Sabitlenmiş Tweet

My 9-month internship journey at Microsoft Research Asia comes to an end.
Two keywords throughout: self-distillation and exploration in LLM post-training.
What I took away from this journey: self-distillation plays qualitatively different, even opposite roles depending on the type of LLM reasoning.
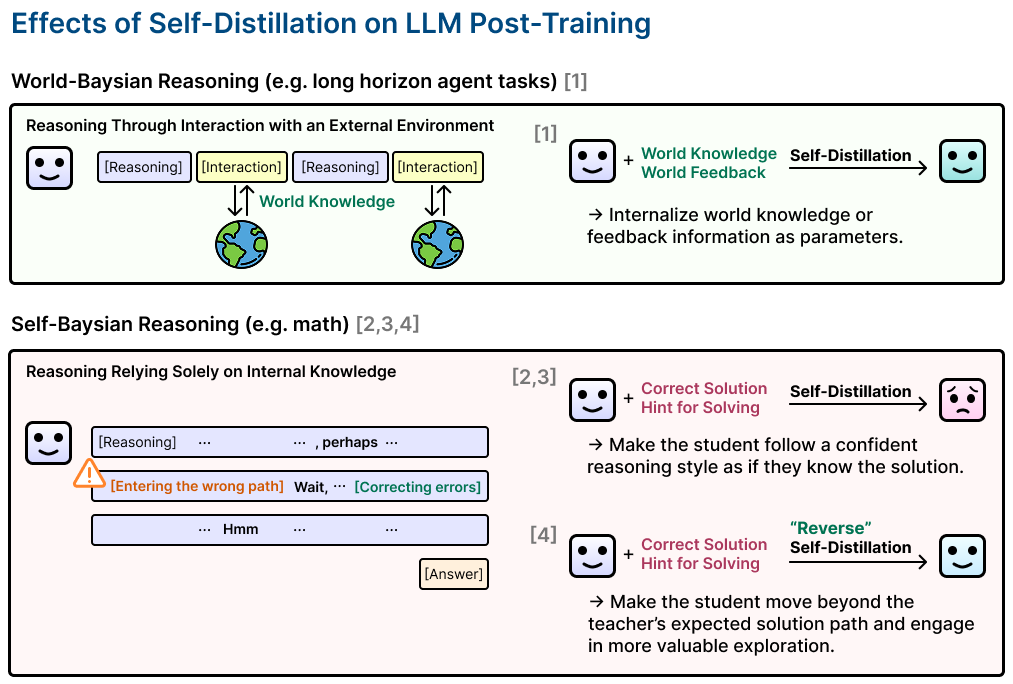
[1] In my first project, we used online self-distillation with text feedback for long-horizon agent tasks, enabling efficient exploration and significant performance gains (up to 128%!).
Since self-distillation proved so effective in agent settings, extending it to single-turn math reasoning felt like a natural next step. But across various implementations and models, we observed only a brief initial improvement followed by a decreasing performance. Hmm…Why? The answer wasn't obvious, and I spent much of the remaining months digging into this gap.
[2] It came down to one question: when reasoning goes off track, how does the model even know?
In world-Bayesian reasoning, where the model interacts with an external environment, the environment provides the answer.
In self-Bayesian reasoning, where reasoning is purely internal, there is no such signal. The model's sporadic epistemic verbalization, "wait, is this right?", becomes virtually the only error detection mechanism enabling robust reasoning.
[3] This is why self-distillation plays opposite roles in the two settings.
In world-Bayesian reasoning, self-distillation internalizes external world knowledge into model parameters. A positive role.
But in self-Bayesian reasoning, the teacher already knows the solution, so its trajectory has no reason to contain uncertainty expression. The student learns from this and loses the ability to externalize uncertainty. The very mechanism essential for robust reasoning disappears.
[4] This points to the reverse: in self-Bayesian reasoning, encouraging epistemic verbalization rather than suppressing it is what drives meaningful exploration.
👉Papers:
[1] Exploratory Memory-Augmented LLM Agent via Hybrid On- and Off-Policy Optimization (ICLR26, 25.09)
[2] Understanding Reasoning in LLMs through Strategic Information Allocation under Uncertainty (Initial release: 26.03, Revised: 26.05)
[3] Why Does Self-Distillation (Sometimes) Degrade the Reasoning Capability of LLMs? (26.03)
[4] Rebellious Student: Reversing Teacher Signals for Reasoning Exploration with Self-Distilled RLVR (26.05)
Lots of exciting results still to share. I believe real-world LLM reasoning requires a good combination of world-Bayesian and self-Bayesian approaches. Looking forward to the discussions!
Huge thanks to my colleagues at MSRA for all the discussions and support along the way💚 I feel lucky to have worked with this team.
English






