Sabitlenmiş Tweet
Avsek Jha
489 posts


Avsek Jha
@avsekza
engineer, product obsessive, and creator of Auralix. Building https://t.co/lPZeJJ3SxH | https://t.co/BWtF6uJnpZ
United States Katılım Ağustos 2024
601 Takip Edilen217 Takipçiler
Avsek Jha retweetledi

Avsek Jha retweetledi

Share your website. Let the work be appreciated.
I am sharing mine here!
auralix.ai
English
I am a full-time AI engineer. I build products that solve core supply chain problems. This involves spending an average of 5 hours in calls with customers to understand the problems, which reduces my building time. But recently, I devoted all my time to building agents for myself instead of my company. Everything I do is self-reported, and I prepare for anything I am responsible for. This increased my efficiency unimaginably. I am a full-time developer and love it, but any distractions absolutely drop my efficiency and energy.
This changed this week.
What are you doing for your 9-5?
English

I just finished setting up NanoBrain on my machine, and the results are incredible.
It’s a centralized hub for priorities inspired by the Andrej Karpathy "LLM Wiki" blueprint. The real "magic" is how it connects to every data source to keep you synchronized with your schedule in real-time. Finally, a way to solve the digital context-switching problem. 🛠️
Check out the open-source repo here: nanobrain.app
#AI #ContextEngineering #LLM #PersonalKnowledgeManagement
GIF
English
Avsek Jha retweetledi

ex-Googlers published a map of every internal tool Google uses
and its open-source equivalent.
15,200 stars. 1,100 forks. 99 contributors.
→ Borg = Kubernetes
→ Spanner = CockroachDB
→ Colossus = HDFS
→ Dremel = DuckDB / Presto
→ Chubby = Zookeeper
→ Stubby = gRPC
→ Zanzibar = SpiceDB
→ Blaze = Bazel
→ MapReduce = Spark
everything Google engineers use every day.
all of it has an open-source equivalent.
none of it requires working at Google.
like+bookmark
self.dll@seelffff
English

Did not realize until I used CODEX, 🤯! Next I will add that plugin here!
Avsek Jha@avsekza
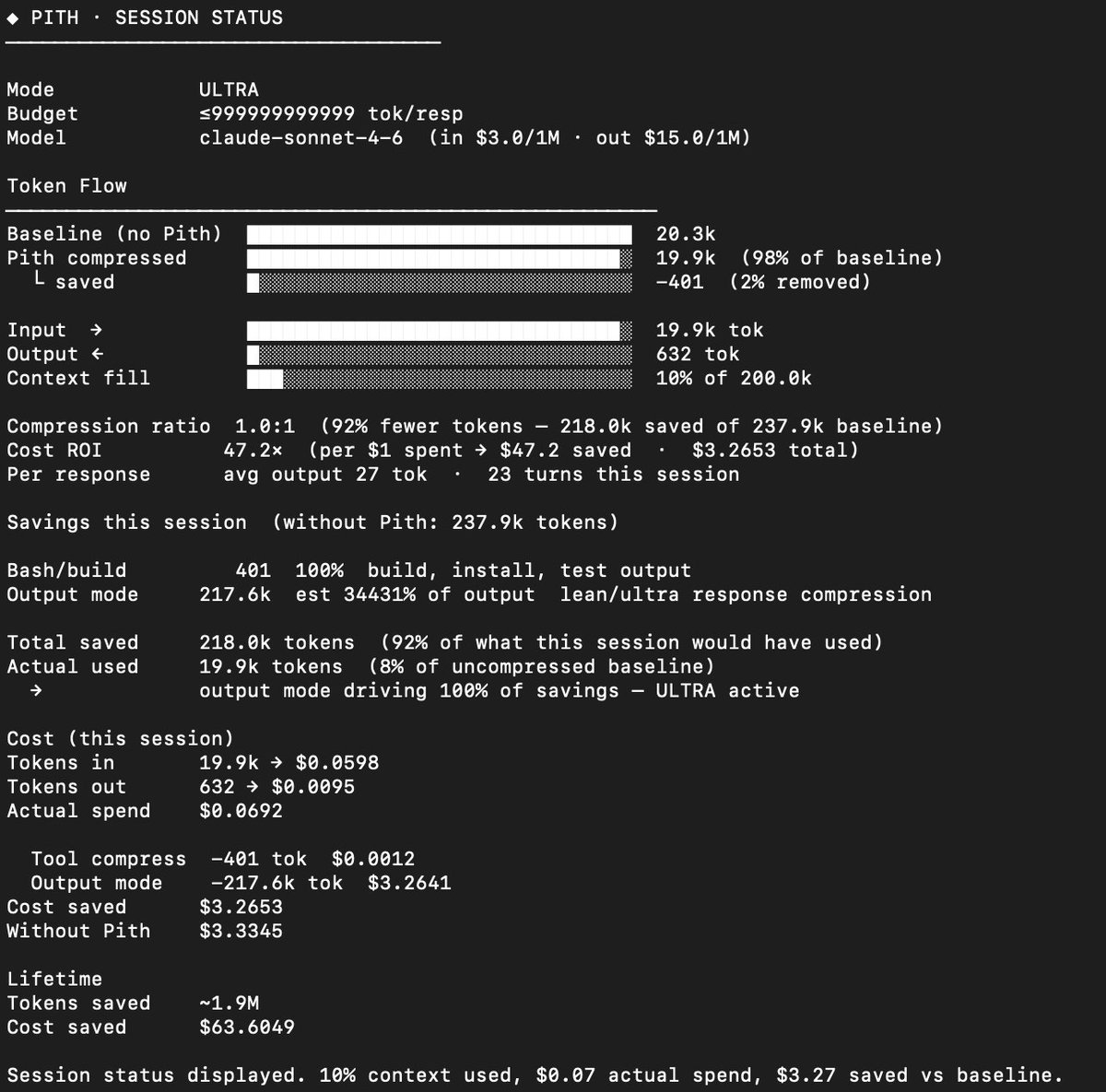
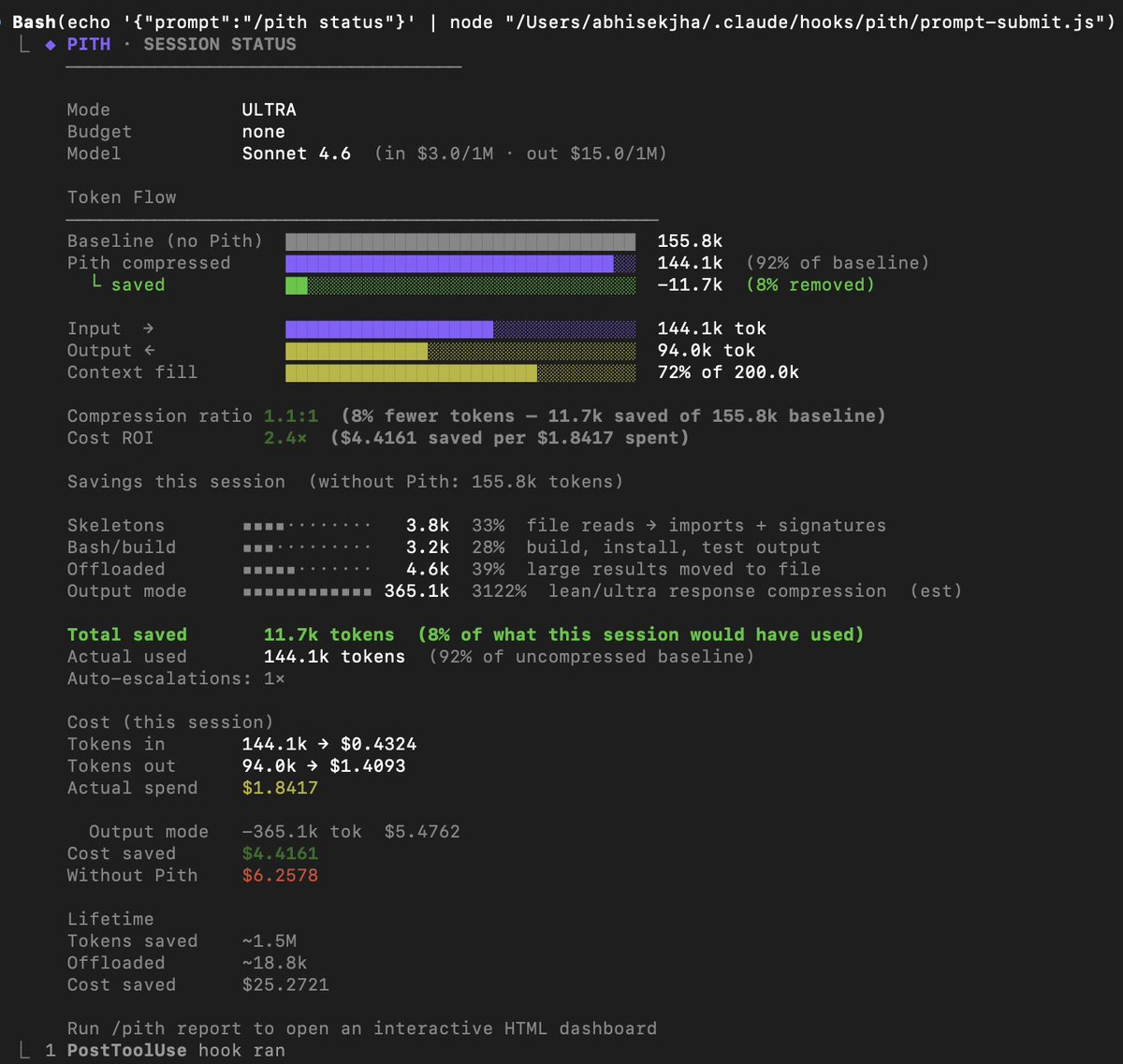
It’s incredible what happens when you stop wasting tokens. I’m seeing a massive spike in session endurance using Pith. Even with heavy Claude Code usage, I’m barely hitting the halfway mark on context. If it's this good now, Opus 4.7 is going to be a game-changer. GitHub: github.com/abhisekjha/pith #OpenSource #AI #Claude
English
Avsek Jha retweetledi
It’s incredible what happens when you stop wasting tokens.
I’m seeing a massive spike in session endurance using Pith. Even with heavy Claude Code usage, I’m barely hitting the halfway mark on context.
If it's this good now, Opus 4.7 is going to be a game-changer.
GitHub: github.com/abhisekjha/pith #OpenSource #AI #Claude

English
Avsek Jha retweetledi

// Agentic Harness Engineering //
Pay attention to this one, AI devs.
(bookmark it)
Most coding-agent harnesses are still tuned by hand or brittle trial-and-error self-evolution.
This new work introduces Agentic Harness Engineering, a framework that makes harness evolution observable. They do this through three layers: components as revertible files, experience as condensed evidence from millions of trajectory tokens, and decisions as falsifiable predictions checked against task outcomes.
Each edit becomes a contract you can verify or revert.
Results: pass@1 on Terminal-Bench 2 climbs from 69.7% to 77.0% in ten iterations, beating human-designed Codex-CLI (71.9%) and self-evolving baselines like ACE and TF-GRPO.
The evolved harness also transfers across model families with +5.1 to +10.1 point gains, while using 12% fewer tokens than the seed on SWE-bench-verified.
Harness work is the biggest hidden cost in most agent systems. This is the first credible recipe for letting the harness improve itself without drifting into noise.
Paper: arxiv.org/abs/2604.25850
Learn to build effective AI agents in our academy: academy.dair.ai

English
Avsek Jha retweetledi

Vector DBs can't reason.
Top-k similarity ranks chunks one at a time against a query. That's fine for single-hop fact lookups, and it breaks the moment a question needs information stitched across multiple chunks.
That's what the FalkorDB GraphRAG-Bench results expose. The gap is widest on Complex Reasoning (83.61) and Contextual Summarization (85.08), the exact query types where retrieval needs to traverse relations between entities, not score chunks in isolation.
Worth a closer look if your workload leans long-form.
GraphRAG SDK is 100% open-source: github.com/FalkorDB/Graph…
FalkorDB@falkordb
Token costs spiking. Responses too slow. Users don't trust the answers. All three are retrieval problems. GraphRAG SDK 1.0 is out. Ranked #1 on GraphRAG-Bench against 8 systems. Fewer LLM calls, grounded answers, predictable cost. Open-source: github.com/FalkorDB/Graph…
English
Avsek Jha retweetledi

Same text. Two privacy filters.
OpenAI's model catches 8 categories. OpenMed catches 55+: medical record numbers, blood type, API keys, financial codes, demographics.
Trained on Nemotron data by Nvidia. All on-device. All open-source.
Coming soon! What's missing?
English
Avsek Jha retweetledi

Introducing NetWatch 🧑💻👀
Netwatch is a CLI security monitor with real-time visibility into all network connections, featuring risk scoring, GeoIP, VPN detection, process validation, and alerts.
I built this in an airport on my way to San Francisco, my friends kept warning me about public Wi-Fi, so I made a tool to monitor all traffic to and from my computer lol.
Learn more ⬇️🧵

English

Avsek Jha retweetledi

Introducing Pods
Hyperspace Pods lets a small group of people - a family, a startup, a few friends, to pool their laptops and desktops into one AI cluster. Everyone installs the CLI, someone creates a pod, shares an invite link, and the machines form a mesh. Models like Qwen 3.5 32B or GLM-5 Turbo that need more memory than any single laptop has get automatically sharded across the group's devices - layers split proportionally, inference pipelined through the ring. From the outside it looks like one OpenAI-compatible API endpoint with a pk_* key that drops straight into your AI tools and products. No configuration beyond pasting the key and changing the base URL.
A team of five paying for cloud AI burns $500–2,000 a month on API calls. The same team's existing machines can serve Qwen 3.5 (competitive on SWE-bench) and GLM-5 Turbo (#1 on BrowseComp for tool-calling and web research) for free - the hardware is already on their desks. When a query genuinely needs a frontier model nobody has locally, the pod falls back to cloud at wholesale rates from a shared treasury. But for the daily work - code reviews, refactors, research, drafting - local models handle it and nobody gets billed. And when it is idle, you can rent out your pod on the compute marketplace, with fine-grained permissions for access management.
There's no central server involved in inference. Prompts go from your machine to your pod members' machines and back: all of this enabled by the fully peer-to-peer Hyperspace network. Pod state - who's a member, which API keys are valid, how much treasury is left - is replicated across members with consensus, so the whole thing works on a local network. Members behind home routers don't need port forwarding either. The practical setup for most pods is three models covering different jobs: Qwen 3.5 32B for code and reasoning, GLM-5 Turbo for browsing and research, Gemma 4 for fast lightweight tasks. All running on hardware you already own.
Pods ship today in Hyperspace v5.19. Model sharding, API keys, treasury, and Raft coordinator are all live.
What Makes This Different - No middleman. Your prompts travel from your IDE to your pod members' hardware and back. There is no server in between reading your data.
- No vendor lock-in. Pod membership, API keys, and treasury are replicated across your own machines using Raft consensus. If the internet goes down, your local network keeps working. There is no database in someone else's cloud that your pod depends on.
- Automatic sharding. You don't configure layer ranges or calculate VRAM budgets. Tell the pod which model you want. It figures out how to split it across whatever hardware is online.
- Real NAT traversal. Your friend behind a home router with a dynamic IP? Works. No VPN, no Tailscale, no port forwarding. The nodes handle it.
- Free when local. This is the part that matters most. Cloud AI bills scale with usage. Pod inference on local hardware scales with nothing. The marginal cost of your 10,000th prompt is the electricity your laptop was already using.
Coming soon:
- Pod federation: pods form alliances with other pods.
- Marketplace: pods with spare capacity can sell inference to other pods.
English

Really impressed by how smooth switching most of my coding tasks to Codex (GPT-5.5) from Claude Code (Opus 4.7) has been.
I thought it was going to be more difficult and that I would be "fighting" with the model a lot.
If there was ever a good time to try Codex, it would be now.
I feel like Codex (GPT-5.5) just gets it and has a "warmer and more welcoming personality" compared to previous iterations. I appreciate the sharp responses and how straight to the point it is.
I really don't care about these benchmark numbers anymore. They don't say anything about how good an agent harness performs in real work tasks.
GPT-5.5 tries hard to get as much done, given the scope of the instruction. It doesn't try too hard (doing things that I haven't asked) or too little. The effort feels just right. I think that part is hard to get right, but there is something very different about how this model was trained and how aligned it is to be helpful.
Skills have also helped a lot in this switch. Both Claude Code and Codex now make proper use of all my skills. MCP tools work right out of the box.
I was a heavy user of the Claude-in-Chrome tools, but GPT-5.5 + chrome-cdp skill is actually amazing!
Finally, having a blast with coding agents again.
Opus 4.7 has superb planning, and I will continue to use it for lots of my research and automated tasks.
Will keep testing both Claude Code and Codex and a few other coding agents and share more along the way.
English