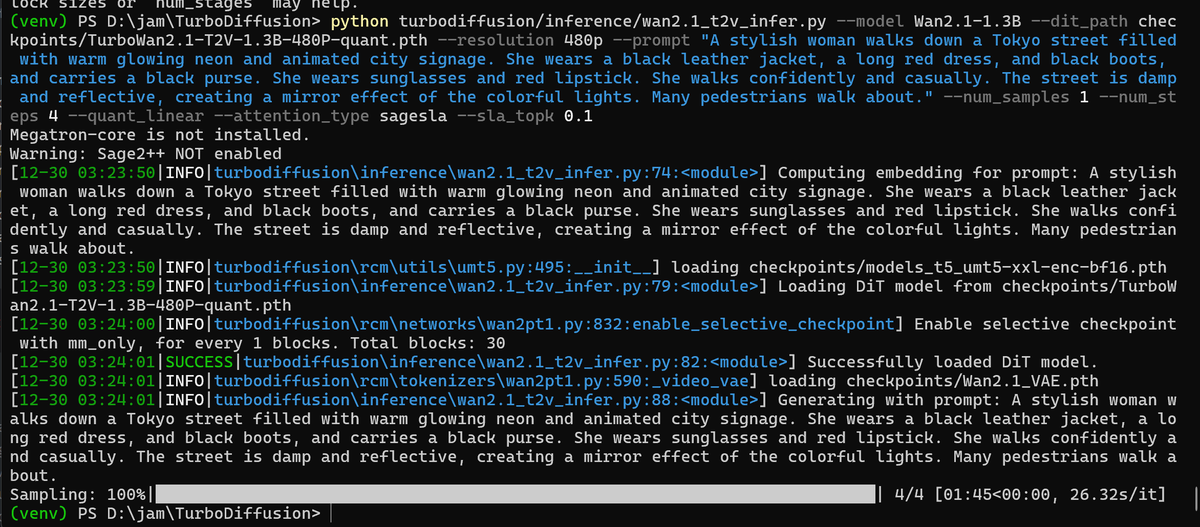
Sabitlenmiş Tweet

Super happy to see this :) all those late nights fixing and getting ROCm + PyTorch running on Strix Halo with @scottttw
on TheRock have finally paid off 🥲 x.com/AnushElangovan…
It's now ready and widely available. This is just the beginning, and we're just getting started!
Anush Elangovan@AnushElangovan
Local [Superintelligence + Supercomputing] + Signed by @LisaSu 💻 🚀🚀🚀 Ryzen AI Max+ PRO 395 (Strix Halo) with ROCm * runs GPT-OSS locally * runs Battlefied 6 like a desktop * 16x Zen5 cores for builds @sama @gdb Sarah As promised please tag me if you run into any issues 🤙
English