ett0re retweetledi
ett0re
722 posts



ett0re retweetledi

He dropped out of Harvard. He got scolded at Microsoft. And then Built a platform that owns 75% of all PC gaming. 🤯
>Meet Gabe Newell.
> Born in Colorado. Grew up in Davis, California.
> Got into Harvard. One of the hardest things to do on earth.
> Dropped out anyway.
> Was just hanging around his brother's Microsoft office one day.
> Steve Ballmer caught him doing nothing.
> Said "Be useful or leave."
> He stayed. Got a job on the spot. 💀
> Became producer of the first two versions of Windows.
> Sat at the centre of the biggest tech revolution in history.
> Spent 13 years at Microsoft. Became a millionaire.
> Then noticed something that broke his brain.
> Doom — a video game — was installed on more computers than Windows 95.
> The thing he had spent years of his life building.
> A game was beating his operating system.
> Realized the future wasn't software. It was games.
> On his wedding day in 1996 — co-founded Valve. 🚀
> Poured his own Microsoft millions into it.
> No safety net. Just belief.
> First game — Half-Life. 1998.
> Critics called it a masterpiece. Changed gaming forever.
> Then came Counter-Strike. Portal. Left 4 Dead. DOTA 2.
> But the real weapon was still coming.
> In 2003 — launched Steam.
> Gamers hated it at first. Called it DRM. Bloatware. Forced install.
> He didn't budge. Kept building. 💀
> Added automatic updates. Cloud saves. Friends lists.
> Then launched the Steam Sale.
> The internet went insane. Every single time.
> By 2011 — Steam controlled most of the downloaded PC games market.
> Today — 132 million active users.
> 50,000+ games in the library.
> Takes 30% cut from every sale.
> Valve has never gone public. Never raised funding. Never answered to anyone.
> Net worth estimated at $9.5 billion.
> Still refuses a corporate title. No CEO energy. Just "Gabe."
> Employees pick their own projects. No managers. No hierarchy.
> And Half-Life 3?
> Still not out. Probably never will be. That's just how he rolls. 💀
> Said "I was willing to put my money where my mouth was."
> Harvard rejected. Microsoft trained him. Gaming bowed to him.
Absolute GOAT 🔥🐐


English
ett0re retweetledi

If you love computers, you'll love this book. Trust me.
It includes exciting plot twists like "We're out of bits but need to add a new instruction", and then a bunch of "navigating to the moon" stuff. But it's great.
mrdoornbos@mrdoornbos
I love pretty much every pre-1990 computer ever made. But my favorite by a long shot is the Apollo AGC. This is my second time through this book.
English
ett0re retweetledi

ett0re retweetledi

ett0re retweetledi

That’s gangsta!
Half a mil earned securing the space.
Refreshing to see good news in security for once 👏
Cantina 🪐@cantinasecurity
$500,000 to @rileyholterhus through Cantina Bounties. 🪐 The researchers who consistently find the bugs that matter don't chase volume. They follow programs where scope is tight, triage is fast, and rewards match actual impact. Well done, Riley!
English
ett0re retweetledi

ett0re retweetledi

New blog post on reverse engineering and modifying HDD firmware. In this part I cover obtaining, analyzing, and modifying firmware, using backdoor commands to hot patch code in RAM, and using JTAG to debug a live HDD icode4.coffee/?p=1465
English
ett0re retweetledi

At just 18, Ewin Tang (now at UC Berkeley) developed a groundbreaking classical algorithm for recommendation systems (the "Netflix problem") that matched the performance of a leading quantum algorithm; challenging assumptions about quantum advantage and sparking the field of quantum-inspired classical algorithms.
Her recent work continues to bridge classical & quantum computing: dequantizing ML/linear algebra algorithms and advancing quantum machine learning on quantum data. In 2025, she became the youngest winner of the Maryam Mirzakhani New Frontiers Prize; a powerful inspiration for emerging young minds in STEM!

English
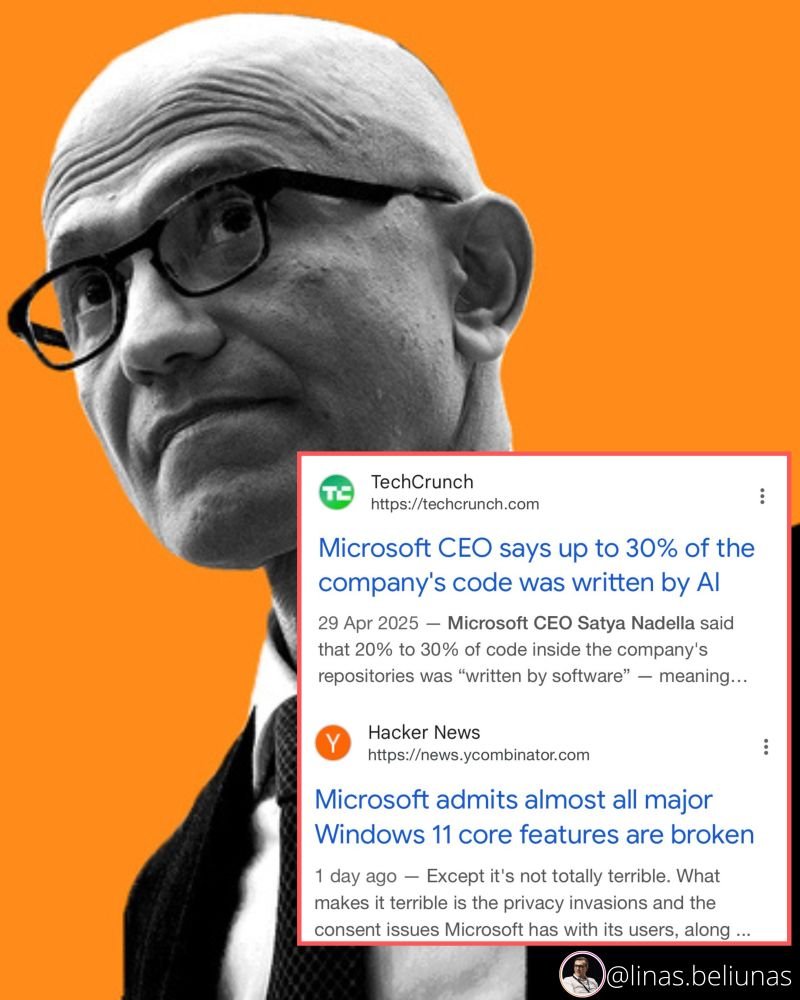
ett0re retweetledi

Thanks to WINE, Proton, and Valve's hardware, a significant milestone has been achieved with 90% of Windows games running on Linux, making nine out of ten Windows games accessible on a new Linux installation.

English
ett0re retweetledi



Most PhD students struggle with academic writing. Their research is solid but writing doesn't reflect expertise.
Harvard College Writing Center created a FREE 33-page comprehensive guide.
Same writing system that trains future leaders. Zero cost.

English

Hi @X
I'm looking to Connect with people who are interested in:
🔒 Cybersecurity
🕵️♂️ Ethical Hacking
🔐 Network Security
🛡️ Penetration Testing
📊 Security Analytics
👨💻 Cyber Forensics
📚 Cybersecurity Research
🚨 Risk Management
🧑💻 Secure Coding
🪲Bug Bounty
Drop a hi and let’s connect
English


@digitalix check this out
EXO Labs@exolabs
Clustering NVIDIA DGX Spark + M3 Ultra Mac Studio for 4x faster LLM inference. DGX Spark: 128GB @ 273GB/s, 100 TFLOPS (fp16), $3,999 M3 Ultra: 256GB @ 819GB/s, 26 TFLOPS (fp16), $5,599 The DGX Spark has 3x less memory bandwidth than the M3 Ultra but 4x more FLOPS. By running compute-bound prefill on the DGX Spark, memory-bound decode on the M3 Ultra, and streaming the KV cache over 10GbE, we are able to get the best of both hardware with massive speedups. Short explanation in this thread & link to full blog post below.
English
Great review @NetworkChuck! shows that marketing and engineering don’t always speak the same language at Nvidia
NetworkChuck@NetworkChuck
It seems like local AI is becoming mainstream and I'm super excited!! I just reviewed the Nvidia DGX Spark but I really want to pin it against a Mac Studio and a @FrameworkPuter AI machine. Would ya'll watch that?
English
ett0re retweetledi

Excited to release new repo: nanochat!
(it's among the most unhinged I've written).
Unlike my earlier similar repo nanoGPT which only covered pretraining, nanochat is a minimal, from scratch, full-stack training/inference pipeline of a simple ChatGPT clone in a single, dependency-minimal codebase. You boot up a cloud GPU box, run a single script and in as little as 4 hours later you can talk to your own LLM in a ChatGPT-like web UI.
It weighs ~8,000 lines of imo quite clean code to:
- Train the tokenizer using a new Rust implementation
- Pretrain a Transformer LLM on FineWeb, evaluate CORE score across a number of metrics
- Midtrain on user-assistant conversations from SmolTalk, multiple choice questions, tool use.
- SFT, evaluate the chat model on world knowledge multiple choice (ARC-E/C, MMLU), math (GSM8K), code (HumanEval)
- RL the model optionally on GSM8K with "GRPO"
- Efficient inference the model in an Engine with KV cache, simple prefill/decode, tool use (Python interpreter in a lightweight sandbox), talk to it over CLI or ChatGPT-like WebUI.
- Write a single markdown report card, summarizing and gamifying the whole thing.
Even for as low as ~$100 in cost (~4 hours on an 8XH100 node), you can train a little ChatGPT clone that you can kind of talk to, and which can write stories/poems, answer simple questions. About ~12 hours surpasses GPT-2 CORE metric. As you further scale up towards ~$1000 (~41.6 hours of training), it quickly becomes a lot more coherent and can solve simple math/code problems and take multiple choice tests. E.g. a depth 30 model trained for 24 hours (this is about equal to FLOPs of GPT-3 Small 125M and 1/1000th of GPT-3) gets into 40s on MMLU and 70s on ARC-Easy, 20s on GSM8K, etc.
My goal is to get the full "strong baseline" stack into one cohesive, minimal, readable, hackable, maximally forkable repo. nanochat will be the capstone project of LLM101n (which is still being developed). I think it also has potential to grow into a research harness, or a benchmark, similar to nanoGPT before it. It is by no means finished, tuned or optimized (actually I think there's likely quite a bit of low-hanging fruit), but I think it's at a place where the overall skeleton is ok enough that it can go up on GitHub where all the parts of it can be improved.
Link to repo and a detailed walkthrough of the nanochat speedrun is in the reply.

English

🟢 GEFORCE DAY IS BACK 🟢
To celebrate, we're giving away TWO GeForce RTX 5080 Founders Edition GPUs, signed by NVIDIA CEO Jensen Huang.
Want one? Comment "GeForce Day" for a chance to WIN & stay tuned for more!

English