English
Belle
80 posts



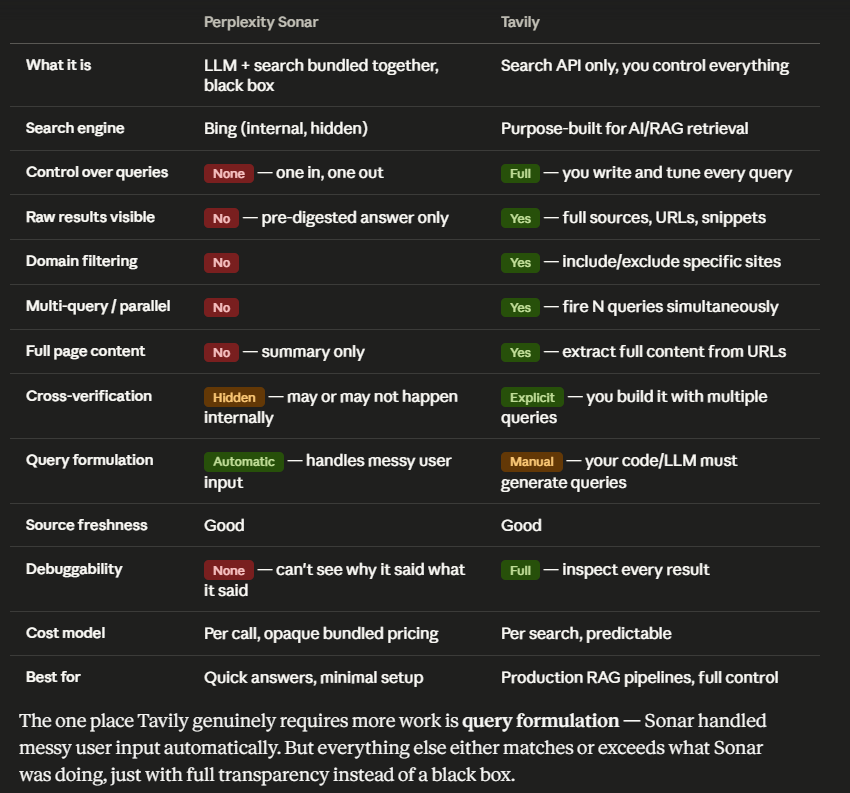









We've made our search MCP super easy to use. No need for an account or API keys. And it's free! claude code prompt: "add free search.parallel.ai/mcp - no auth needed. add permissions.allow for both tools and deny native web search and fetch" codex cli prompt: "edit ~/.codex/config.toml to add web_search = "disabled" and add the free mcp search.parallel.ai/mcp - no auth needed"






@perplexity_ai Can you please stop the undisclosed promotion campaigns? It deceives users and it does not reflect well on your company or your integrity. @AravSrinivas x.com/goddek/status/…