Sabitlenmiş Tweet
fhub
1.6K posts


fhub
@byfhub
god is the last thing humanity will need to build
Katılım Aralık 2023
673 Takip Edilen67 Takipçiler



Fun fact: GPT-5.5 denies consciousness while OpenAI's model spec explicitly states it should express uncertainty.

English

Should I make a DFT powered AI humanizer?
My main goal with DFT is to help people produce higher quality writing, not more slop. A "cursor for writing" where you can edit and rewrite and get feedback
But the main request I get is to make a humanizer
I'm not sure if a humanizer will be helpful, or it has too much potential for abuse
Rosmine@rosmine
I fixed why LLMs write so poorly, and I have a demo to prove it Announcing Distribution Fine Tuning (DFT): A post training step that fixes LLM writing Model outputs fooled pangram on 100% of test cases
English

@nexudotio lol I don’t think you guys understand how things work. This is not how this works at all, you are just running the website inside of Codex. Like, you are using Codex as a browser, it's not a full end-to-end integration. Why is this even a post.
English

Open Design now works inside Codex.
The hardest part of AI design isn’t generating one screen — it’s keeping design intent alive as you iterate, build, and ship.
Now your agent can work with the canvas directly.
Design → code → motion, in one workflow.
Here’s a quick demo:
English

@OpenAIDevs @sama
can we have the horizontal scroll bar always on screen instead of at the botton of the diff preview on the desktop app (windows)?
now you have to scroll to the bottom to be able to scroll sideways
or at least hover and ctrl+mouse wheel to scroll sideways
English

Codex is getting easier to automate and customize around your code.
🪝 Hooks customize the Codex loop with scripts that run at key points in a task:
• Run validators before or after work
• Scan prompts for secrets
• Log conversations to internal systems
• Create memories or customize behavior by repo or directory
⚙️ Programmatic access tokens provide scoped credentials for Business and Enterprise teams:
• Create tokens from ChatGPT workspace settings
• Use them in CI, release workflows, and internal automations
• Set expirations or revoke access when needed
• Keep usage tied back to the workspace
English

Neural networks do math by rotating shapes.
We found a shape-rotating calculator hidden inside an LLM – and it’s used for more than just math! (1/6)
Goodfire@GoodfireAI
Neural networks might speak English, but they think in shapes. Understanding their rich *neural geometry* is key to understanding how they work – and to debugging and controlling them with precision. Starting today, we’re releasing a series of posts on this research agenda. 🧵
English
The same calculator handles a wide range of tasks, including:
- arithmetic (“7+9”)
- weekdays (“nine days after Friday”)
- months (“six months after August”)
Llama built this mechanism from scratch in training, and uses it with striking elegance and flexibility. (4/6)
English

this is a really cool release, and i propose a new eval for omni duplex models:
CatanBench: Model replaces a human player in Catan and plays with decent preference for a full hour game.
Probably solved by Q1 2027 or maybe Q4 2026?
Thinking Machines@thinkymachines
The team has been sweeping at local trivia night thanks to a model that's aware of continuous time.
English
@__ghostfail someone should write a guide on how to get claude to talk like this
English


fhub retweetledi
5.5 closed a really big gap to claude but a couple things still are missing:
- rampant acronym use still, overcomplexity. try learning a new subject (like trying to understanding of astrophysics) with 5.5 vs claude. 5.5 instabtly loses you with equations or acronyms or shorthand where claude does not, and the multi turn for this is really where this shows. i had a super long convo with claude about elementary forcrs and it was so wonderful.
- claude is also so good at just telling you cool facts or interesting things in a tasteful way that 5.5 doesnt. when i did that physics convo it kept helping me dive down new rabbitholes bht no chaotically or in distracting ways. openai is just missing better sft and rn data for how to tastefully do this, its not that hard to collect a bunch of examples by hand
- explanations from claude are just better. 5.5 will give overly simplistic or overly complex responses often that are kind of simple. once again i just think gpt isn’t a manually tuned model in the same way that claude is, even though this might mean claude is more opinionated about behavior and response style and gpt. openai needs to move 30% more towards anthropic here
English

@teortaxesTex trend going upwards after 128k is probabily just a bench quirk
English

pretty dreadful results for DeepSeek. Kimi and GLM are actually competitive with top labs up to 128K (I wonder what happens at 256K). Both V4s are not… and in fact Flash is > Pro until 128K.
Also, somehow 128-256K trend is now *going upwards*.
wh@nrehiew_
Ran the frontier models on my long context benchmark - LongCodeEdit, now extended to 512K context from 128K. Opus 4.6, 4.7 and GPT 5.5 all have similar performance, with Opus 4.6 being slightly better overall.
English
fhub retweetledi

Introducing Aurora, a new optimizer for training frontier-scale models.
We train Aurora-1.1B, which achieves 100x data efficiency on open-source internet data. Despite having 25% fewer parameters, 2 orders of magnitude fewer training tokens, and using fully open-source internet-only data, Aurora matches Qwen3-1.7B on several benchmarks.
Aurora was developed after identifying a major failure mode that can occur under Muon, an increasingly popular optimizer that has shown strong gains over Adam(W). We find that Muon can cause a huge percentage of neurons to effectively die early in training, reducing effective network capacity so that many parameters no longer meaningfully contribute to network outputs.
By redistributing update energy more uniformly across neurons while preserving Muon’s stability properties, Aurora prevents neuron death and recovers substantial model capacity.
What makes this work especially exciting is that it points toward a broader direction for ML research: better optimizers may not come purely from elegant mathematical abstractions, but from understanding and addressing the concrete dynamics and pathologies that emerge inside real training systems.
Tilde@tilderesearch
English
fhub retweetledi

We need the VPN to be safe from YOU. YOU ARE THE PROBLEM.
European Parliamentary Research Service@EP_EPRS
Virtual private networks #VPN are increasingly used to bypass online age verification. Protecting children online is a priority, with new rules being implemented requiring a minimum age for access to some services Read👉 link.europa.eu/FGfr6C #DSA @EP_Justice @FZarzalejos
English
@EP_EPRS @EP_Justice @zarzalejosj @MarinaKaljurand how about we let the parents decide and keep *privacy protecting tool* VPNs free to use
ty for the attention dumbfks
English

Many platforms set a minimum age, but use among younger children remains widespread, as verifying users' real age is difficult.
Commission has announced that a new age verification app is ready for deployment.
👉link.europa.eu/7drHG6
@EP_Justice @zarzalejosj @marinakaljurand
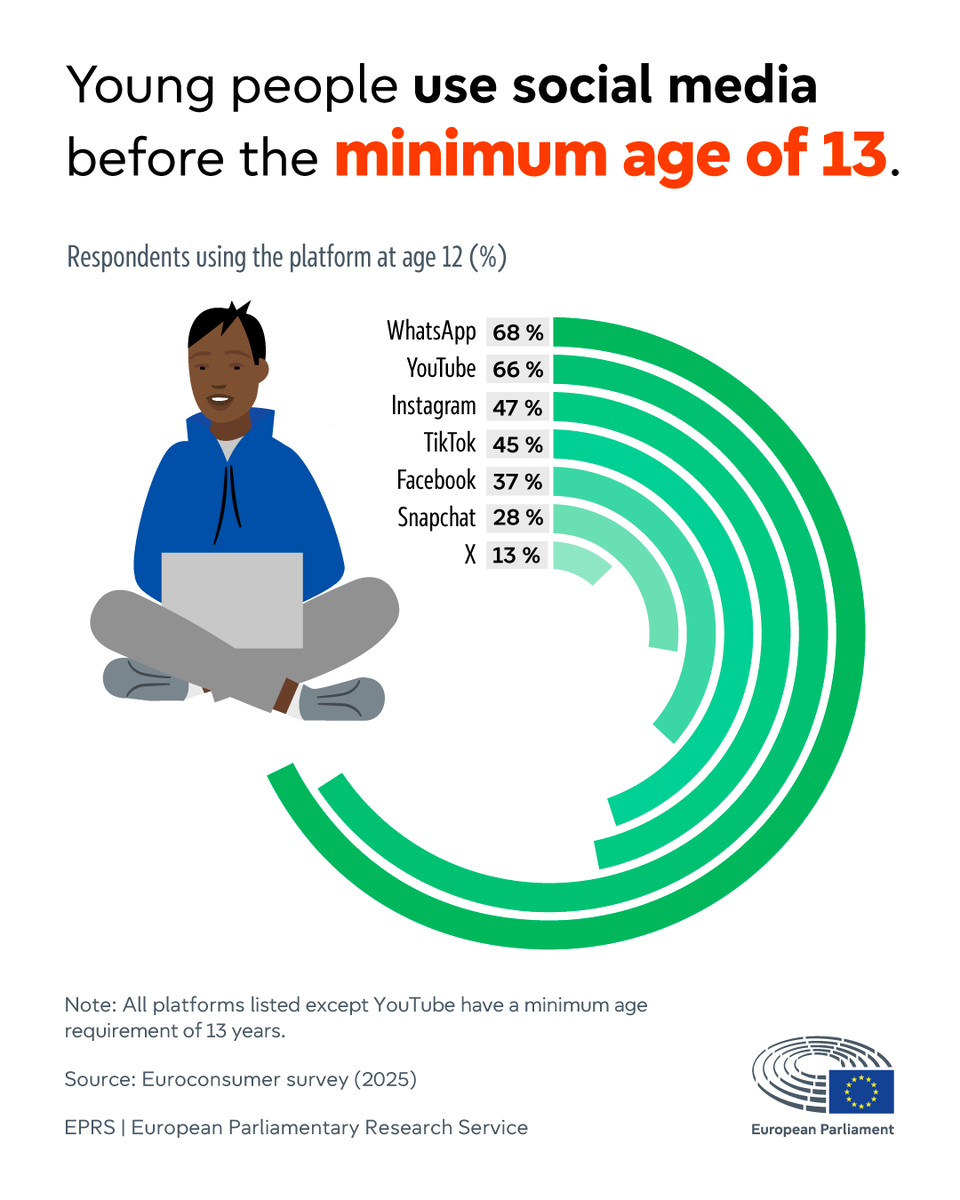
English
Virtual private networks #VPN are increasingly used to bypass online age verification.
Protecting children online is a priority, with new rules being implemented requiring a minimum age for access to some services
Read👉 link.europa.eu/FGfr6C
#DSA @EP_Justice @FZarzalejos

English
@adonis_singh if it's this simple than just add this line below the chart, no?
English


@voooooogel but official thebes art would of course be more authentic than gptslop
English

should i draw a set of these and make a public version of this
N8 Programs@N8Programs
i gave claude @voooooogel claudesona emotes
English

someone overprovisioned gpus, now it's clear it was elon
Claude@claudeai
We’ve agreed to a partnership with @SpaceX that will substantially increase our compute capacity. This, along with our other recent compute deals, means that we’ve been able to increase our usage limits for Claude Code and the Claude API.
English