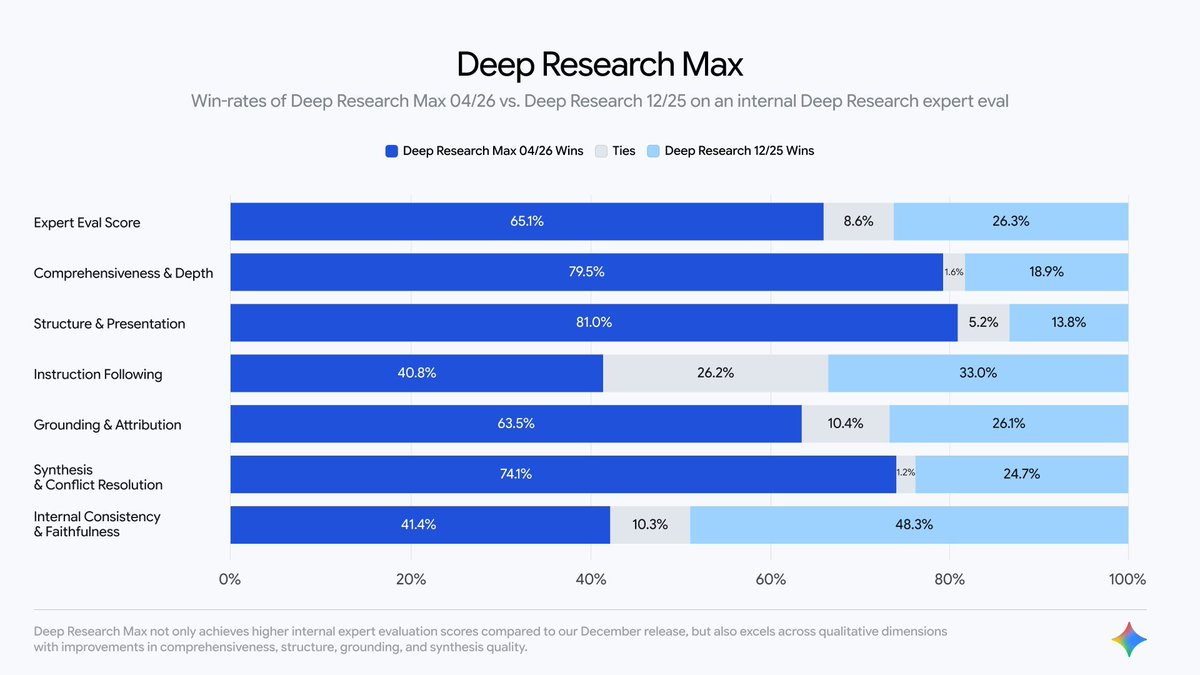
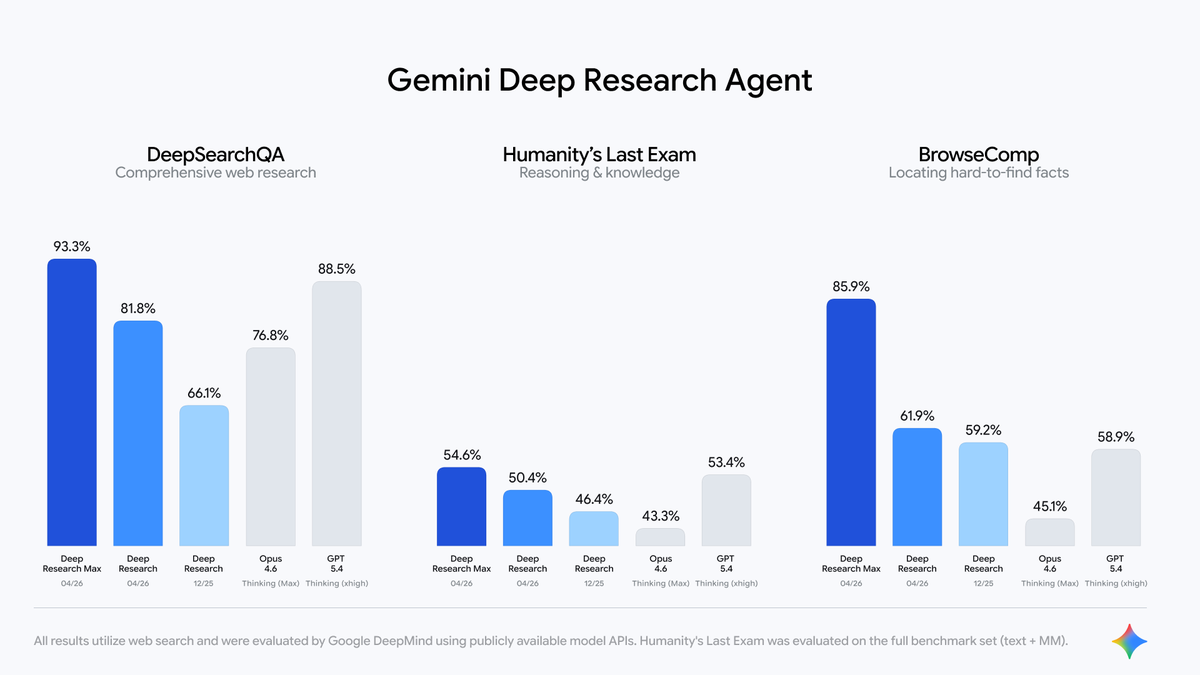
@AndrewCurran_ It’s the kind of play that could quietly accelerate agentic adoption in places that usually move slower, where persistent workflows and reliable tool use matter more than flashy demos.
English
Amaan
277 posts

@amaank_tweets
I want to win!!!