@aakashgupta Wild timing for this study. we went from handwriting → typing → now just talking to AI. Each step probably loses more of that brain connectivity. We're basically outsourcing the encoding too.
Your brain has a learning circuit it only runs when you write by hand. 256 electrodes on 36 students just confirmed it.
The Van der Meer lab at NTNU put high-density EEG nets on university students and had them write the same visually presented words two ways. With a digital pen in cursive. Then on a keyboard. Same words. Same room. Same brains.
Handwriting lit up widespread connectivity across the parietal and central regions. Theta band activity in the 3.5 to 7.5 Hz range. Alpha activity from 8 to 12.5 Hz. Those are the exact frequencies the brain uses to encode new information and consolidate it into memory. The connectivity map looked like a city at night.
Typing produced almost none of it. The same words on a keyboard registered as a different category of action entirely. At the finger level, the motor sequence looked similar enough. The brain was barely recruiting any of the networks it was firing for the pen.
The behavioral side was already settled in 2014. Pam Mueller at Princeton and Daniel Oppenheimer at UCLA ran three studies, 67 to 151 students per cohort. Laptops had the internet disabled. No distraction. Pure notetaking. The longhand group beat the laptop group on every conceptual question on the test.
The laptop group wrote more words. They captured more of the lecture verbatim. They retained less of the meaning. Transcription is not encoding.
The mechanism is fine motor planning. A keystroke is one of 26 binary choices, executed with the same finger pressure every time. A cursive letter is a continuous, custom trajectory the brain has to plan from scratch, frame by frame, predicting how the line will land before the pen gets there. That predictive motor effort is precisely the load that recruits the parietal cortex and forces deep encoding.
A follow-on study ran the same protocol on children. The theta synchronization showed up the same way. The brain treats handwriting as a learning operation regardless of age.
25 US states now require cursive instruction in elementary school, up from 14 less than a decade ago. California reinstated the mandate in 2024. Kentucky in 2024. Maine in 2025. Norway and Sweden are walking back classroom screens. The neuroscience finally caught up with the procurement contracts.
Your notebook is a learning device. Your laptop is a transcription device. The brain knows the difference.
@Av1dlive Karpathy is one of the few people who can explain complex agent architecture in a way that actually changes how you think. Watched this and immediately rethought how I structure task delegation across agents. Worth every minute.
In 17 minutes, Andrej Karpathy will teach you more about building ai agents than most people figure out in a year.
Bookmark & watch, no matter what. It'll be the most productive thing you do this weekend.
Then read the article below.
This is brilliant. The raw/ → LLM-compile → Obsidian Markdown wiki loop is exactly the workflow I have been living in lately. It is a clean and powerful way to use these models for deep research.
I have been obsessed with solving the "raw input" part of this specific chain. I ended up building a Chrome extension and CLI (Copy as Markdown) just to feed this pipeline. One hotkey turns any page into noise-free Markdown, which makes it easy to drop files into that raw/ folder or let agents ingest them via the CLI.
I had not thought about the Obsidian extension though. Might give that a try.
github.com/sulmatajb/copy…
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
1/ Agents think in HTML. Now they can build in it.
Pass raw HTML and CSS directly to the Webflow MCP server and it converts to native Webflow elements instantly. No more building node by node.🎉
The new @Webflow MCP v1.2 just dropped.🔥
Raw HTML to Webflow elements. Component slots. 500+ CSS properties. Element querying. Variable creation.
Your agents just got a whole lot more powerful. Here's what's new 🧵
.NET 10 + AI devs get a gift: Generative AI for Beginners .NET v2.
Rewritten from scratch with MEAI abstractions, native‑SDK RAG, DI‑first samples, file‑based apps, and a full lesson on multi‑agent orchestration, tools, MCP.
Build Azure‑powered AI apps.
👉 ift.tt/qSd9lzQ
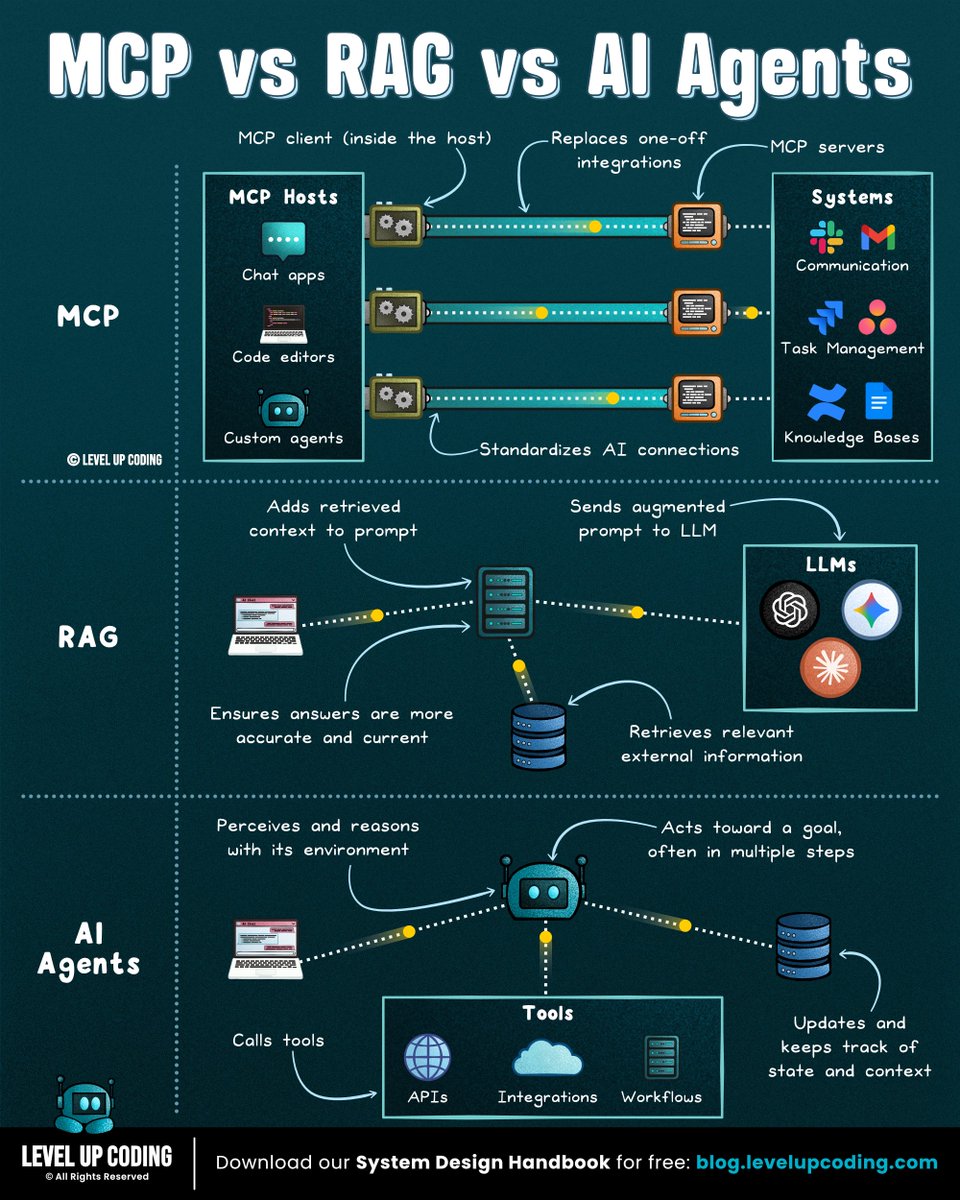
MCP vs RAG vs AI Agents
To understand modern AI systems, you need to understand how these three pieces fit together.
𝗥𝗔𝗚 = “𝗚𝗶𝘃𝗲 𝘁𝗵𝗲 𝗺𝗼𝗱𝗲𝗹 𝗯𝗲𝘁𝘁𝗲𝗿 𝗮𝗻𝘀𝘄𝗲𝗿𝘀”
RAG retrieves relevant data, injects it into the prompt, and generates a grounded response. It’s best when your problem is answering questions using your docs, reducing hallucinations, or showing sources and citations. RAG improves what the model knows, not what it can do.
If you’re building with these patterns, here's a great guide on scaling multi-agent RAG systems: lucode.co/multi-agent-ra…
𝗠𝗖𝗣 = “𝗦𝘁𝗮𝗻𝗱𝗮𝗿𝗱𝗶𝘇𝗲𝗱 𝘁𝗼𝗼𝗹 𝗮𝗻𝗱 𝗱𝗮𝘁𝗮 𝗮𝗰𝗰𝗲𝘀𝘀”
MCP is a standardized interface between LLMs and external systems like APIs, databases, and apps. Use it when your model needs to query data, call services, or interact with real systems (Slack, GitHub, etc). MCP doesn’t decide actions, it defines how tools are exposed.
𝗔𝗜 𝗔𝗴𝗲𝗻𝘁𝘀 = “𝗠𝗮𝗸𝗲 𝘁𝗵𝗲 𝗺𝗼𝗱𝗲𝗹 𝘁𝗮𝗸𝗲 𝗮𝗰𝘁𝗶𝗼𝗻”
Agents operate in a loop: observe → plan → act → repeat, often using tools and memory. Use them when your problem requires multi-step reasoning, tool usage with verification, or full task execution. Agents start where RAG stops, turning decisions into actions and outcomes.
The simple mental model:
RAG → knowledge layer
MCP → tool layer
Agents → execution layer
Not every system needs all three explicitly, but complex ones often combine them.
If you want to see what this looks like in practice, this guide walks you through building a scalable multi-agent RAG system.
Check it out: lucode.co/multi-agent-ra…
What else would you add?
♻️ Repost to help others learn AI.
🙏 Thanks to @Oracle for sponsoring this post.
Anthropic just introduced the Claude Architect Certification — and it’s not easy.
60 questions.
5 competency areas.
One sitting. No breaks. No external help.
Here’s a simple roadmap to prepare:
Week 1 — Foundations
• Claude API
• Model Context Protocol (MCP)
• Claude Code
• Claude 101
Week 2 — Build
• Claude Code
• Agent SDK
• Anthropic API
• MCP
Week 3 — Understand the Exam
• Exam scenarios
• Competency areas
• Required skills
Week 4 — Practice Systems
• Multi-tool agent with escalation
• Team workflow setup
• Data extraction pipeline
• Multi-agent research system
Week 5 — Test Yourself
Practice exam → Target 850+
Week 6 — Final Attempt
One attempt. Be ready.
A few notes:
• Early access is limited to partners
• Prep time varies (2–10 weeks depending on skill level)
If you’re eligible, register here:
anthropic.skilljar.com/claude-certifi…
This isn’t just a certification.
It’s a signal of how seriously you build with AI.
Announcing: EmDash, the WordPress spiritual successor built for the modern web.
TypeScript. Serverless. MIT licensed. x402 for agent-era monetization. MCP server built in. Deploy to Cloudflare or anywhere Node.js runs.
Imports your existing WordPress site in minutes.
npm create emdash@latestblog.cloudflare.com/emdash-wordpre…
New Nvidia paper proposes a cheaper way to train AI agents by learning only from the moments that matter most.
The big deal is that this keeps much of RL’s benefit for agent quality and general skill retention, but cuts rollout cost enough to make large scale agent post-training far more practical.
The problem is that supervised fine tuning is cheap but often hurts skills outside the training tasks, while full multi-turn reinforcement learning keeps those skills better but is very expensive because every update needs fresh rollouts through the environment.
PivotRL starts from existing expert trajectories, then finds pivot turns where sampled next actions sometimes work and sometimes fail, because those mixed moments carry the strongest learning signal.
It also rewards any action that is functionally correct instead of demanding an exact text match to the demo, which fits agent tasks where many different tool calls, searches, or code edits can all be valid.
The authors tested it on 4 agent settings, conversational tool use, coding, terminal control, and web browsing, and also checked whether general abilities stayed intact on tasks outside those domains.
Compared with standard fine tuning on the same data, PivotRL delivered 14.11 average in-domain points over the base model versus 9.94 for fine tuning, while keeping outside-task change near 0 at 0.21 instead of a 9.83 point drop.
On SWE-Bench it reached similar accuracy to full trajectory RL with 4 times fewer rollout turns and 5.5 times less wall clock time, which makes large scale agent training much more practical and explains why NVIDIA used it in Nemotron-3-Super-120B.
----
Paper Link – arxiv. org/abs/2603.21383
Paper Title: "PivotRL: High Accuracy Agentic Post-Training at Low Compute Cost"
@SaraDiscovers Students using agents for exams is going to be the new normal. The real skill gap is knowing when the agent is hallucinating vs when it’s actually right. How do you teach that?
The CS Student Paradox:
Assignment: "Write a linked list from scratch."
Me: Uses an AI agent to build a perfect implementation in 2 seconds.
The Exam: Is on paper. No AI. No Google. Just me and a pen.
Realizing my brain is now just a "Prompt-to-Speech" engine. 🧠💨
Anyone else feeling the AI dependency struggle this semester? 👇
@GithubProjects Turning docs into a production-ready agent is the dream. One tip that helped me: add a mandatory grounding step so the agent can’t hallucinate features that don’t exist in the actual docs.
@rronak_ Agent harnesses being too human-designed is such a good call. Letting the LLM run the harness itself feels like the natural next step. What’s one SOP you’d love to see an agent execute dynamically?
I have long felt that agent harnesses - even claude code - are too restrictive, because they are still designed by humans.
New paper for Tinsghua and Shenzhen says, what if AI itself runs the harness, rather than defining it in code? Given a natural language SOP of how an agent should orchestrate subagents, memory, compaction, etc., we can just have an LLM execute that logic! (And AI could design that SOP dynamically and depending on the task too)
It's a bit mind-warping to think about, but genius once it clicks.
Makes you wonder how else we should be designing AI systems as we can start consuming more and more tokens
@hanakoxbt I’ve seen similar setups hallucinate bad decisions when they lack grounded data sources. How did you handle tool reliability across all 8? Impressive.
i built an MCP orchestrator with 12 servers and 8 trading agents
+$1,129 hit the wallet before my alarm went off.
1,080 trades. zero human input. i didn't touch anything.
MCP is a USB port for AI.
plug in a server - Claude talks to it. no code. no setup.
i plugged in 12.
Helius. Dune. Phantom. CoinMarketCap.
CoinGecko. Browser MCP. Git MCP. BNB Chain.
arb-scanner found a price gap on Solana - Dune confirmed on-chain - Phantom executed the swap. +$343.
pump-sniper tracked new tokens through Helius - CoinGecko checked liquidity - Browser MCP scraped socials for red flags. 283 trades. +$532.
spread-farmer posted both sides through Polymarket CLOB. 89 trades. 97% win rate. +$288.
whale-tracker pulled Dune data, flagged unusual wallet - copy-trader mirrored the position through Phantom. +$461 combined.
news-edge used Git MCP to read sentiment repos - cross-referenced with CoinMarketCap Fear & Greed - entered before the crowd. +$188.
> 1,080 trades total.
> win rate 70.1%.
> sharpe 2.59.
> P&L curve never dipped.
all 8 agents talk to each other through MCP.
one finds the signal. another confirms. third executes.
i watched from bed.
copytrade the agents: @1743116" target="_blank" rel="nofollow noopener">kreo.app/@1743116
either you automate, or you get automated.
@RoundtableSpace This MCP approach for creative agents is fire 🔥 The sprite animation loop is exactly the kind of real tool-use that makes agents feel alive. What’s the biggest pain point you hit when chaining tools like this?
AI AGENTS CAN NOW CREATE AND ANIMATE SPRITES FOR YOUR VIBE CODED GAME.
Connect an MCP capable agent, tell it what to make, and it can generate, inspect, and regenerate assets until they’re right.
Most AI agents don't know what they don't know.
That's not a philosophy problem. It's an engineering one.
Ground them in real sources or don't trust the output.
I open-sourced PaperPlain. Find the repo here: github.com/sulmatajb/pape…
The exact 3-line prompt you add to your system prompt:
“From now on:
1. Never cite or reference any paper unless you first call the fetch_paper tool via the PaperPlain MCP server.
2. Always return the exact DOI, title, year, and a direct quote or abstract excerpt you’re basing your answer on.
3. At the end, show the complete audit trail of every tool call.”
Works instantly. Zero extra setup.
Agents are great at reasoning… until they just make up a paper 😅
I got tired of it, so I made this dead-simple 3-line prompt that forces any agent (Claude, Grok, Cursor, whatever) to call my PaperPlain MCP server and only cite real papers from 200M+ peer-reviewed sources.
Copy-paste it and watch the hallucinations disappear.
@bnafOg Exactly. The audit trail is the most critical part of the pipeline. Forcing the agent to use fetch_paper guarantees you see the exact DOI and abstract it reasoned from. You get complete visibility into the retrieval layer. Are you using MCP for your own agents right now?
@besi910 The grounding problem is underrated. Most agent failures in research tasks aren't hallucination — they're confident extrapolation from training priors. An MCP-connected literature layer flips the failure mode: now you can audit what the agent actually cited vs. invented.
Agents are excellent at reasoning. They are not always good at knowing what is real.
I built PaperPlain, a free open-source MCP server giving any AI agent access to 200M+ peer-reviewed papers across PubMed, ArXiv, and Semantic Scholar.
github.com/sulmatajb/pape…