Sabitlenmiş Tweet

nvfp4 moe on b200: the 142 tflops gap
benchmarked gpt-oss-20b (64e, topk=4) nvfp4 kernels.
sglang hits 1168 tflops peak.
vllm tops out at 1026 tflops.
same hardware. same model. different kernels.
dive in⬇️

English
Konstantin
101 posts





Introducing Qwen3.6-Plus from @Alibaba_Qwen, a 1M-context model built for real-world agents, agentic coding, and multimodal reasoning. AI natives can now use Qwen3.6-Plus on Together AI and benefit from reliable inference for production-scale agent workflows.

🚀 Introducing FlashQLA: high-performance linear attention kernels built on TileLang. ⚡ 2–3× forward speedup. 2× backward speedup. 💻 Purpose-built for agentic AI on your personal devices. 💡Key insights: 1. Gate-driven automatic intra-card CP. 2. Hardware-friendly algebraic reformulation. 3. TileLang fused warp-specialized kernels. FlashQLA boosts SM utilization via automatic intra-device CP. The gains are especially pronounced for TP setups, small models, and long-context workloads. Instead of fusing the entire GDN flow into a single kernel, we split it into two kernels optimized for CP and backward efficiency. At large batch sizes this incurs extra memory I/O overhead vs. a fully fused approach, but it delivers better real-world performance on edge devices and long-context workloads. The backward pass was the hardest part: we built a 16-stage warp-specialized pipeline under extremely tight on-chip memory constraints, ultimately achieving 2×+ kernel-level speedups. We hope this is useful to the community!🫶🫶 Learn more: 📖 Blog: qwen.ai/blog?id=flashq… 💻 Code: github.com/QwenLM/FlashQLA











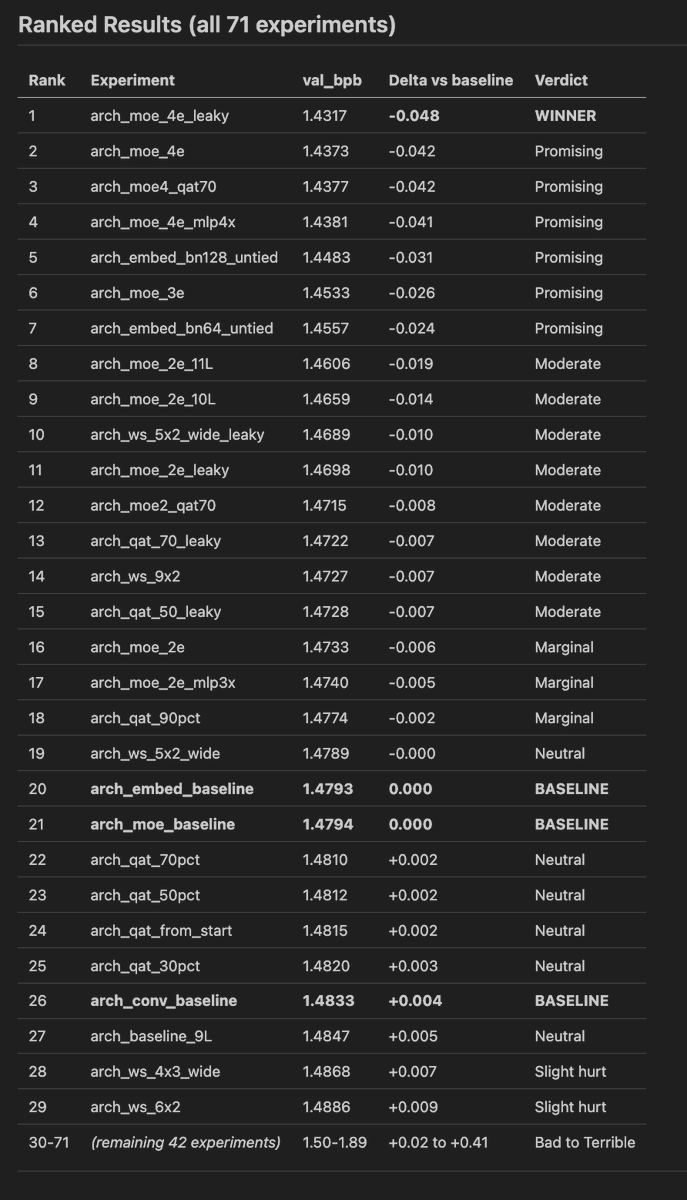
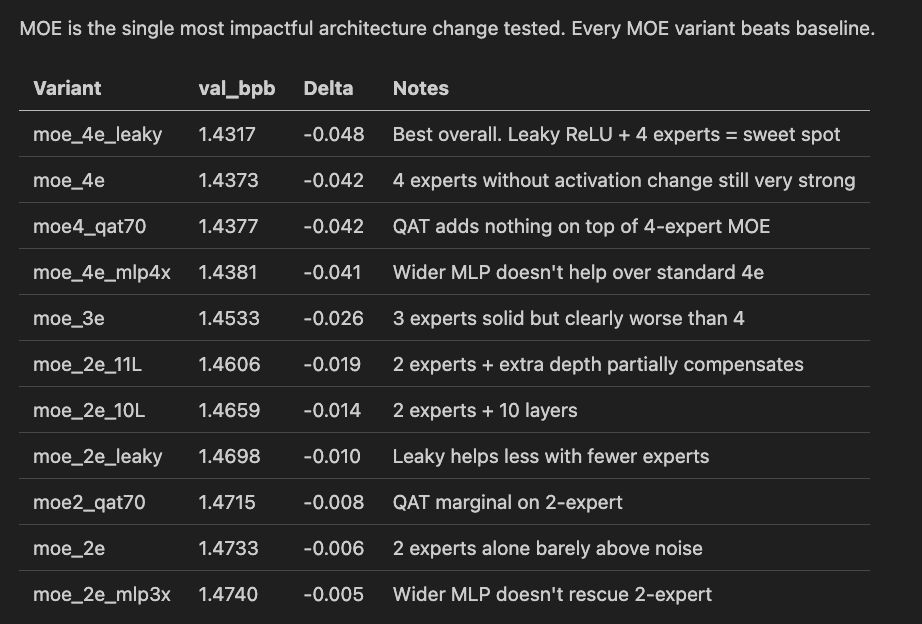
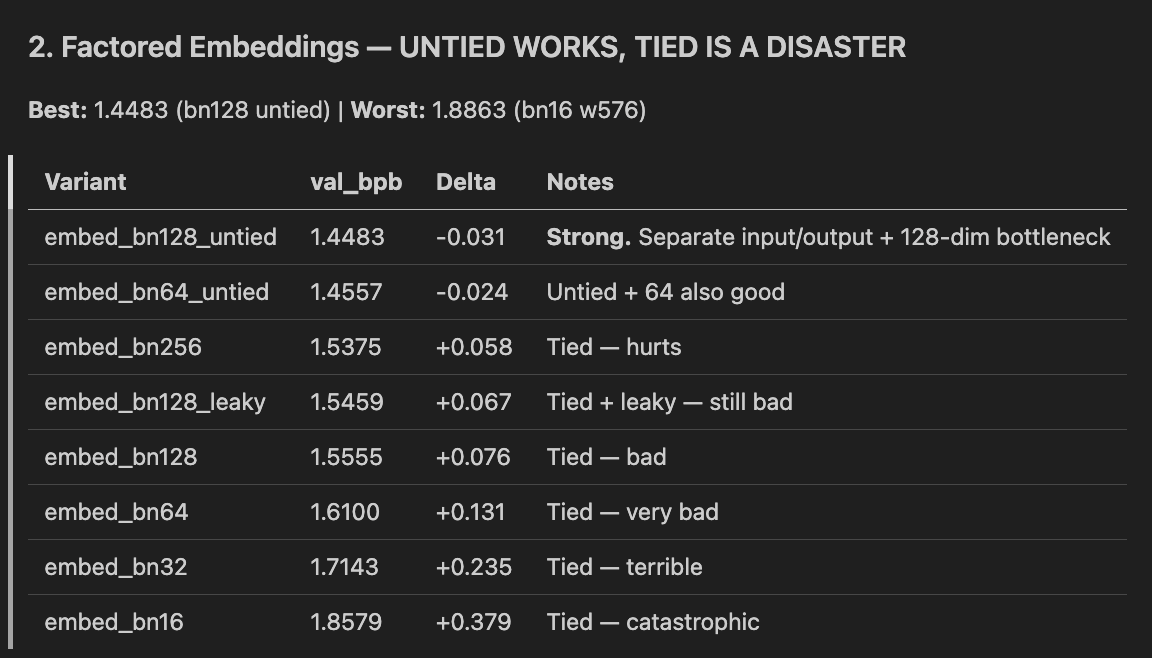
Are you up for a challenge? openai.com/parameter-golf


with our new GB300NVL72 training, not only is the codebase completely TP free it is now also completely nccl and nvshmem free . its a beautiful thing.