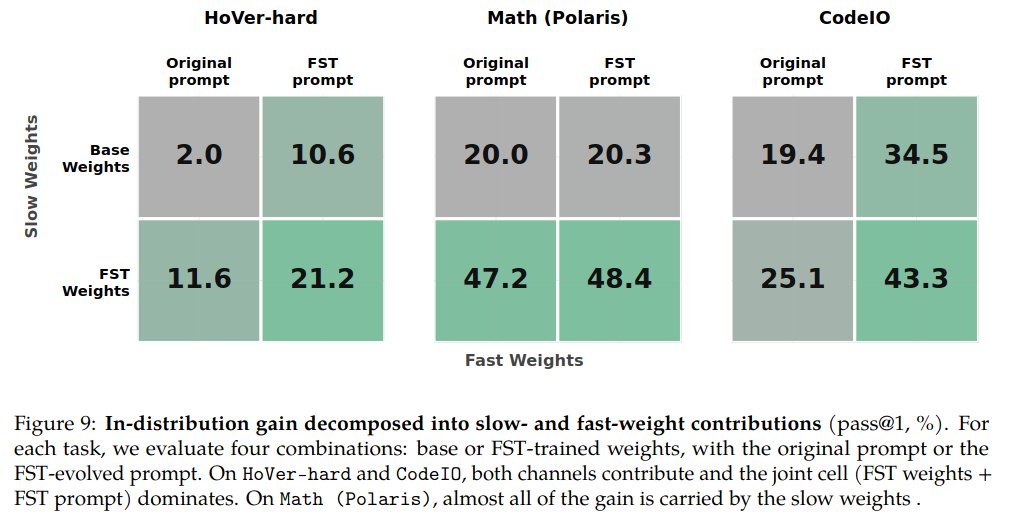
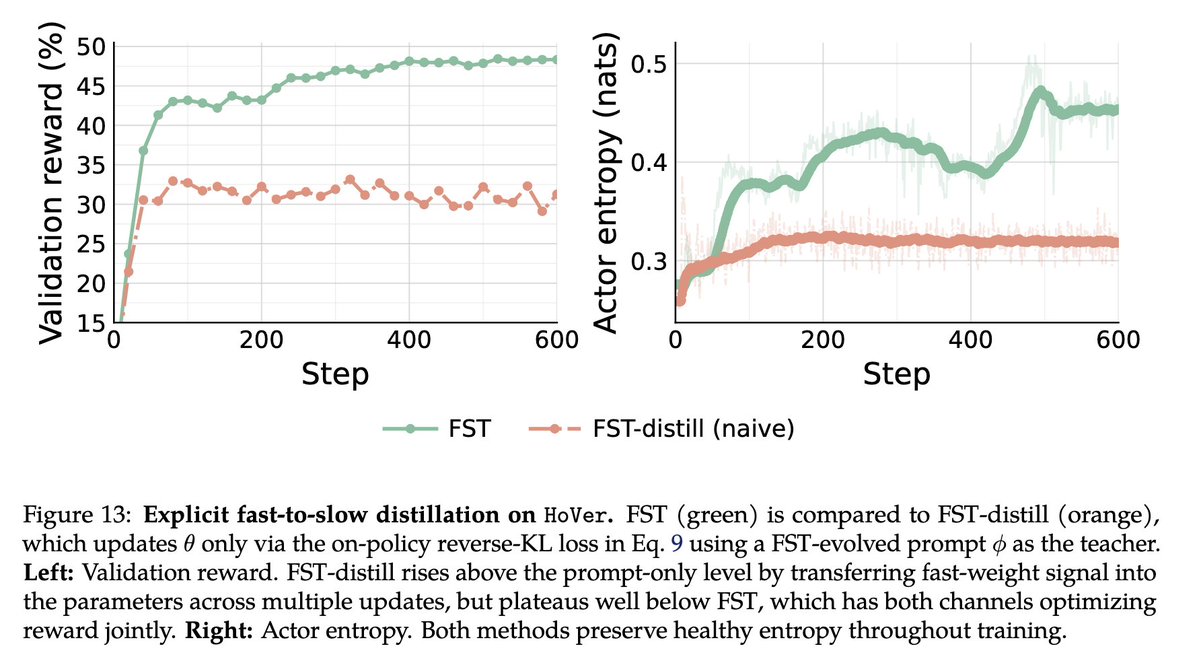
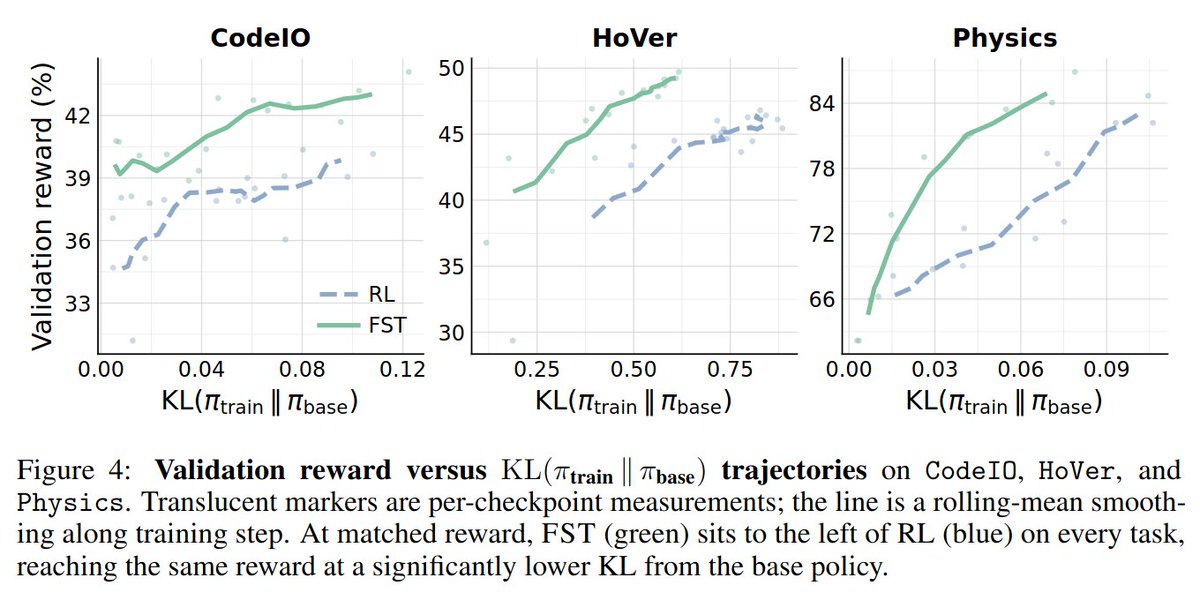
Sabitlenmiş Tweet

Can LLMs adapt continually without losing base skills?
Fast-Slow Training (FST) pairs "slow" weights with "fast" context.
FST vs. RL:
• 3x more sample-efficient
• Higher performance ceiling
• Less KL drift (better plasticity)
• Continual learning: succeeds where RL stalls

English