Chris Hayduk@ChrisHayduk
I'm rebuilding AlphaFold2 from scratch in pure PyTorch.
No frameworks on top of PyTorch. No copy-paste from DeepMind's repo. Just nn.Linear, einsum, and the 60-page supplementary paper.
The project is called minAlphaFold2, inspired by Karpathy's minGPT. The idea is simple: AlphaFold2 is one of the most important neural networks ever built, and there should be a version of it that a single person can sit down and read end-to-end in an afternoon.
Where it stands today:
- ~3,500 lines across 9 modules
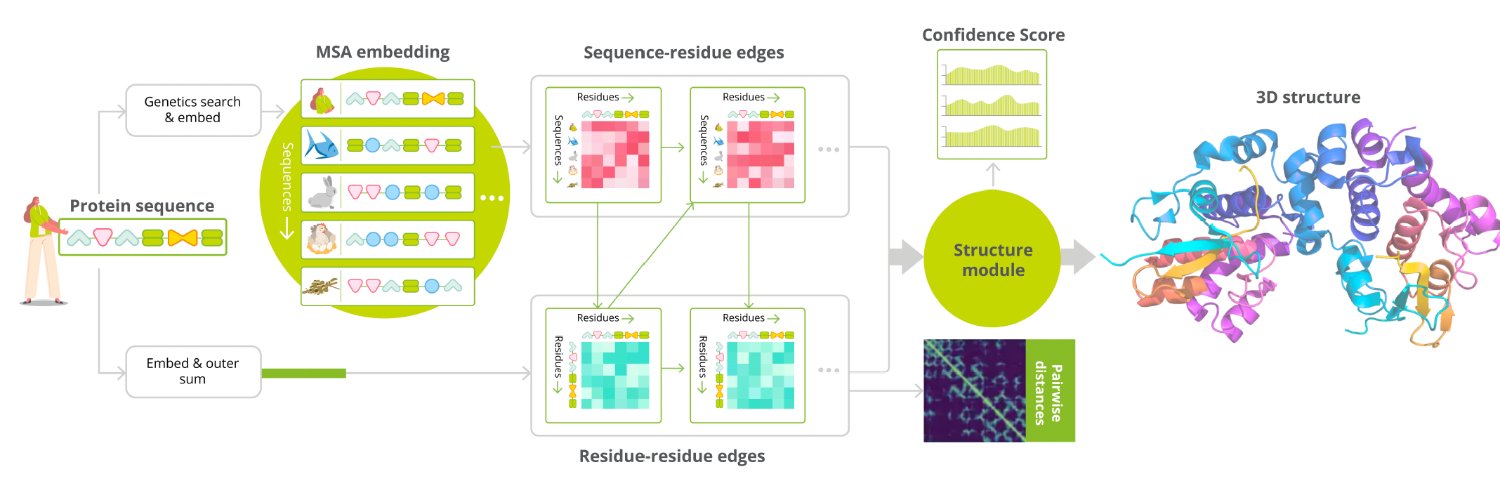
- Full forward pass works: input embedding → Evoformer → Structure Module → all-atom 3D coordinates
- Every loss function from the paper (FAPE, torsion angles, pLDDT, distogram, structural violations)
- Recycling, templates, extra MSA stack, ensemble averaging — all implemented
- 50 tests passing
- Every module maps 1-to-1 to a numbered algorithm in the AF2 supplement
The Structure Module was the most satisfying part to build. Invariant Point Attention is genuinely beautiful — it does attention in 3D space using local reference frames so the whole thing is SE(3)-equivariant, and the math fits in about 150 lines of PyTorch.
What's next:
- Build the data pipeline (PDB structures + MSA features)
- Write the training loop
- Train on a small set of proteins and see what happens
The repo is public. If you've ever wanted to understand how AlphaFold2 actually works at the level of individual tensor operations, this is meant for you.
Repo: github.com/ChrisHayduk/mi…