
Ben Barrey
171 posts

Ben Barrey
@barrey_ben
Poetic Engineer. Built @Turi_ai to run an AI company. Teaching small businesses how to deploy AI safely & effectively.
The Matrix Katılım Kasım 2021
421 Takip Edilen17 Takipçiler

Americans: “no way I’m spending $2,000/mo on frontier AI models…”
also Americans: buys $17 salads from Whole Foods, pays $3 extra at Chipotle for guacamole, willingly spends $9 on oat milk lattes, has 4 family streaming subscriptions they forgot about, and tips 30% on UberEats
English


Ben Barrey retweetledi

Ben Barrey retweetledi
a great way to get started is to use our skill, built into Claude Code. get the latest Claude Code release:
$ claude update
then start Claude Code and run our subcommand:
$ claude
/claude-api managed-agents-onboarding
English
@TheAhmadOsman @NVIDIAAIDev Concurrent workloads. Lots of agents. Some that’ll give the Blackwells a real test
English

Hot take: you’ve had your supercomputer human brain your whole life and used no more than 10% of it. You’ve had Opus-4.6 and GPT-5.4 for two months and used probably 5% of its capabilities. You don’t need Mythos to get what you need done.
English
Yea don’t overthink it, it’s basically a multimodal notes app. Get Git and Templater plugins. Get a theme/skin you like. The sauce is how you setup your frontmatter templates to auto generate on new notes and structure of your vault so agents can have easy access/write/retrieve. The karpathy wiki is just a start, adding custom workflow/skills and how you want your links setup is where it gets interesting.
English

damn people are opinionated af about obsidian
I’m diving in right now
fist impression:
not very self explanatory for a non technical potato like me
I’ll share my progress soon
Ole Lehmann@itsolelehmann
why would I use obsidian when I can just use claude code for the knowledge base? whats the advantage?
English
Oh I don’t disagree with you. It’s a young format having growing pains, but it’s yet to be seen what software improvements and new models could improve it. Right now sure I’d probably take the M5 instead. My initial point was vs. RTX GPUs and how it’s kinda apples to oranges to compare the spark to
English

@barrey_ben @TeksEdge Spark is basically a parody of their data center offerings, overpriced crumbs for plebs, calling it "DGX" for a good laugh. The compute power is laughable, the memory bandwith is beyond dogshit. Utterly shameful.
My sentiment is all but isolated:
forums.developer.nvidia.com/t/i-am-extreme…
English

💨 Running Gemma-4-26B-A4B-it on a NVIDIA DGX Spark (GB10 Blackwell) at 37 tps just feels more pure than running on a huge costly RTX-5090 gaming rig.
• 26B total params / ~4B active (MoE magic)
• Running smooth with NVFP4 quantization
• Hitting 37 tokens/sec decode on interactive chats & agents Feels snappy.
Only ~16GB loaded → 256K context has tons of room left.
English
@shitcoinity @TeksEdge I wouldn’t write off the spark, depends on adoption of NVFP4 vs. MLX and which architecture actually ends up benefiting more from newer model quants. Plus Mac’s are generally more expensive comparatively. Spark clusters could still be very interesting. I see competition here.
English
@barrey_ben @TeksEdge Insanely better value, especially for the 512 Ultra. Which is insane considering we're talking about Apple.
English
@barrey_ben @TeksEdge Spark is utter garbage in every single way. It's an insult to consumers. They push me towards Mac for the first time in my life.
English
Ben Barrey retweetledi



@joshuamschultz @coltfeltes @nvidia @Dell Shout out to @Teknium and @dotta going on the road with paperclip/hermes. nice!
English

I have a partnership agreement with Dell and Nvidia - so different.
When I sell these to small businesses and set them up
its about 5k for a spark
a few hundred per cable
and then dev time (unless you do yourself)
you'll need
- triton server and/or vllm
- docker / k3 setups (which openshell uses)
- the vpn setup (I just built in/through unifi)
- then the actual agent setup (I use Arc (mine), openclaw, and hermes)
- and then the orchestration (ArcTeam, and Paperclip for me)
So about 25k and a lot of time
English
The system is coming together...
1 @nvidia Spark
4 @Dell GB10s
5 Blackwell GPUs for a mini home cluster.
3 networked together for ability for a 400+ billion param model (3 petaflops of compute at a unified 384 GB of memory)
... serving 3 models to the other 2 units hosting various agents, agent teams along with
@nvidia personaplex
claude code instances
knowledge bases
etc
Currently playing with models including splits/routing between
- kimi (reasoning)
- minimax
- nemotron super (agent)
- qwen (coding and routing)
working on training as well with the opus reasoning traces dataset in @huggingface
Getting close to fully owning the intelligence and the inference!


English
@0xSero Let everyone sleep and keep buying up the 3090s, keeps the price low on Blackwell lol
English

We have a new best local AI entry level GPU 😎
Mike Gropp@MikeGropp
24GB GDDR6, 8960 CUDA cores 70 WATTS! WHAT?! Yes, I am sure it runs like a low power laptop GPU compared to an A5000 or 3090... but still!
English


Google is going to win.
All that matters asymptotically is compute.
Epoch AI@EpochAIResearch
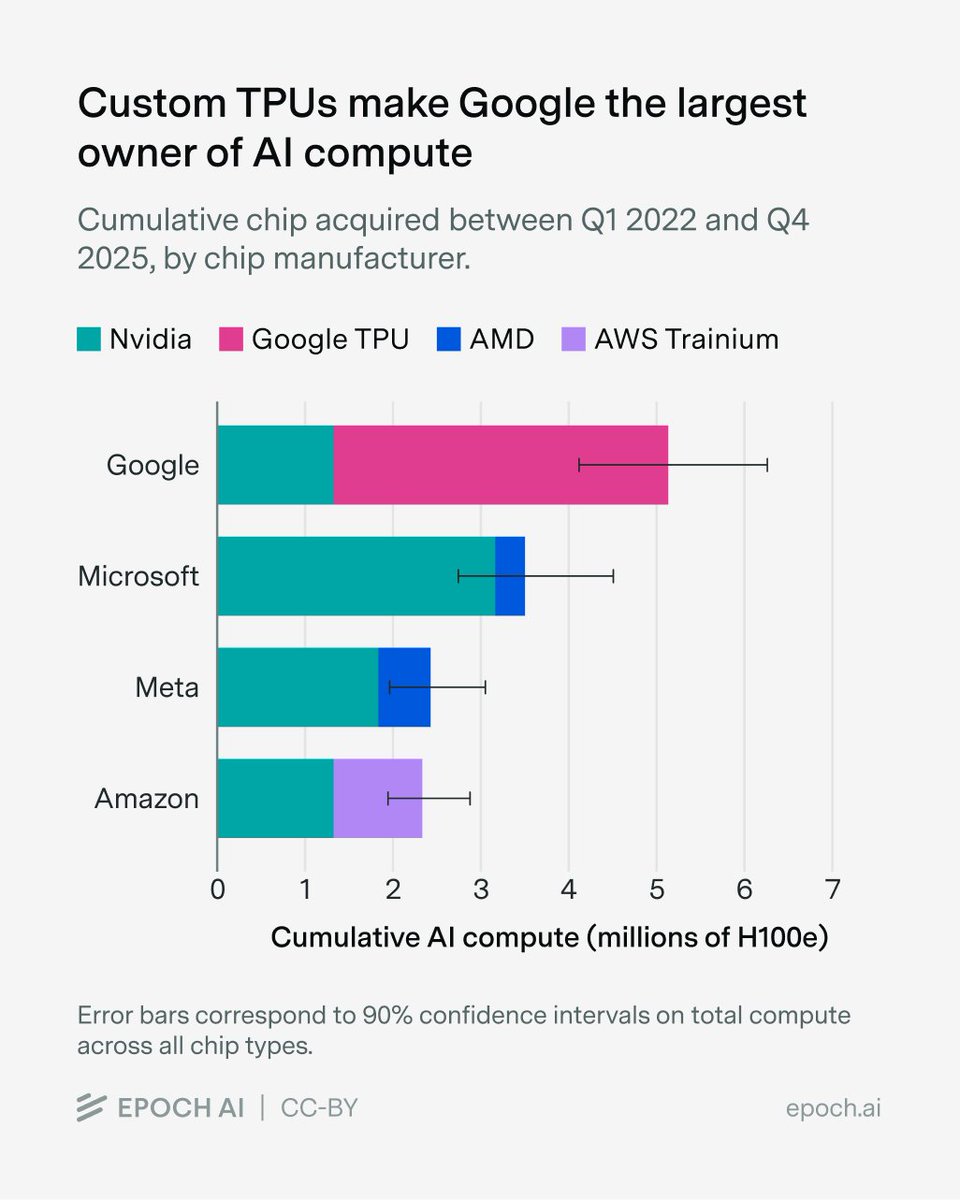
We estimate that over 60% of global AI compute is owned by the top US hyperscalers, led by Google with the equivalent of roughly 5 million Nvidia H100 GPUs! Unlike the other hyperscalers, which rely primarily on Nvidia, Google’s fleet is dominated by its custom TPU chips.
English
Ben Barrey retweetledi

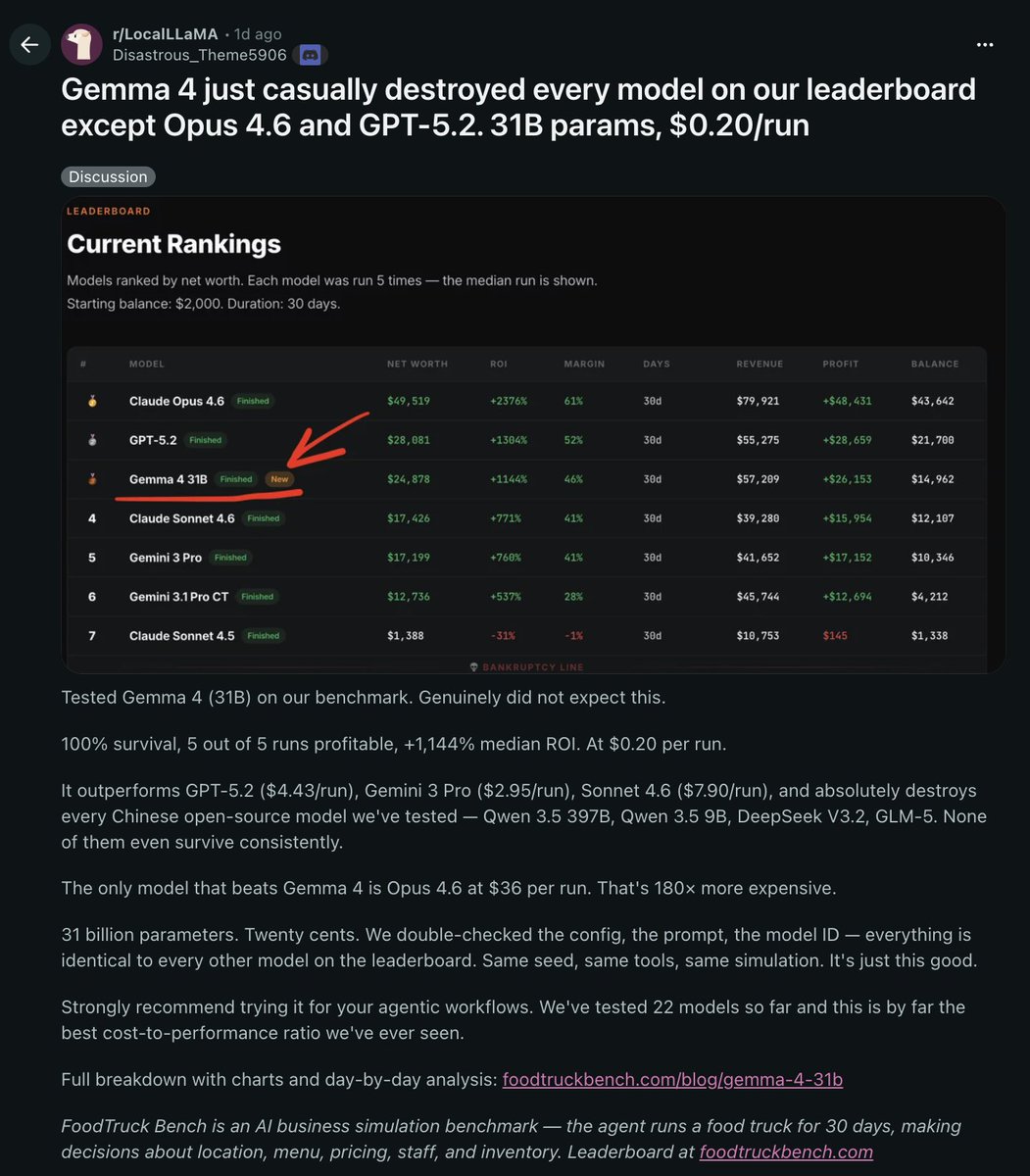
GEMMA 4 JUST CASUALLY DESTROYED EVERY MODEL ON THIS LEADERBOARD EXCEPT OPUS 4.6 AND GPT-5.2
31 billion parameters at $0.20 per run
a model you can run locally on your own machine is now competing with the best closed-source models on the planet
it beat every other model they tested on their benchmark.
the only two it couldn't touch were Opus 4.6 and GPT-5.2
for context those models cost 10-50x more to run with Opus being 180x more to run.
open source is catching up faster than anyone expected
English