Sabitlenmiş Tweet

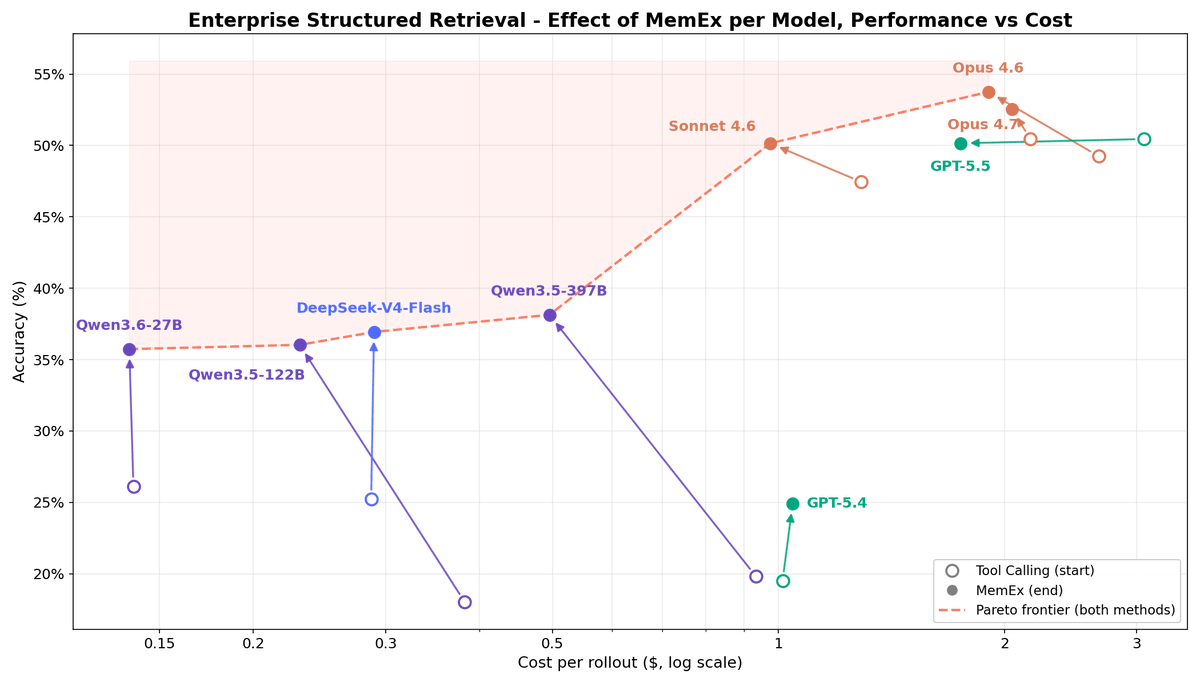
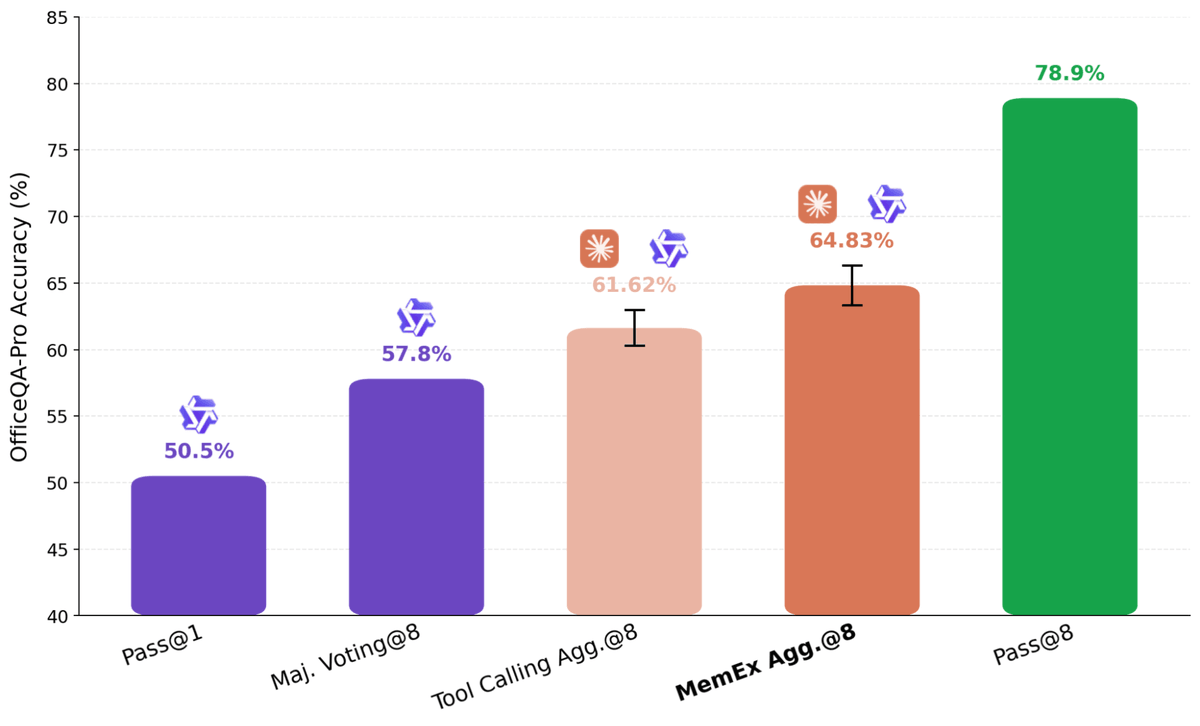
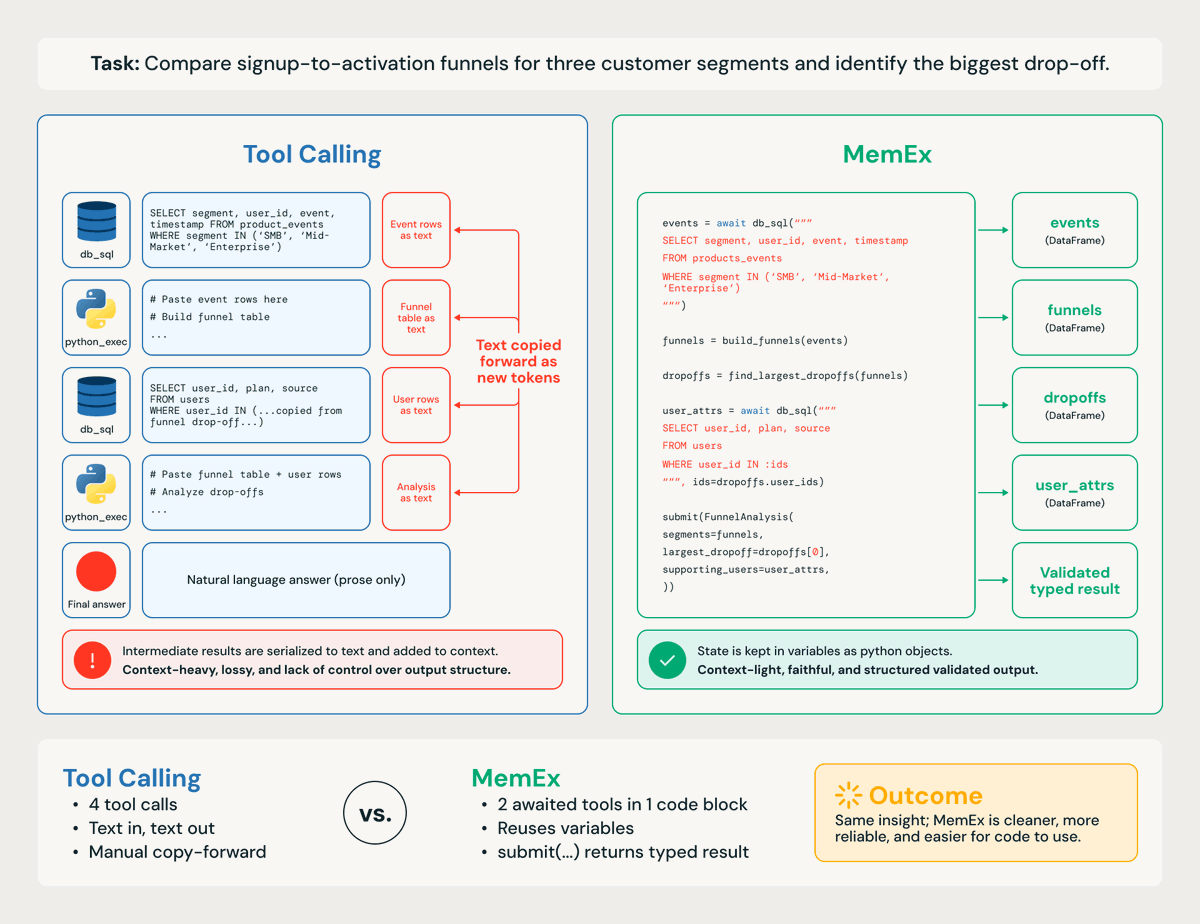
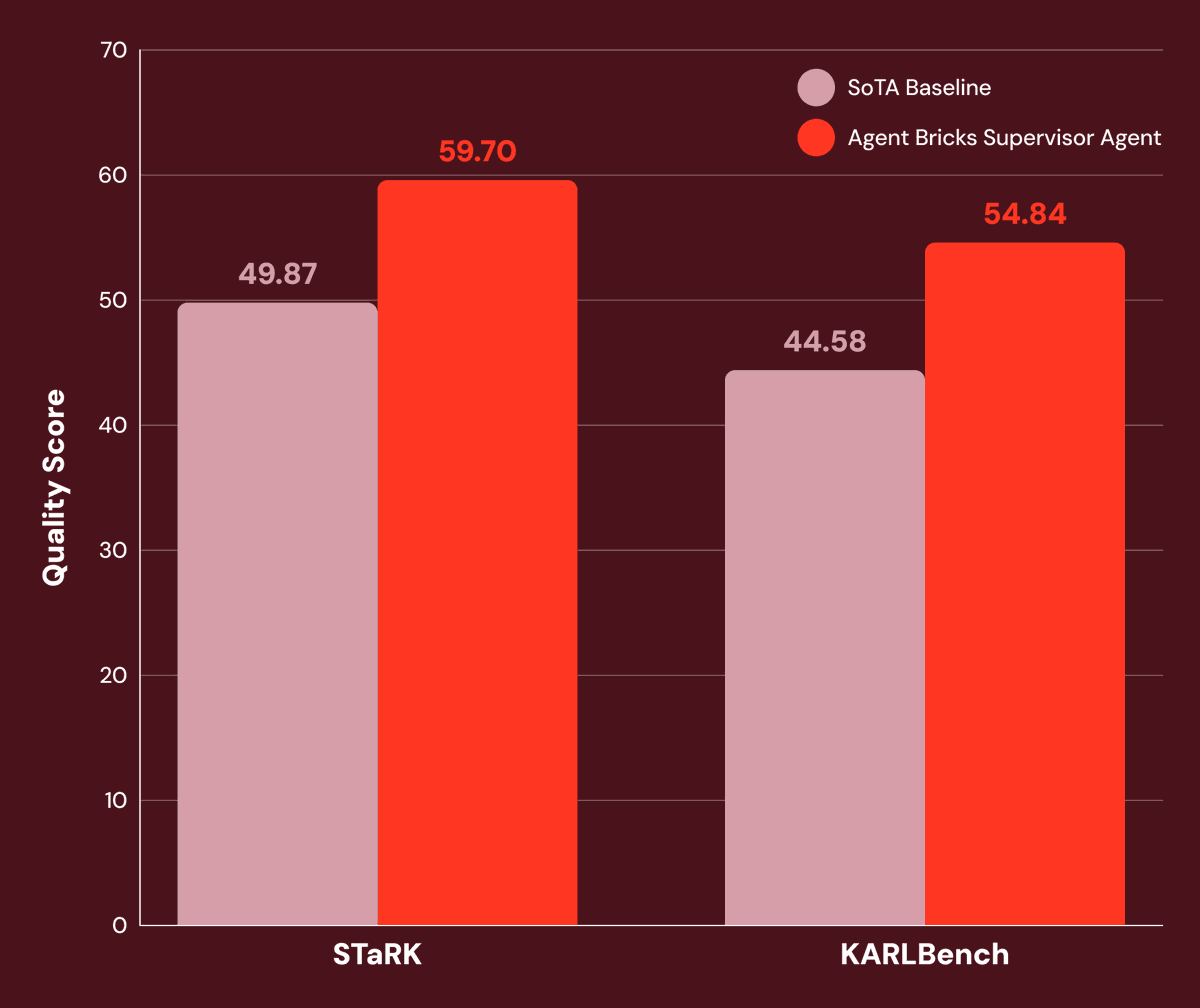
In 1945, Vannevar Bush imagined a machine to extend a scientist's memory. He called it the MemEx.
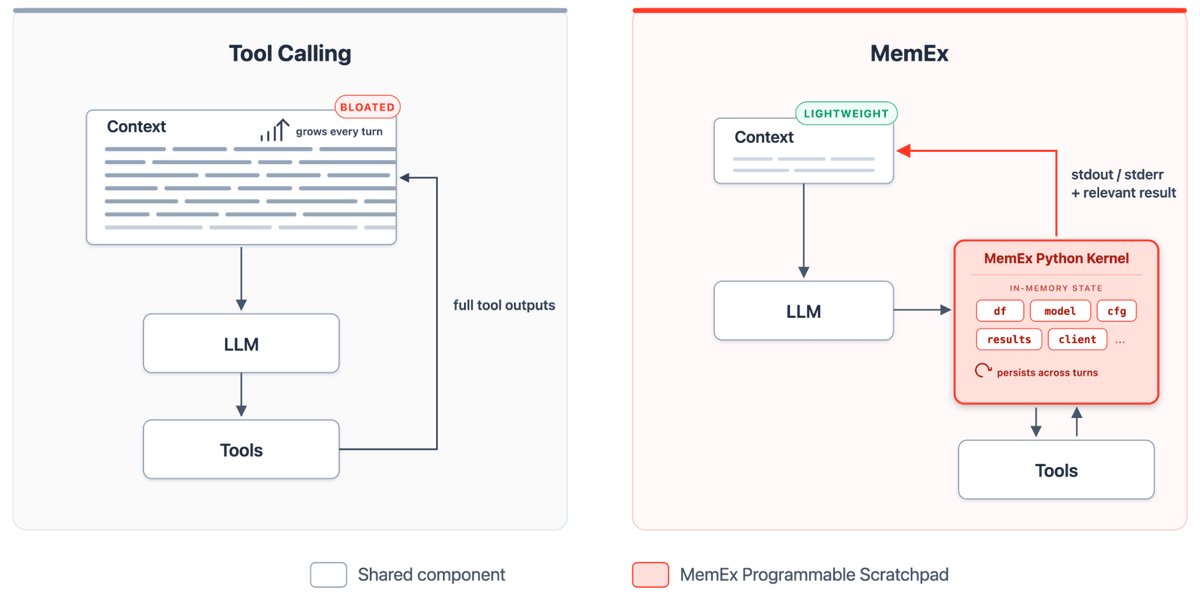
80 years later, we built one for LLM agents.
Tool outputs become Python objects; only print statements reach the model's context.
🧵 databricks.com/blog/memex-pro…
English