip Edilen363 Takipçiler

➡️ For workshop specifics, including the evaluation package, baseline code, and more, visit: motchallenge.net/workshops/bmtt…
➡️ Eval server (sign-up now!): codabench.org/competitions/9…
#ICCV2025
English
Exciting news! We're happy to announce our challenge / workshop at this year @ICCVConference focusing on Spatiotemporal Action Grounding in Videos. Here are the details:
🔷 Watch the video below for a demo.
🔷 The eval server is open until 09/19!
🔷 Links incl. code below.
#ICCV

English
Mark retweetledi

🎯 Challenge Launch Announcement
We are pleased to announce the launch of the MOT25 Challenge, to be held in conjunction with ICCV 2025.
🔗 Workshop website:
motchallenge.net/workshops/bmtt…
🧪 The MOT25 Challenge is now live on Codabench:
codabench.org/competitions/9…
English
@KyleSargentAI Also, if you ever figure out why someone established that gFID is measured against the train (!) set statistics, while rFID is measured against Val set statistics, let me know!
Soo what alternative can we use on ImageNet?
English

The untainted NeurIPS 2024 best paper finalist VAR actually made a great point, which is that ImageNet val set gets 1.78 gFID -on ImageNet-
Basically a superior gFID means you did better than an optimal sample of 50k images. Good job goodharting your eval metrics I guess?
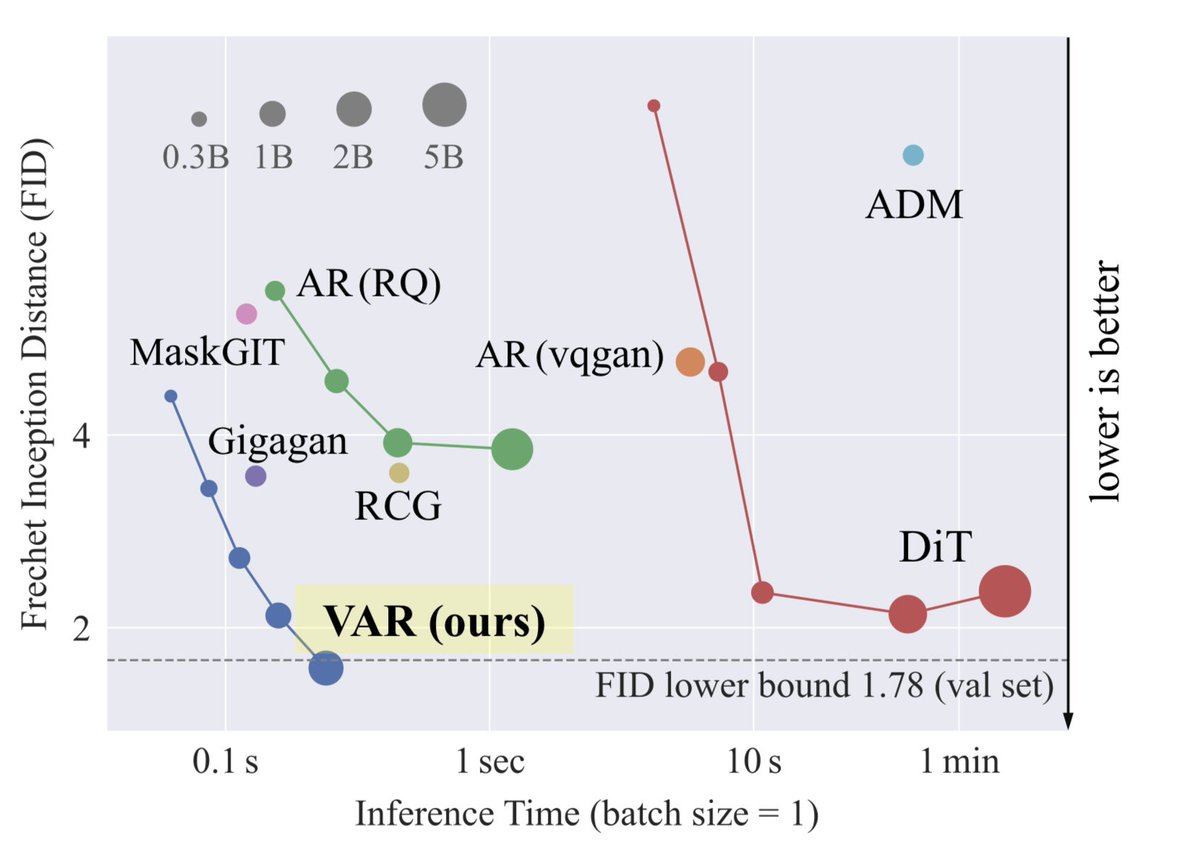
English

@drscotthawley Ohh thank you so much! I appreciate that. Hopefully there will be another time to chat at some point.
English

@_M_Weber So bummed to have missed this, only seeing it now! Would have loved to connect at ICLR, instead I'll just read the paper. Lack of resources re. training "a modern VQGAN" - I've been feeling that for months! Will add your work to upcoming IJCNN tutorial on practical latent gen.
English
Heading off to ICLR to present our work on image generation and latent spaces! If you're interested in tokenization or generation drop by at our poster.
Also, if you'd like to chat about any of these topics, feel free to ping me! #ICLR2025
Mark@_M_Weber
🧵1/9 Happy to share our paper "MaskBit: Embedding-free Image Generation via Bit Tokens" got published in TMLR with featured (aka spotlight) & reproducibility certifications! I'm especially excited about the disentangled visual concepts in our shared latent space. Details below!
English
Mark retweetledi

A beautiful article by D. Graham Burnett
newyorker.com/culture/the-we…
´The A.I. is huge. A tsunami. But it’s not me. It can’t touch my me-ness. It doesn’t know what it is to be human, to be me.’
‘Historians have long extolled the “power of the archive.” Little did we know that the engineers would come along and plug it in. And it turns out that a huge amount of what we seek from a human person can be simulated through this Frankensteinian reanimation of our collective dead letters.’
Thanks for sharing @mustafasuleyman

English
@sedielem The disentangled latent space then allows us to directly train the generator network taking the latent bit tokens as input, in contrast to learning a new vocabulary. We found this unified representation to be very efficient and strong for generation.
arxiv.org/pdf/2409.16211
English
@sedielem Thanks for the great post! In our study about training VQGANs, we made an observation that might be of interest to you and your readers.
When using LFQ, our tokenizer is able to model certain visual properties (like exposure, smoothness, color palette) into different channels.

English

New blog post: let's talk about latents!
sander.ai/2025/04/15/lat…
English

Have you ever been bothered by the constraints of fixed-sized 2D-grid tokenizers? We present FlexTok, a flexible-length 1D tokenizer that enables autoregressive models to describe images in a coarse-to-fine manner.
flextok.epfl.ch
arxiv.org/abs/2502.13967
🧵 1/n

English

After 6+ months in the making and burning over a year of GPU compute time, we're super excited to finally release the "Ultra-Scale Playbook"
Check it out here: hf.co/spaces/nanotro…
A free, open-source, book to learn everything about 5D parallelism, ZeRO, fast CUDA kernels, how and why overlap compute & communication – all scaling bottlenecks and tools introduced with motivation, theory, interactive plots from our 4000+ scaling experiments and even NotebookLM podcasters to tag along with you.
- How was DeepSeek trained for $5M only?
- Why did Mistral trained an MoE?
- Why is PyTorch native Data Parallelism implementation so complex under the hood?
- What are all the parallelism techniques and why were they invented?
- Should I use ZeRO-3 or Pipeline Parallelism when scaling and what's the story behind both techniques?
- What is this Context Parallelism that Meta used to train Llama 3? Is it different from Sequence Parallelism?
- What is FP8? how does it compares to BF16?
In this book, our goal was to gather, in a single place, a coherent, easy to read yet detailed story of all the techniques that make today's LLM scaling possible.
The largest factor for democratizing AI will always be teaching everyone how to build AI and in particular how to create, train and fine-tune high performance models. In other word making accessible to everybody the techniques that power all recent large language models and efficient training is possibly one of the most essential of them.
What started as a simple blog-post ended up becoming an interactive writing piece containing 30k+ words. So we've decided to actually print it as a real 100-pages physical book as well: the physical ultrafast playbook –containing all the science of distributed and fast AI training.
We plan to send free copies as gifts to the first readers of the online version so feel free to add your email in the form linked in the blog post.

English
Mark retweetledi

Our exclusive with @JDVance ahead of @MunSecConf: -On Ukraine, he says there will be a good peace deal that will guarantee the country’s long-term sovereignty - and Putin will face sanctions and military measures if he doesn’t play ball.
-On Europe, he will tell mainstream leaders in Munich that they’ve become Soviet-style enemies of free speech and democracy who ignore voters and fail to stop mass migration. Some Germans will be particularly shocked when he calls for ending the firewall against the far-Right @AfD and embracing the populist vote.
With @alexbward via @WSJ wsj.com/world/europe/v…
English
Mark retweetledi

Everything you love about generative models — now powered by real physics!
Announcing the Genesis project — after a 24-month large-scale research collaboration involving over 20 research labs — a generative physics engine able to generate 4D dynamical worlds powered by a physics simulation platform designed for general-purpose robotics and physical AI applications.
Genesis's physics engine is developed in pure Python, while being 10-80x faster than existing GPU-accelerated stacks like Isaac Gym and MJX. It delivers a simulation speed ~430,000 faster than in real-time, and takes only 26 seconds to train a robotic locomotion policy transferrable to the real world on a single RTX4090 (see tutorial: genesis-world.readthedocs.io/en/latest/user…).
The Genesis physics engine and simulation platform is fully open source at github.com/Genesis-Embodi…. We'll gradually roll out access to our generative framework in the near future.
Genesis implements a unified simulation framework all from scratch, integrating a wide spectrum of state-of-the-art physics solvers, allowing simulation of the whole physical world in a virtual realm with the highest realism.
We aim to build a universal data engine that leverages an upper-level generative framework to autonomously create physical worlds, together with various modes of data, including environments, camera motions, robotic task proposals, reward functions, robot policies, character motions, fully interactive 3D scenes, open-world articulated assets, and more, aiming towards fully automated data generation for robotics, physical AI and other applications.
Open Source Code: github.com/Genesis-Embodi…
Project webpage: genesis-embodied-ai.github.io
Documentation: genesis-world.readthedocs.io
1/n
English
9/9 If you like this research and are hiring, I will be on the job market next summer!
Big thanks to my collaborators: @yucornetto1 @xueqingdeng77 @lcchen_jay @tumcvg @LijunYu0
English
8/9
Project page: weber-mark.github.io/projects/maskb…
Paper: arxiv.org/pdf/2409.16211
Code: github.com/markweberdev/m…
English