c_Up1d
32 posts


我Steam里有800多个游戏(图2),
强烈推荐对 游戏+AI化 感兴趣的人,
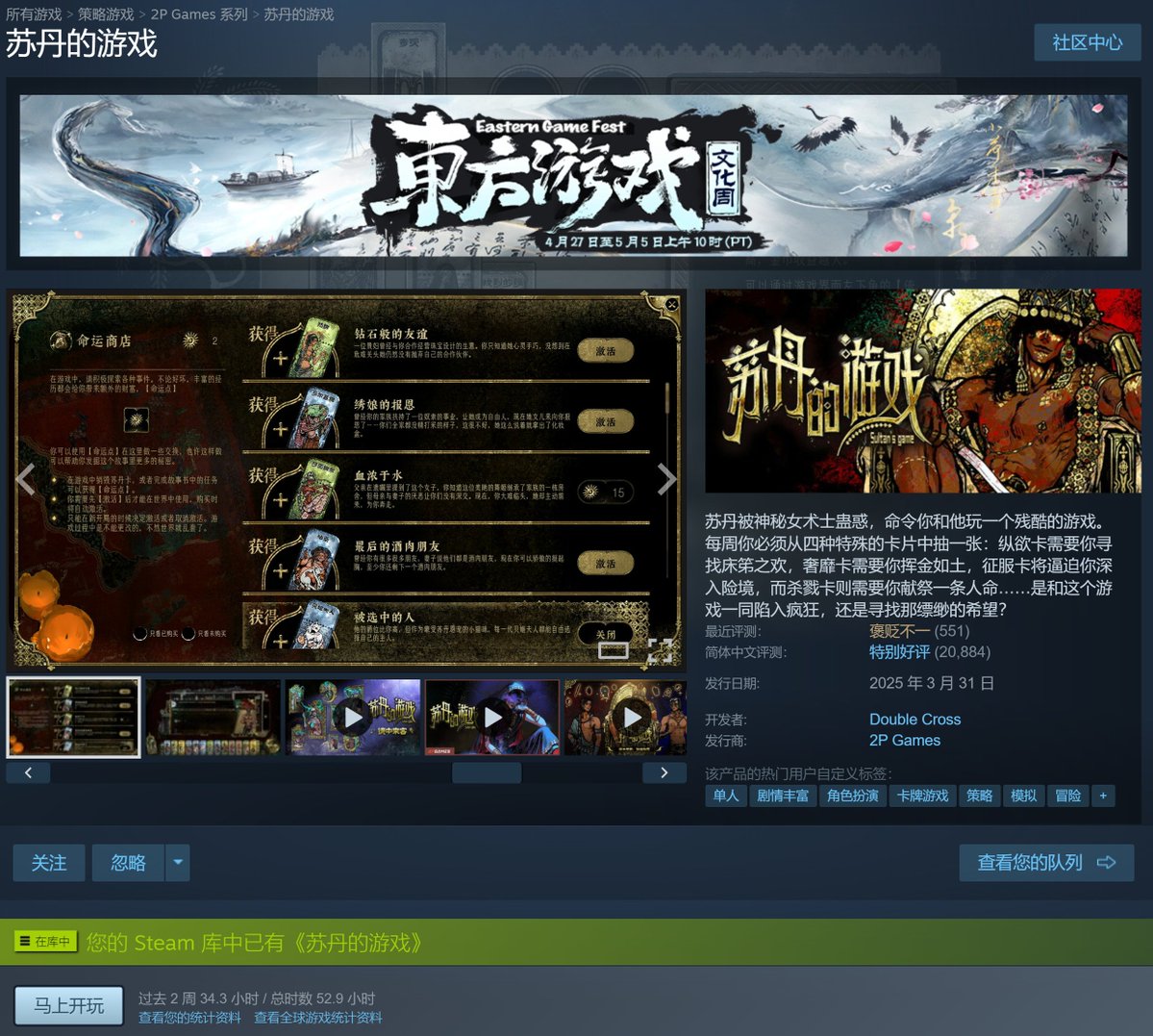
玩一下《苏丹的游戏》(图1,Win/Mac都有)
1. 是我近一年玩过最与众不同的游戏。
2. 是国产游戏,但题材背景却是中世纪中东。
3. 文字演绎,但自由度前无古人,尺度无下限。
游戏通过每回合,在不同场景,
打出不同的人物、道具等卡牌,来推进剧情。
举例:
在某野外场景,遇到一头“犀牛”,
那么如果你打出“主角+纵欲”二张卡,
这三张卡就会组合产生一些无下限的剧情...
而且同样的场景、卡牌组合,还根据骰子检定变化,
比如这头犀牛可能是先死了,然后...(不能说了)
你的任何一次行为,
都可能对游戏剧情产生千丝万缕的影响,
导致数不清的交叉后果、分支和结局。
重点来了:
暗黑无下限只是表面,重点是这个自由度,
和这个游戏玩法模式,
意外地是一个极佳的AI化“底座”。
通常我们谈到游戏+AI,
往往是用AI来做游戏,
本质上只是在说Vibe Coding游戏软件而已。
而游戏AI化,则完全是不同的其他几种语境
比如:
1. 像《燕云十六声》里NPC对话、次要行为由AI生成
2. AI实时生成游戏画面
但这两种
1不是游戏主线玩法
2估计还需要几年发展才可做可玩
而《苏丹的游戏》,
其主线玩法就是文字,
作为主要甚至唯一驱动,和表现形式。
你可以理解为
“互动文字小说+RPG+卡牌”,
但其剧情本质还是If-Else构成
(虽然光靠If-Else都实现了数不清的故事线)。
如果用AI来改造这个独特的游戏类型,
就能做出,或者魔改出
一款完全由AI来实时驱动“无限剧情”走向的游戏,
这会是最快能诞生此类次世代AI游戏的路径,
原因是:
这类游戏的核心反馈,也就是无限变化的剧情产出,
不需要用图片、视频素材形式来交付,只需文字。
加上,此游戏核心玩法中的“出牌”组合,
本质上就是AI生成剧情的“提示词”组合,
这就完美契合了当下大语言模型已充分成熟的能力阶段。
甚至B站还有此游戏完整WIKI资源数据库可供取用:
wiki.biligame.com/sultansgame
从玩家角度来说,
这个游戏类型和玩法,虽说独特,
但却绝不算是小众游戏,
《苏丹的游戏》作为一款国产游戏,
在Steam上有2万多“特别好评”。
我以Steam库800多个游戏履历担保:
1.
即使你对AI没什么兴趣,
只要喜欢卡牌/RPG,甚至只是爱看小说,
这个游戏非常适合,新颖体验且耐玩度极高。
2.
而对AI驱动游戏的未来形态感兴趣的人来说,
这是真正的AI游戏到来之前,
此刻马上就能获得类似体验的尝鲜。
3.
而对于更进阶的个人Vibe Coder,
想要尝试不仅仅是Vibe做一个游戏,
而是做一种,
既是市面上还没有的创新游戏,
也是已有广泛玩家数基础,同时运行性能需求低,
玩法机制定义边界清晰,开发门槛低的尝试。
那么先至少体验一下它,
一定能获得很大的启发。

中文




@ZechenZhang5 @orch_research Huge shoutout to Zechen for building this. It's genuinely one of those tools that makes you wonder how you ever got by without it. Beyond just a nice utility, orchestra is a whole research workflow in one place. This is going to save researchers a ton of time.
English
c_Up1d retweetledi

Every developer has an IDE. Researchers never had one.
We don’t need another research agent, but a full stack workstation powered by AI.
Today we're launching Orchestra @orch_research, the world's first Research IDE 🔬🧵
English



@Sinda1118 您好,感谢您的分享,我想探讨关于就业数据失真会影响政策这点。如果能够及时调整统计口径或更新就业评价指标是否能够缓解您提到的失真?还是说即使数据失真的问题解决了,但是就业结构发生的实质变化还是会影响货币和财政政策?如果会的话,我们可以提前做哪些准备呢?
中文

@ZechenZhang5 It is lamentable that this seems extremely difficult to achieve through post-training alone; one can only hope that future research versions will once again restore the glory of these large-parameter models.
English
@c_up1d Yeah or the bigger question is: is meta cognition possible via the exiting post training pipelines? I suppose we need larger pretrained models for this, eg. I always think of how good gpt 4.5 is in its delicate thinking
English
why opus 4.6 seems very dumb on meta cognition (eg. designing prompts for agents), is this model particular or just a bug of deep learning
English
@ZechenZhang5 I reckon it a strategy of model manufacturers, GPT5 vs GPT4, and Gemini 3 Pro vs 2.5 Pro. Programming users can bring higher revenue, while retaining the parameters required for metacognitive abilities incurs significant inference costs.
English
@ZechenZhang5 focus on context length and multi agent ability while sacrifice writing/meta cognition. Like a codex model
English