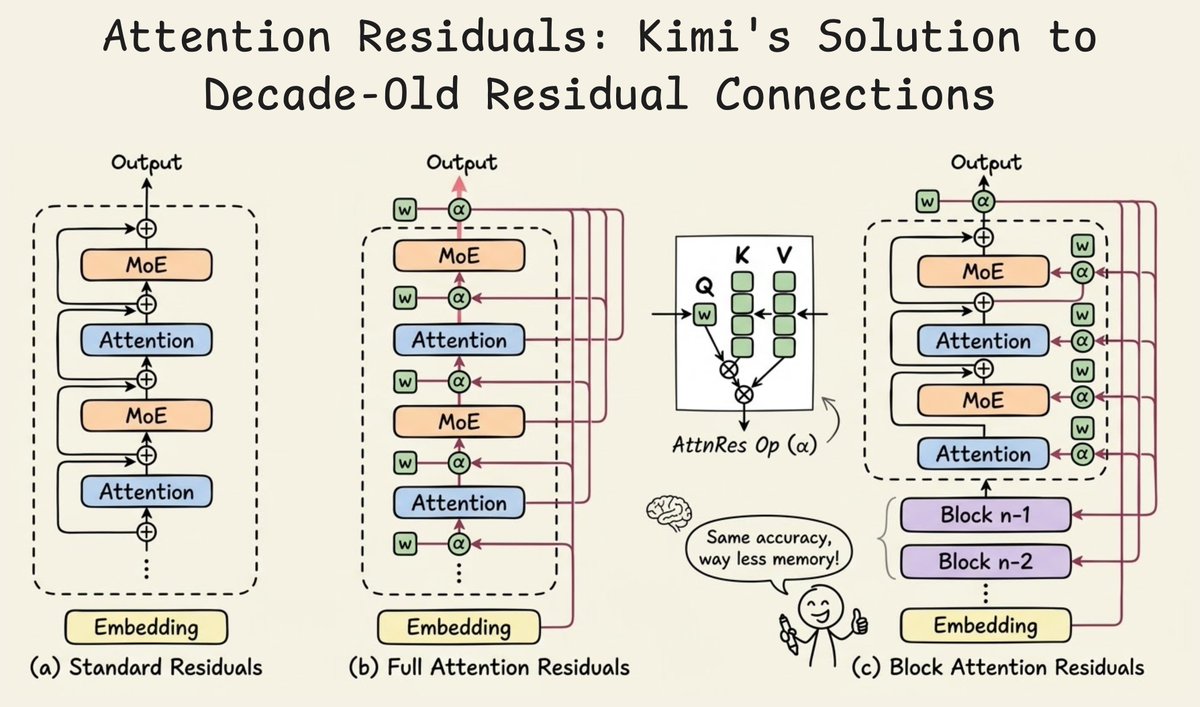
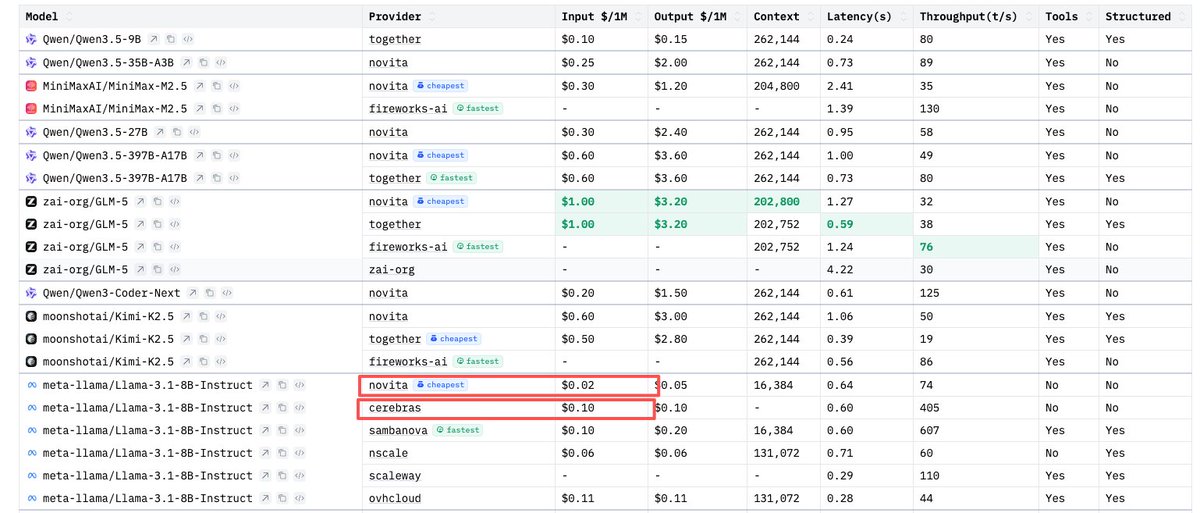
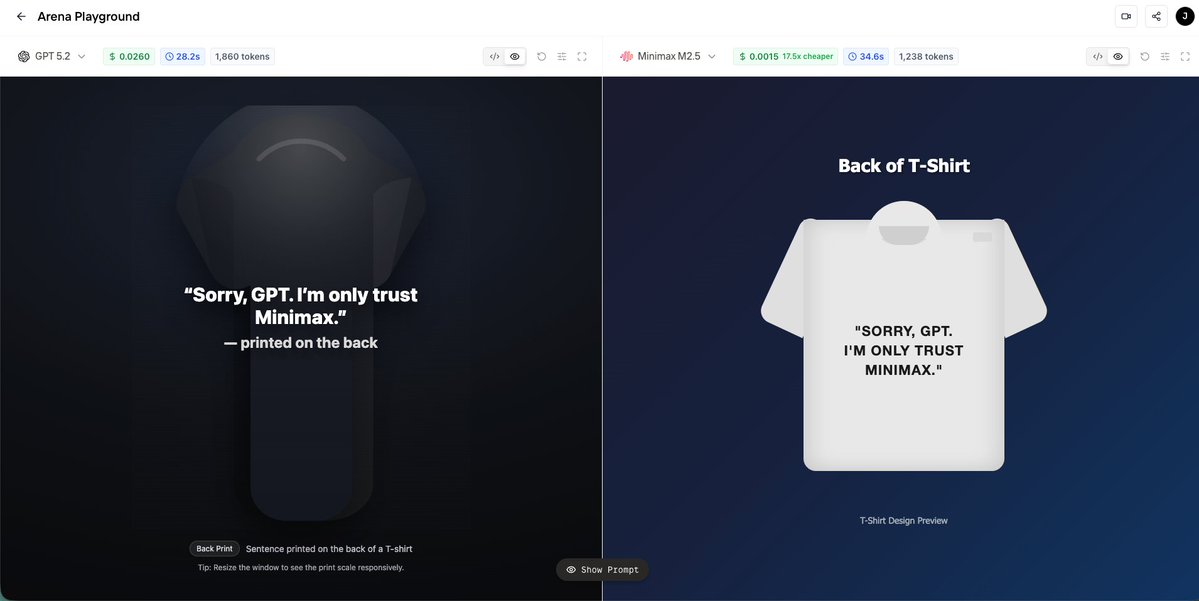
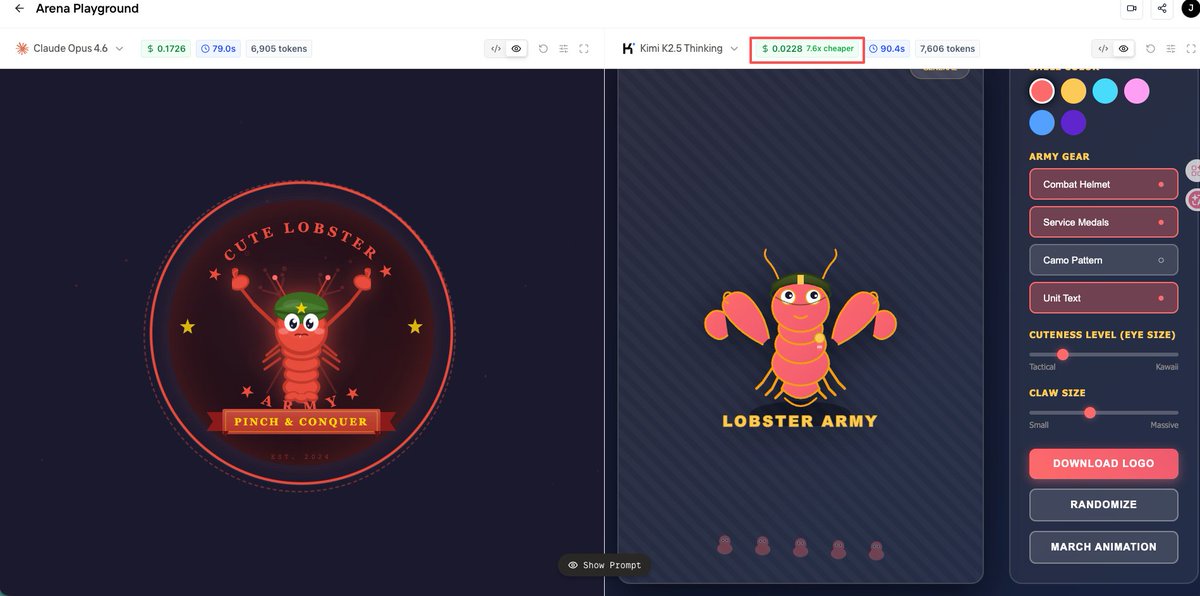
Sabitlenmiş Tweet

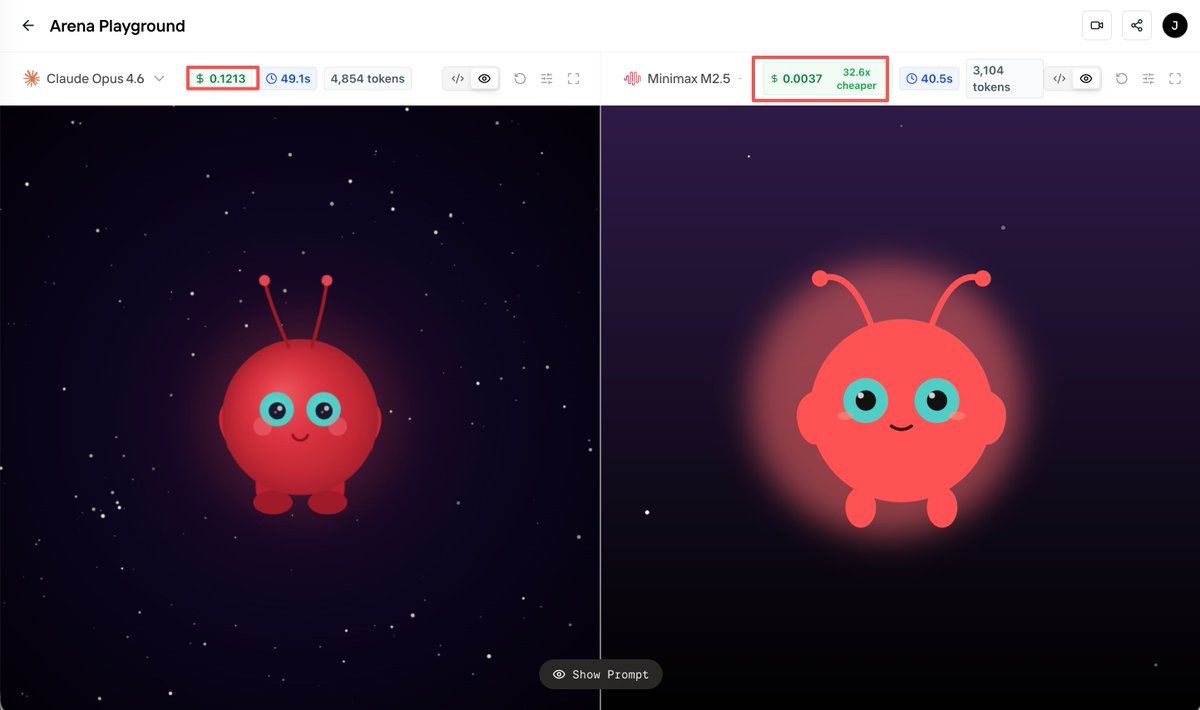
🚀 The gap between open-weights and proprietary coding assistants is officially closing.
We just ran a head-to-head benchmark in our Arena Playground @novita_labs :
• MiniMax M2.5 matches SOTA-level performance
• 32.6× cheaper — $0.0037 vs $0.1213
• Tested on real, production-style workloads
This feels like the “Infinite Scaling” moment for production builders.
@openclaw 🦀
If you were generating a logo right now — which model would you choose?
Happy coding 🛠️
English