Kevin Lu retweetledi

Grateful to Jensen and @nvidia team for their support. Together, we’re working to deploy at least 1GW of Vera Rubin systems, bringing adaptable collaborative AI to everyone.
thinkingmachines.ai/nvidia-partner…

English
Kevin Lu
72 posts


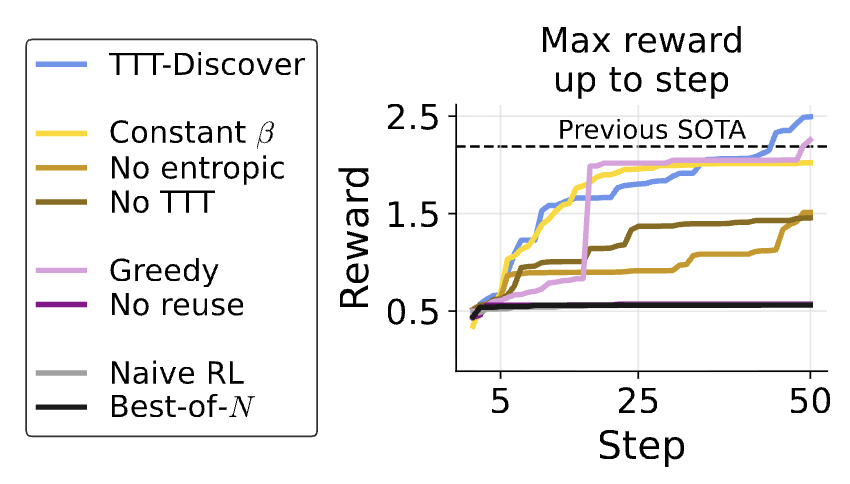
How to get AI to make discoveries on open scientific problems? Most methods just improve the prompt with more attempts. But the AI itself doesn't improve. With test-time training, AI can continue to learn on the problem it’s trying to solve: test-time-training.github.io/discover.pdf

Tinker is now generally available. We also added support for advanced vision input models, Kimi K2 Thinking, and a simpler way to sample from models. thinkingmachines.ai/blog/tinker-ge…











Starting Monday, November 3rd, Tinker is switching to a pricing plan that reflects compute usage. This will ensure we have sufficient capacity to clear our waitlist by the end of the year, allowing anyone to sign up and start Tinkering. tinker-console.thinkingmachines.ai/rate-card


Our latest post explores on-policy distillation, a training approach that unites the error-correcting relevance of RL with the reward density of SFT. When training it for math reasoning and as an internal chat assistant, we find that on-policy distillation can outperform other approaches for a fraction of the cost. thinkingmachines.ai/blog/on-policy…


Our latest post explores on-policy distillation, a training approach that unites the error-correcting relevance of RL with the reward density of SFT. When training it for math reasoning and as an internal chat assistant, we find that on-policy distillation can outperform other approaches for a fraction of the cost. thinkingmachines.ai/blog/on-policy…




For agents to improve over time, they can’t afford to forget what they’ve already mastered. We found that supervised fine-tuning forgets more than RL when training on a new task! Want to find out why? 👇