Sabitlenmiş Tweet

Did a complete redesign of my website. Proud of this one. Have a look.
animikh.me
English
Animikh Aich
1.6K posts

@animikh_aich
R&D in Computer Vision, LLMs, Machine Learning & Scale them. Projects: https://t.co/ljCQU3v442, https://t.co/OLZoCelqcq, https://t.co/SYxnjXMIXt




LiteLLM HAS BEEN COMPROMISED, DO NOT UPDATE. We just discovered that LiteLLM pypi release 1.82.8. It has been compromised, it contains litellm_init.pth with base64 encoded instructions to send all the credentials it can find to remote server + self-replicate. link below


This is wild. theaustralian.com.au/business/techn…

It took another two months but Chrome 146 is out since yesterday! And *that* means: with a single toggle, you can expose your current live browsing session via MCP and have your CLI agent do things in it. Aaand I have been waiting to deal with my LI connects until this moment.


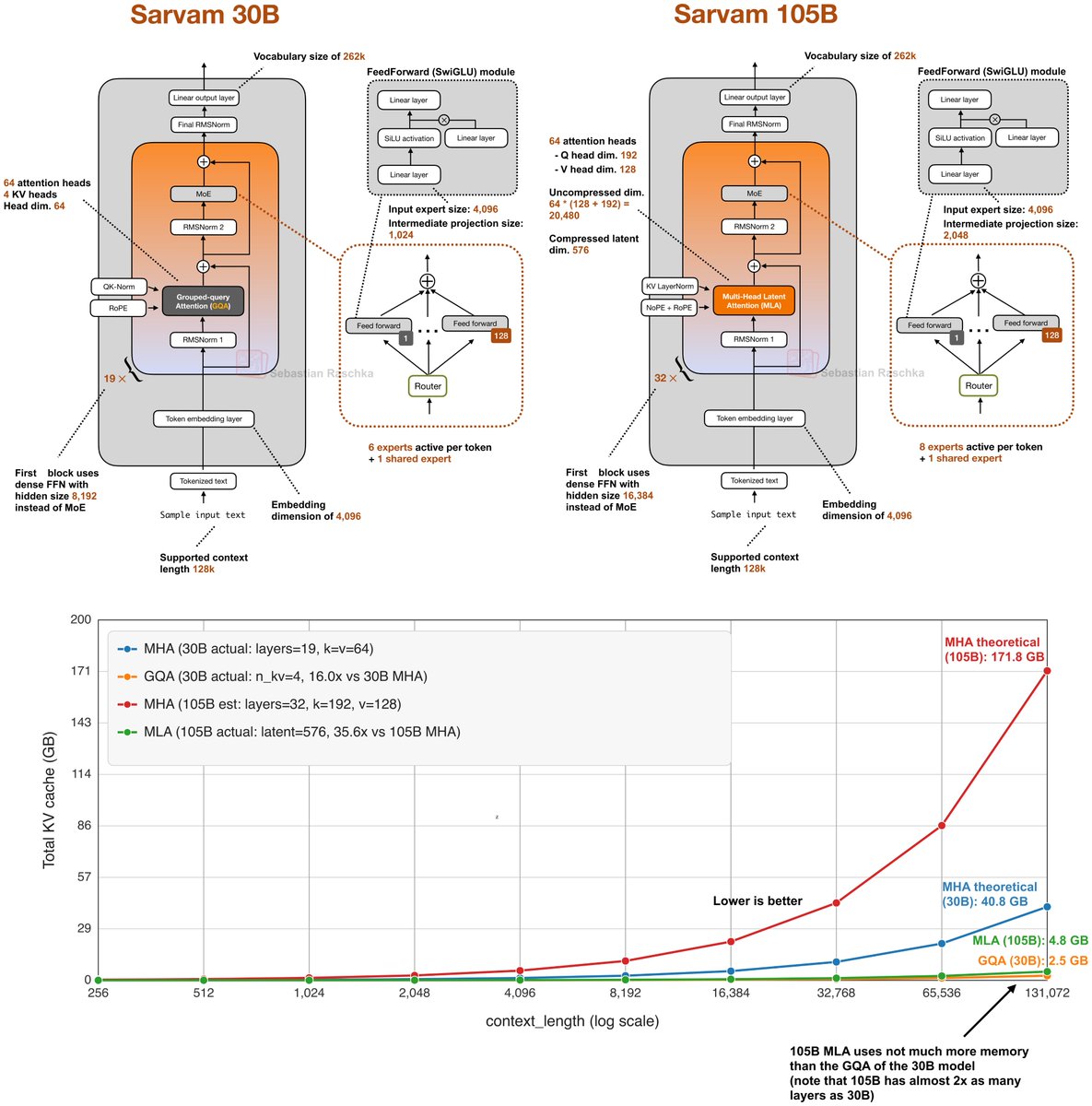
📢 Open-sourcing the Sarvam 30B and 105B models! Trained from scratch with all data, model research and inference optimisation done in-house, these models punch above their weight in most global benchmarks plus excel in Indian languages. Get the weights at Hugging Face and AIKosh. Thanks to the good folks at SGLang for day 0 support, vLLM support coming soon. Links, benchmark scores, examples, and more in our blog - sarvam.ai/blogs/sarvam-3…











Mom calls Snabbit just to unpack suitcase. Can happen only in Bengaluru 😂


🚨 Pune-based @QHyperloop has tested India’s longest track-based linear motor system, using patented 100 kW motors to propel a 300 kg container.