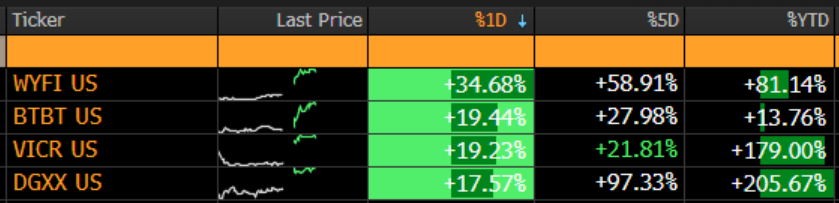
Jared L Kubin@JaredKubin
Vibe Valuation 101: $NBIS
*This is for illustrative purposes only and not investment advice*
First, this name has very little coverage (green flag for me). Second, this deal is massive. I expect all the idio L/S guys to pick it up now (yellow flag). THESE are the big opportunities in the market beyond a day 1 move. You are never late.
Its easy to say "valuation doesn't matter in this environment so why do the work", that's weak sauce and amateur hour. I am NOT close to the name and have never talked to mgmt, what I get wrong... point it out & we can vibe together.
What are the 4 key facts of this deal? From my agent Stanley:
- The agreement has a five-year term and provides Microsoft access to dedicated GPU infrastructure
-Deployment will roll out in tranches during 2025 and 2026.
-Total contract value is about $17.4 billion through 2031, with options that could raise it to about $19.4 billion if Microsoft acquires additional services/capacity.
-If Nebius misses agreed delivery dates for a GPU tranche and can’t provide alternative capacity after a grace period, Microsoft may terminate that GPU Service; either party can also terminate for cause (e.g., unremedied material breach) or certain insolvency events (with a Chapter 11 reorganization carve-out).
Here is 3 diff ways to look at it:
1. First: What is the incremental impact to GM $'s? +$8.5bn?(on track for ~$360m this year) is a first guess... more work talking to mgmt + sensitivity tables would be next to get more conviction on pace of growth + expense schedule (I have no idea)
2. Break into 2 segments and EV/Sales (quick and dirty for day 1-5 move). Core business + MSFT Business now. What multiple do people on the 2 businesses vs peers? That's the art
3. Hard: If I had more time I would try to figure out via old school primary research (next 12-18 month move)
- Full MSA + GPU Services SOWs; effective dates, tranche schedule (MW/GPU counts), energization and acceptance milestones
- Pricing schedule by segment: GPU/hr (by SKU), storage GB/mo, network egress, managed services; indexation/escalators; FX currency
- Commitments: take or pay minimums, burst capacity rules, overage pricing, prepayments/deposits
- SLA & credit schedule, service credits’ cash vs. non-cash treatment
- Change orders / expansion options, volume caps, MFN/exclusivity/MFN clauses
-EPC contracts, site/land, shell/core/fit out budgets, electrical & mechanical line items, network/optics, racks, software licenses
-Payment milestones, vendor prepayments, warranties, liquidated damages
-IDC (interest during construction) methodology, contingency and escalation
-Termination/penalty mechanics (grace periods, cure rights), make-good obligations
-Pass-throughs (e.g., power costs, carbon fees) and who bears curtailment risk
* I would have the ANALYST DO A DETAILED REV BUILD
** MY FOCUS would be on the risks
- Delivery/energization slippage per tranche
- Utilization ramp distributions (P95/P50/P5)
- Power-price/PUE stochastic paths (hedge effectiveness)
- SLA credit frequency/severity
- Contractual option events: expansions, terminations, make-goods
I would compare a Reverse DCF of current prices to our forward expectations. The wider those are, the more I would own. The more narrow those are, the less I would own from a risk standpoint.