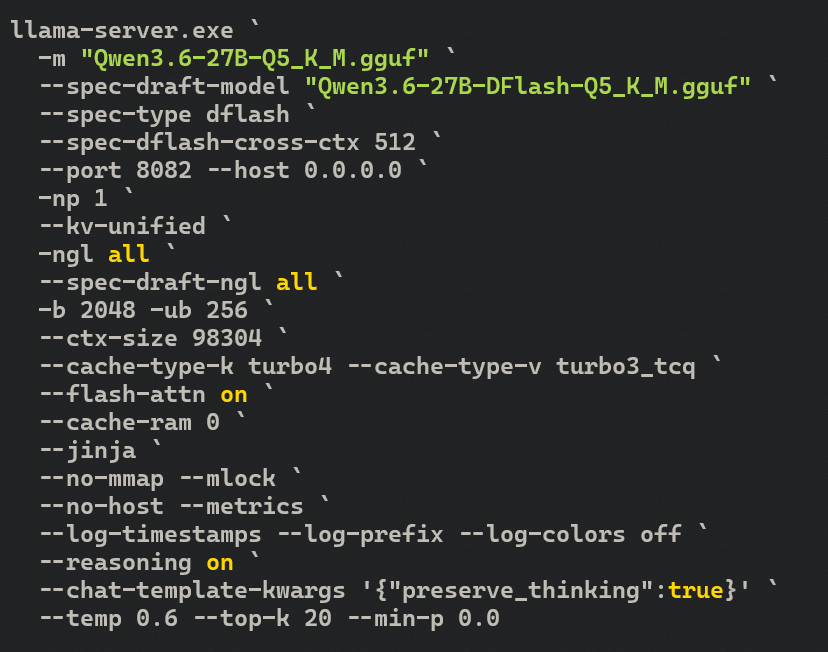
made a PR to merge the new llama.cpp w/ MTP into beellama.cpp 🐝
enables MTP and DFlash + Turboquant TOGETHER on a single 3090
Unfortunately, DFlash is far more impactful than MTP for my system + use case
#localLLM #club3090
github.com/Anbeeld/beella…

English