Sabitlenmiş Tweet

I will be joining @RiceUniversity as a TTFA. Start to recruit Fall 2025, do email and DM if you’re interested! news.rice.edu/news/2025/comp…
English
Linna An
118 posts

@alchemist_an
TTAP @RiceUniversity | computational biochemist | Protein designer @UWproteindesign & natural product biochemist @ChemistryUIUC | open to industry



Learning the All-Atom Equilibrium Distribution of Biomolecular Interactions at Scale 1 ByteDance AI Drug Discovery and Anew Therapeutics researchers introduce AnewSampling, the first generative foundation framework that faithfully reproduces molecular dynamics (MD) at the all-atom level for sampling the equilibrium distribution of biomolecular interactions, addressing the high computational cost of traditional MD simulations. 2 AnewSampling leverages a novel quotient-space generative framework to ensure mathematical consistency in its modeling, and is trained on AnewSamplingDB—the largest self-curated database of protein-ligand trajectories to date, containing over 15 million conformations across 10,297 unique protein sequences and 27,979 unique ligand SMILES. 3 The framework builds on an AlphaFold3-like architecture with a stratified hybrid fine-tuning strategy: Low-Rank Adaptation (LoRA) for sequence representation modules and full-parameter fine-tuning for the Diffusion Module, alongside a Cluster-Based Template Guidance mechanism to enforce exhaustive exploration of the equilibrium ensemble. 4 In benchmarking on the ATLAS monomer dataset, AnewSampling outperforms all state-of-the-art generative methods across all 13 evaluation metrics, showing unparalleled accuracy in predicting protein flexibility and distributional accuracy for monomeric systems. 5 For protein-ligand dynamics testing across held-out PDB systems, JACS & Merck industrial datasets and an in-house drug discovery pipeline dataset, AnewSampling achieves statistical alignment with ground-truth MD distributions that far surpasses static predictors and MD-enhanced models like Boltz2, with its generated conformations nearly indistinguishable from MD baselines in key metrics. 6 AnewSampling demonstrates emergent enhanced sampling capabilities beyond conventional MD, successfully navigating high energy barriers to recover coupled ligand and side-chain motions in CDK2 systems (1H1R and 1H1S)—a major challenge for traditional MD that often requires replica-exchange MD (REMD) to achieve. 7 The model accurately captures subtle ligand-induced conformational shifts in congeneric structure-activity relationship (SAR) series, a critical capability for lead optimization in drug discovery, and maintains high fidelity in modeling non-covalent protein-ligand interactions and global protein backbone dynamics across diverse chemical and conformational spaces. 8 The research team proposes a multi-level assessment strategy for generative biomolecular dynamics models, using metrics like Jensen-Shannon (JS) distance for ligand torsion, Wasserstein (WS) distance for protein-ligand interactions and Spearman correlation for Cα RMSF to rigorously validate physical fidelity at the atomic level. 9 AnewSampling offers unprecedented computational efficiency for exploring biomolecular conformational landscapes, enabling integration into research and industrial drug discovery pipelines and driving a shift toward dynamics-aware design of adaptive inhibitors and functional biomolecules. 10 While AnewSampling achieves significant advances, the researchers note current limitations including reliance on structural templates, limited training data for broader biomolecular interaction types (e.g., protein-nucleic acid) and restriction to fixed thermodynamic environments, outlining future work to address these and enable sequence-only equilibrium distribution prediction. 11 AnewSampling and conventional MD are shown to be complementary: MD provides the critical training data for the generative model, while AnewSampling can accelerate MD by generating diverse initial structural candidates that help bypass energy barriers in physical simulations. 📜Paper: biorxiv.org/content/10.648… #AIDrugDiscovery #BiomolecularDynamics #AllAtomModeling #GenerativeAI #ComputationalBiology #MolecularDynamics #ProteinLigandInteractions




We are launching ML4BioChem club to connect scientists through in-person/online seminars and happy hours to spark new collaborations, and beyond. Upcoming speakers 👉 : linnaan-lab.github.io/ML4BIOCHEM/ Subscribe @ `Email me about events` on website. Will add you to ml4biochem@rice.edu.





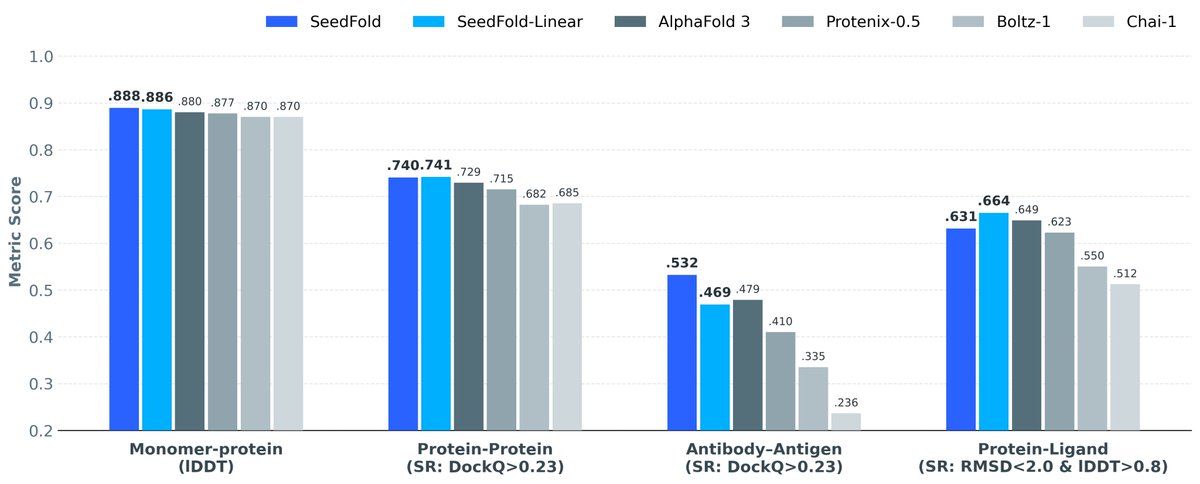

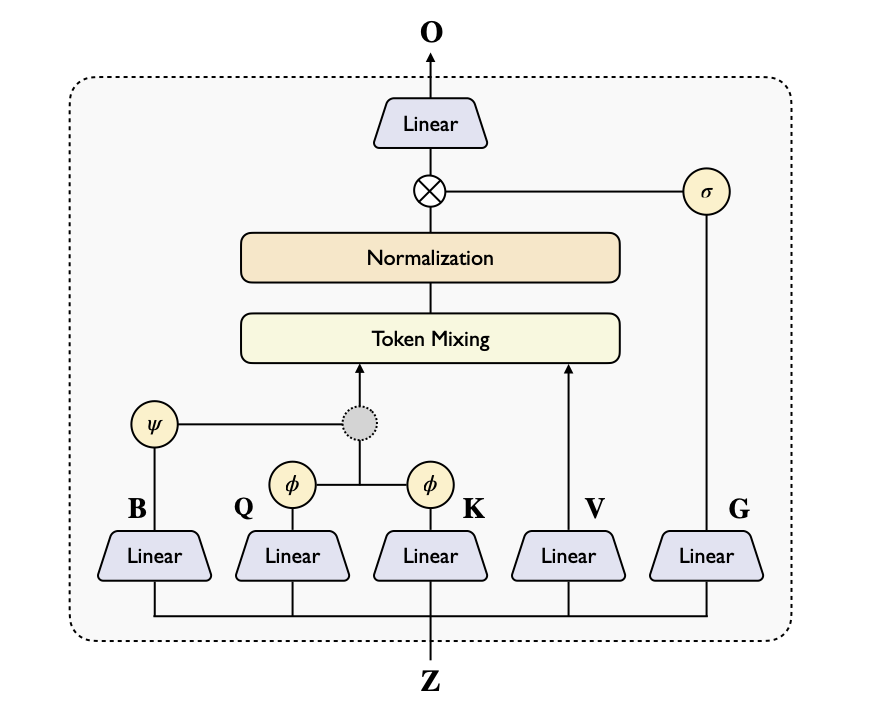


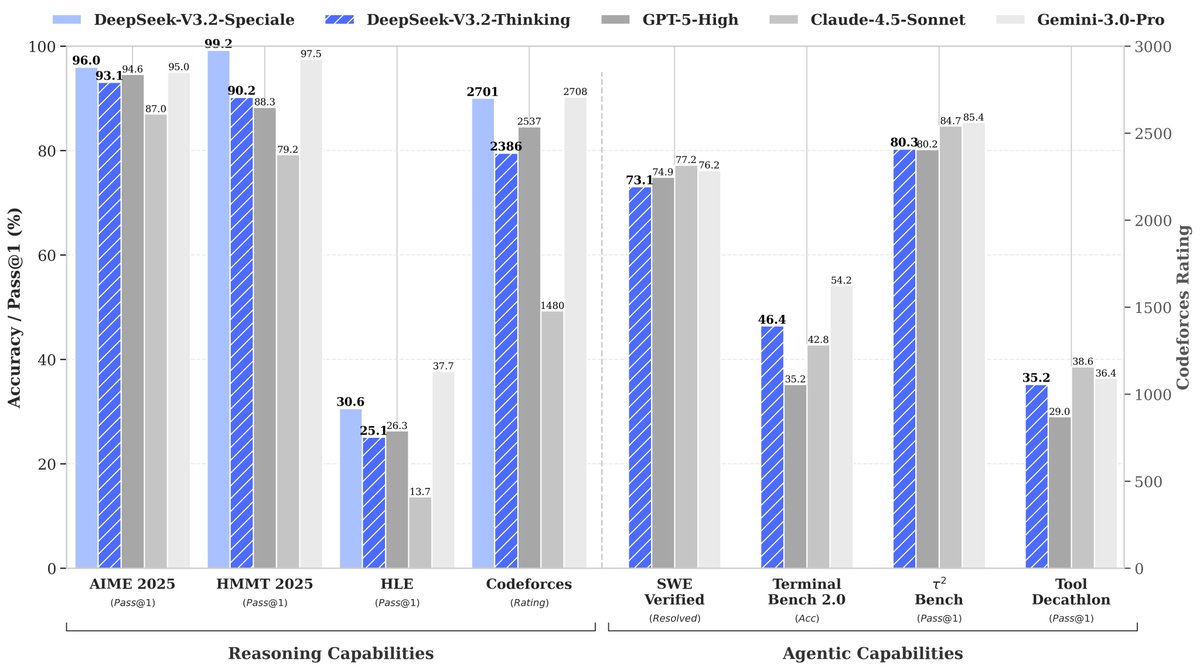



I think this is the most interesting/innovative part of BoltzGen. Diffusing to AF2-style encoding to co-generate both backbone and sidechains identities! 🤯





