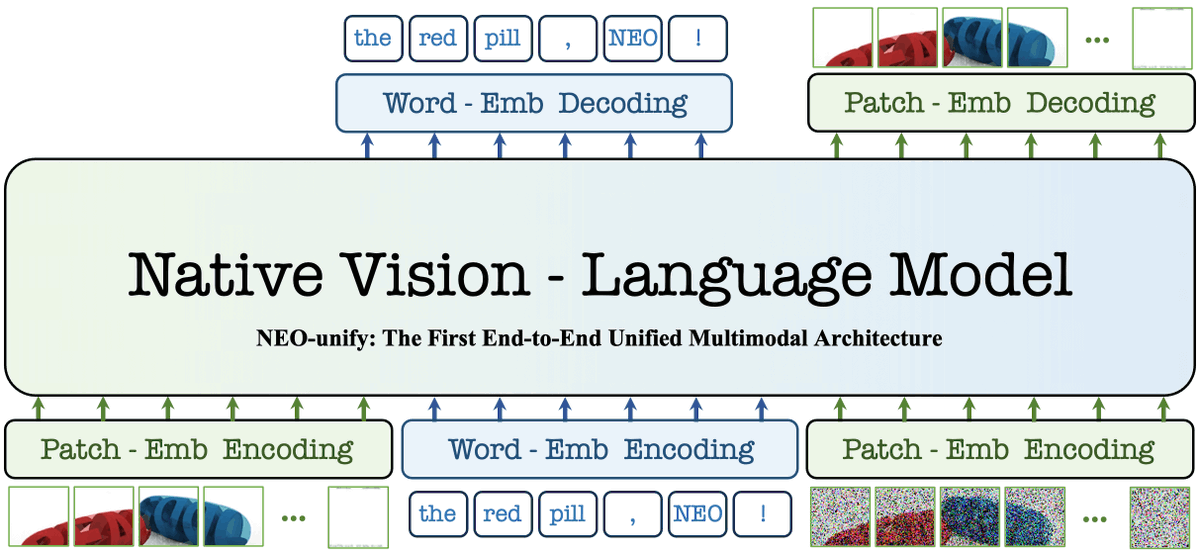
Sabitlenmiş Tweet

Happy to share - “VSTAR: Generative Temporal Nursing for Longer Dynamic Video Synthesis” has been accepted to @iclr_conf #ICLR2025
Code: lnkd.in/eu6SMeKT
Paper: lnkd.in/e3mbE9PP
Kudos to the amazing team: @YumengLi_007 Bill Beluch @margret_keuper @isDanZhang ❤️
Anna Khoreva@anna_khoreva
Code for VSTAR is released 🚀 It enables longer video synthesis w/o re-training and allows to control the dynamics of the synthesised video. Check it out 👇
English