Sabitlenmiş Tweet

I am pleased to announce our paper has been published in Carbohydrate Polymers. Thanks to all members of this excellent team, i look forward to working with you all again.
sciencedirect.com/science/articl…
English
Winnie S. H.
4.9K posts

@anaslaaa
Glycoinformatics #paleontology #polysaccharide #biomedicalinformatics Late Pleistocene and Cretaceous flora UCB/TAMU/TMU/KTH 🌎 Opinions are my own 🌓 ➯☀️

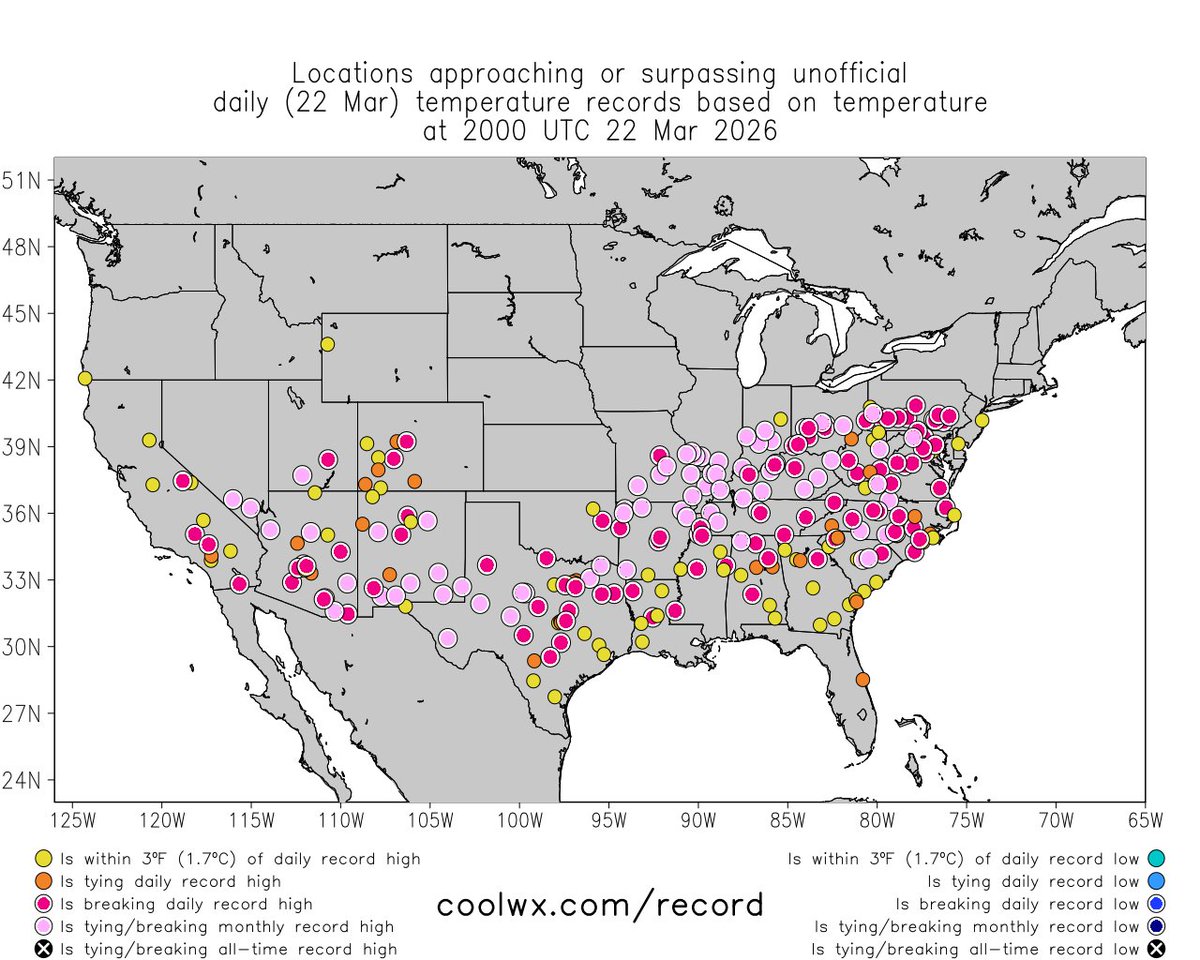
On Mon, Mar 23 at 2pm PT, I'll have another heatwave-focused livestream. I'll discuss the astonishing March heatwave (which will resurge this week), plus prospects for more substantial but temporary relief in form of cooler (& wetter?) early Apr pattern. youtube.com/live/yNA52Sriz…










Endonuclease V: From Transcriptome Regulator to Chemical Biology Tool by Jennifer M. Heemstra and co-workers (@jenheemstra, @HeemstraLab, @WashUChem) #OpenAccess …mistry-europe.onlinelibrary.wiley.com/doi/10.1002/ce…

Average accuracy of medical foundation models does not answer the operational question: Is this prediction reliable enough to act on for this patient, now? And what if not? This requires not only uncertainty quantification for AI predictions, but also mechanisms to turn UQ into actionable decisions. 📢 Excited to share StratCP, a two-step conformal inference mechanism that decides when to act/defer, and what to do next for deferred cases, given any AI model. medrxiv.org/content/10.648… StratCP has two stages: ✅Action arm: Selects "correct" predictions for immediate action with error control (e.g., 5%). ❓Deferral arm: Returns prediction sets that contain the true disease status for most (e.g., 95%) of uncertain cases to guide confirmatory testing or expert review. StratCP enables identifying - 🎯 Accurate AI disease classification, - ❤️🩹 Long survivors based on time-to-event predictions, - 🧬 Rapid H&E-based AI diagnoses that can safely bypass costly genomics tests, and - 🩺 Suggest clinically coherent candidate labels A fun collaboration with the amazing @marinkazitnik @IntaeMoon ! #uncertainty #AI #conformalprediction #medicalAI #reliableAI




Running Terminal-Bench 2.0 on expensive frontier models costs $1K–$50K or more. BenchPress Predicts Gemini 3.1 Pro and Claude Opus 4.6's scores within ±2 points after 15 randomly selected benchmarks. .... using zero agentic benchmark data!! Cost: $0.
GEPA for skills is here! Introducing gskill, an automated pipeline to learn agent skills with @gepa_ai. With learned skills, we boost Claude Code’s repository task resolution rate to near-perfect levels, while making it 47% faster. Here's how we did it:
