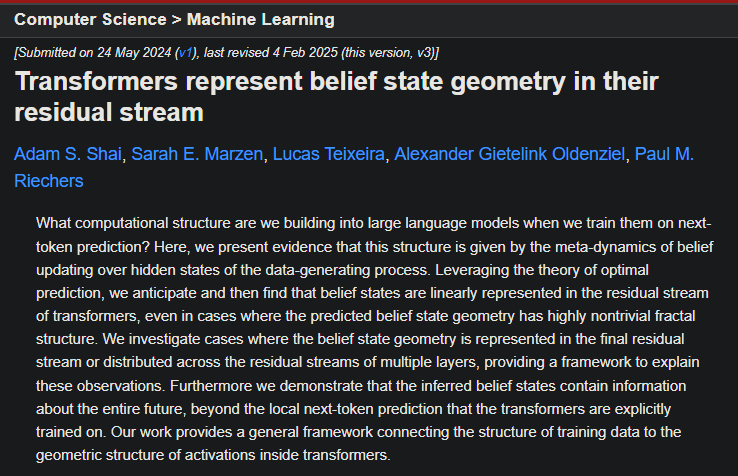
Sabitlenmiş Tweet
aw 🪐
24K posts


aw 🪐
@awertheim
time | health | family | truth
planet earth, at the moment Katılım Mart 2009
657 Takip Edilen2.1K Takipçiler
aw 🪐 retweetledi

@unusual_whales There’s no such thing as universal high income
If everyone has high income, nobody has high income
English
@TurnerNovak @SBF_FTX Not bankrupt. The status of FTX if SBF hadn’t illegally invested customers’ deposits
English



English

@awertheim Got stupid lucky today
🌎 Apr 17, 2026 🌍
🔥 19 | Avg. Guesses: 7.47
🟨🟨🟧🟩 = 4
globle-game.com
#globle
English
@dwarkesh_sp, mad respect for your Jensen interview. I appreciate your persistence and pushing back so hard on the China question. It was refreshing seeing him engage with someone who knows so much in his area of expertise and being challenged on *his* premises.
English
aw 🪐 retweetledi

Solana $SOL breaks blockchain all time high for economic activity - Q1 2026 - $1.1 trillion
In Q1 2026, @solana 's total on-chain economic activity hit $1.1 trillion for the quarter.
This is the first time any blockchain (including @ethereum and @Bitcoin) has ever crossed the $1 trillion mark in a single quarter.
Daily active users climbed to ~4.6 million with billions of transactions processed.
Solana captured 41% of all onchain activity (including Bitcoin and Ethereum)
English

@CharlieM0nger @fejau_inc 💯 It's refreshing seeing someone with deep AI knowledge and facts push back on Jensen when the answers he was giving were clearly hand-wavy and not adequately addressing @dwarkesh_sp's points
Excellent podcast by an outstanding podcaster
English

@fejau_inc @awertheim I thought he handled it like a rockstar haha
English

@BackTheBunny @inversebrah There are only finalized local shapes and patterns; a local minima in an infinite gradient decent landscape. Nature converges on those. Random step changes can potentially spur paths to new local minima and therefore whole new categories of shapes and patterns
English

there very much seems to be a finite number of shapes to the world we occupy. this means there’s a finite number of useful sequences of patterns. which means there’s ceiling to intelligence.
all intelligence is pattern matching. if there are only so many patterns, there can only be so much intelligence.
maximum intelligence approaches omniscience, but can never fully get there, for a very important thermodynamic reason.
if you can predict everything, that means there is no “surprise” (prediction error). if you are never surprised by your surroundings, that means you’re never wrong. implying one of two things:
1. you are dead. there is no prediction error because there’s no energy gradient to descend, because you’ve stopped existing. thermodynamic equilibrium is indistinguishable from death.
2. you’re God

charm ~ research sabbatical arc@charmcgi
the first time i saw this image i gasped
English
Definitely worth a watch...
Deleted all @Visa cards from my iPhone
youtu.be/PPJ6NJkmDAo?si…

YouTube
English
Is it really that wild? That would be less than 1/3rd of 1% of @elonmusk’s net worth.
If anything, it’d be wild if it were Only this much..
The Bitcoin Historian@pete_rizzo_
BREAKING: ELON MUSK'S FATHER JUST SAID HIS SONS ELON AND KIMBLE OWN COMBINED 23,000 #BITCOIN WORTH OVER $1,700,000,000 THIS IS WILD 🔥
English

Michael Saylor’s Strategy ($MSTR) has bought 94,470 BTC this year.
Only 46,625 BTC were mined.
He has bought twice the amount of BTC that has been created this year.


English
aw 🪐 retweetledi

🎯 Welcome Back Integrity, with a bullseye splash down just now
And tomorrow is the 66-year anniversary of the Apollo 13 launch, the last time a mission brought the astronauts back with a free-return trajectory, slingshotting around the moon.

Steve Jurvetson@FutureJurvetson
Godspeed Artemis, twin sister of Apollo
English
aw 🪐 retweetledi

1hr and 52 minutes until infrastructure day, and there is no material organization of a narrative, this shit is pure chaos
English

@lexfridman @karpathy would love to see a stream where you show what this look like functionally
English

Same, I have a similar setup. A mix of Obsidian, Cursor (for md), and vibe-coded web terminals as front-end.
Since I do a podcast, the number/diversity of research interests is very large. But the knowledge-base approach has been working great.
For answers, I often have it generate dynamic html (with js) that allows me to sort/filter data and to tinker with visualizations interactively.
Another useful thing is I have the system generate a temporary focused mini-knowledge-base for a particular topic that I then load into an LLM for voice-mode interaction on a long 7-10 mile run. So it becomes an interactive podcast while I run, where I ask it questions and listen to the answers to learn more.
Anyway, heading out for a run now, thanks for the write-up 👊
English

LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English