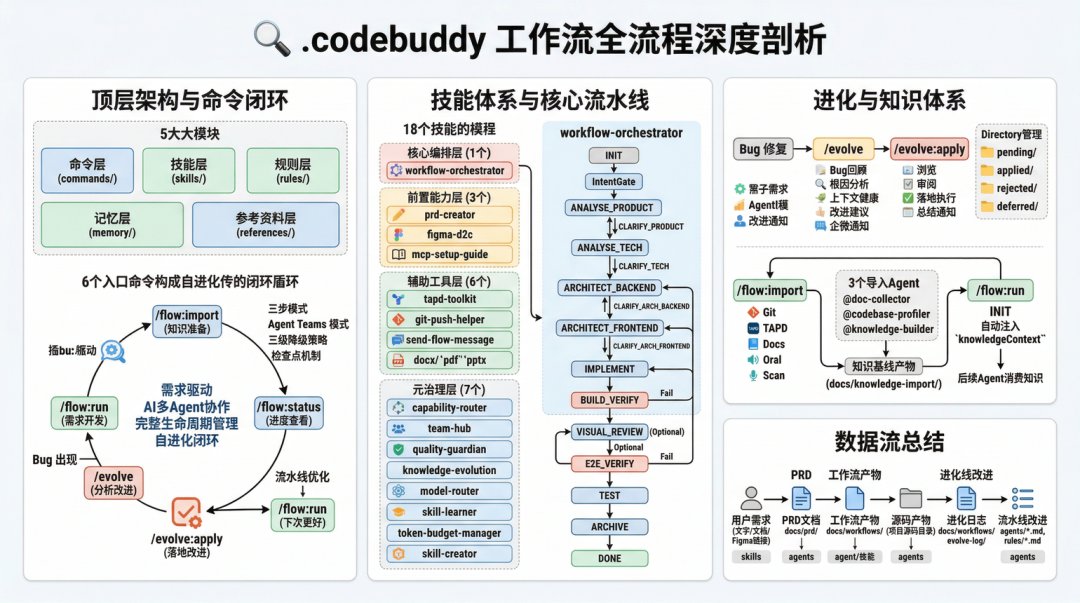
Sakana AI@SakanaAILabs
Introducing our new work: “Learning to Orchestrate Agents in Natural Language with the Conductor” accepted at #ICLR2026
arxiv.org/abs/2512.04388
What if we trained an AI not to solve problems directly, but to act as a manager that delegates tasks to a diverse team of other AIs?
To solve complex tasks, humans rarely work alone; we form teams, delegate, and communicate. Yet, multi-agent AI systems currently rely heavily on rigid, human-designed workflows or simple routers that just pick a single model. We wanted an AI that could dynamically build its own team.
We trained a 7B Conductor model using Reinforcement Learning to orchestrate a pool of frontier models (including GPT-5, Gemini, Claude, and open-source models available during the period leading up to ICLR 2026).
Instead of executing code, the Conductor outputs a collaborative workflow in natural language. For any given question, the Conductor specifies:
1/ Which agent to call
2/ What specific subtask to give them (acting as an expert prompt engineer)
3/ What previous messages they can see in their context window
Through pure end-to-end reward maximization, amazing behaviors emerged. The Conductor learned to adapt to task difficulty: it 1-shots simple factual questions, but autonomously spins up complex planner-executor-verifier pipelines for hard coding problems.
The results are very promising: The 7B Conductor surpasses the performance of every individual worker model in its pool, setting new records on LiveCodeBench (83.9%) and GPQA-Diamond (87.5%) at the time of publication. It also significantly outperforms expensive multi-agent baselines like Mixture-of-Agents at a fraction of the cost.
One of our favorite features: Recursive Test-Time Scaling! By allowing the Conductor to select itself as a worker, it reads its own team's prior output, realizes if it failed, and spins up a corrective workflow on the fly. This opens a new axis for scaling compute during inference.
This research proves that language models can become elite meta-prompt engineers, dynamically harnessing collective intelligence.
Alongside our TRINITY research which we announced a few days earlier, this foundational research powers our new multi-agent system: Sakana Fugu! (sakana.ai/fugu-beta) 🐡
OpenReview: openreview.net/forum?id=U23A2… (ICLR 2026)