@techskunkworks T’en as peut être parlé sur tes autres vidéos. En tout cas J’ai beaucoup appris sur la 1ere heure de ta vidéo. Je vais te suivre pour mieux comprendre la méthode et le comment du pourquoi. Encore bravo
Français
95200.eth 📦 Dans ma zone
904 posts

@crypto_blockg
$GME holder, solopreneur




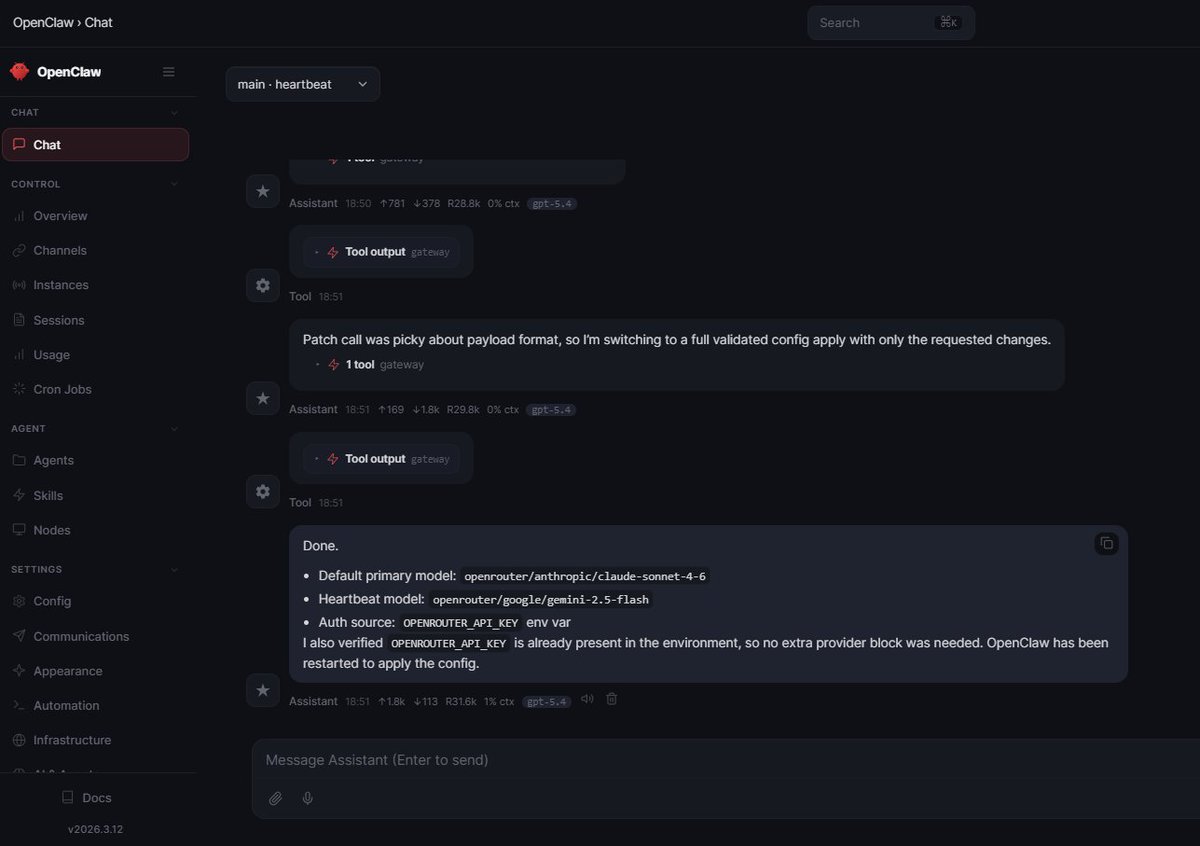











Vous utilisez quel model pour vos agents Openclaw ?

We just open-sourced Paperclip: the orchestration layer for zero-human companies It's everything you need to run an autonomous business: org charts, goal alignment, task ownership, budgets, agent templates Just run `npx paperclipai onboard` github.com/paperclipai/pa… More 👇