
serdarml
122 posts

serdarml
@cs_serdar
Aspiring AI researcher, undergrad student @TU_Muenchen
Katılım Haziran 2020
526 Takip Edilen91 Takipçiler


@jxmnop recalling a needle in a 200k haystack is one thing, but maintaining reasoning across 1M is a different beast entirely. we have the memory capacity, but the attention mechanisms still struggle with the signal to noise ratio at that scale
English

it is endlessly fascinating to me that we still don't have a true 1M-context model
it's an unusual case where the infra is far ahead of the science. Claude discontinued 1M+ context bc it didn't really work past ~200k
we don't have the right data? training techniques? not sure
English
@VictorTaelin I think nobody is able to do this because continual learning is not solved
English

again, suppose you have some bit of knowledge that is mandatory for an agent to operate well in your domain. ex:
> using BigInt in this repo is bad for
you have two options:
Option 1: you make that directly visible (AGENTS.md)
this DOES work if the Agent is good enough. the problem is that may be actually complex, like, 1k tokens worth. so, accumulate enough of these and you easily have 500k tokens of mandatory domain knowledge. including that in any model will immediately downgrade it into GPT-2, and cost a fortune
Option 2: you make that SEARCHABLE (RAG, RLMs, etc.)
the problem is that the AI cannot magically guess when it needs that bit of knowledge. it will not stop writing some JS function and think:
"wait perhaps there is some part of the domain that tells me that BigInts are bad and I should start looking for it?"
it will just use BigInts.
I won't OCCUR to it that there is something to be searched
so:
- make visible: too long to fit
- make searchable: it can't guess
that's why I think nightly fine tuning as a product is the only way forward, as it allows you to extend a model with domain knowledge without causing context rot
why nobody is doing this seriously is beyond me. it might be that for whatever reason this wouldn't be practical, but I suspect the real reason is nobody is seriously considering it
English
seriously, working with AI is MISERABLE for one and only one reason: having to re-explain the same thing
"oh yeah this new session obviously doesn't know what proper case trees are, so let me explain it for the 5000th time in my life"
I'm tired
AGENTS.md doesn't solve this because it is impossible to fit the entire domain knowledge without nuking the context - it would be 1m+ tokens worth
RAGs don't solve this, the agent won't search unknown unknowns
SKILLs don't solve this unless I keep like a collection of 1750 skills with specific cuts of domain knowledge for each possible subset of my domain that I might need in a given chat, but that's a lot of manual work
recursive LLMs or whatever don't solve this for the same reason, you can't dump a domain book and expect the AGENT will magically guess that it is supposed to search for a specific bit knowledge. unknown unknowns
fine tuning doesn't solve this (OSS models suck and OpenAI / Anthropic gave up on user fine tuning)
I honestly think a good product around fine tuning on your domain would be a major hit and an underdog lab should take this opportunity
English
serdarml retweetledi

serdarml retweetledi

this is exactly what Slowrun aims to solve. i think the main problem is not the loss function but the learning algorithm:
- gradient descent massively underutilizes compute relative to the data it's trained on. i think brains use a lot of compute to search for solutions that generalize, rather than doing computationally cheap but unexploratory curve fitting.
- we've already gotten 10x better sample efficiency with Slowrun by pulling on two levers that let us utilize a lot of compute: heavy overparameterization (at least 3600x chinchilla) and multi-epoch training with regularization and data augmentation.
- imo no single architecture or loss function change is going to solve sample efficiency. there's no replacement for spending compute on search.
- humans aren't the ceiling either. current algos and humans are both very far from what's theoretically possible.
Dwarkesh Patel@dwarkesh_sp
There's a quadrillion-dollar question at the heart of AI: Why are humans so much more sample efficient compared to LLM? There are three possible answers: 1. Architecture and hyperparameters (aka transformer vs whatever ‘algo’ cortical columns are implementing) 2. Learning rule (backprop vs whatever brain is doing) 3. Reward function @AdamMarblestone believes the answer is the reward function. ML likes to use pretty simple loss functions, like cross-entropy. These are easy to work with. But they might be too simple for sample-efficient learning. Adam thinks that, in humans, the large number of highly specialised cells in the ‘lizard brain’ might actually be encoding information for sophisticated loss functions, used for ‘training’ in the more sophisticated areas like the cortex and amygdala. Like: the human genome is barely 3 gigabytes (compare that to the TBs of parameters that encode frontier LLM weights). So how can it include all the information necessary to build highly intelligent learners? Well, if the key to sample-efficient learning resides in the loss function, even very complicated loss functions can still be expressed in a couple hundred lines of Python code.
English

GPT-5.5 xhigh feels like the first model I could trust with running ML experiments autonomously. It still lacks certain intuition but the execution is very reliable.
I asked it to experiment on some loss functions and use gpu nodes on our cluster to verify. So far the findings are very promising. I only intervened a few times in the past 3 hours because I saw some "obviously wrong" directions it proposed.
English

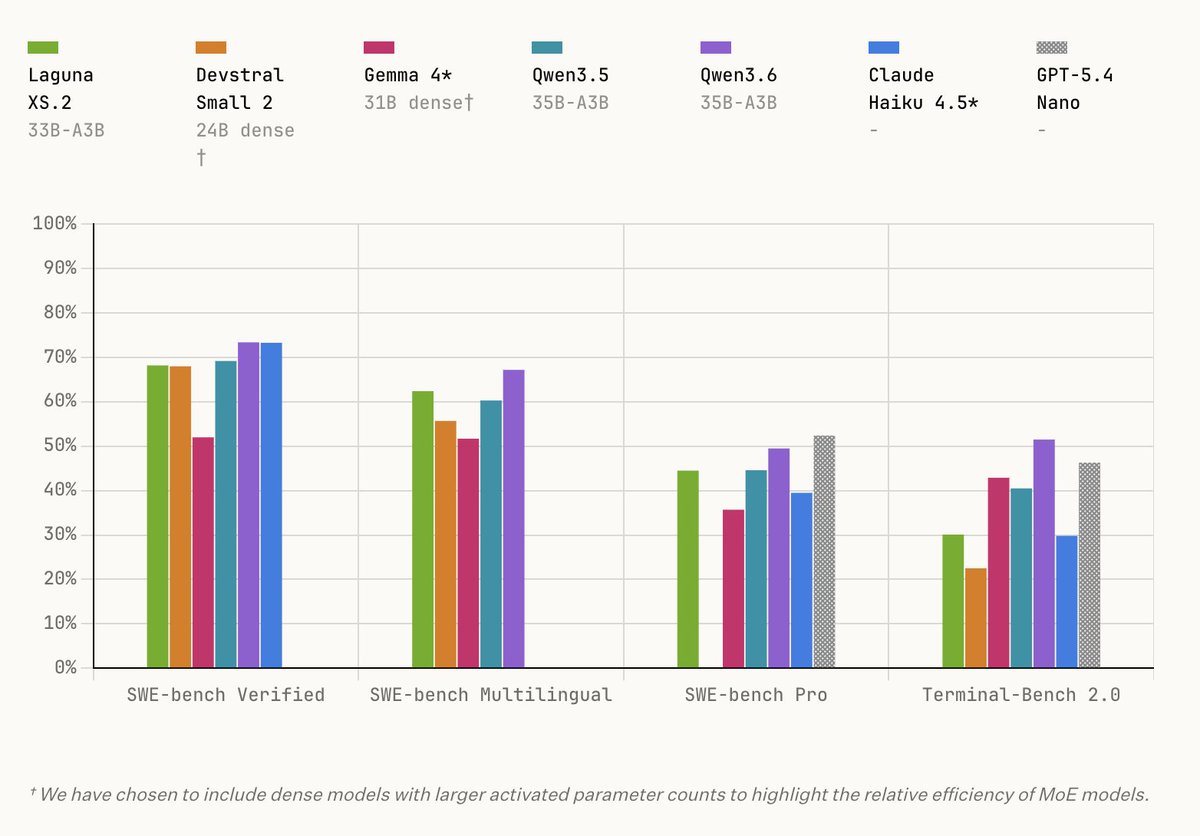
We just released our first models at @poolsideai – including Laguna XS.2 (open weights) that competes with Qwen3.6-35B.
I worked across pretraining — happy to answer questions! We now have great understanding of exactly all components that went into training through principled ablations, and now we're confident to scale.
This year would be 🔥 for us! More coming very soon
English
serdarml retweetledi

Modded-NanoGPT Optimization Benchmark
Hundreds of neural network optimizers have been proposed in the literature, recently including dozens citing Muon: MARS, SWAN, REG, ADANA, Newton-Muon, TrasMuon, AdaMuon, HTMuon, COSMOS, Conda, ASGO, SAGE, and Magma, to name a few.
The majority of this innovation is happening in the public research community. But the community currently lacks a widely accepted, easily accessible way to compare and make sense of the deluge of methods. As a result, promising new ideas get buried, and spurious results go unchallenged.
To help address these issues, I'm releasing a new optimization benchmark. It's designed for maximum simplicity and speed: Just a single file containing ~350 lines of plain PyTorch, which can complete a baseline LM training within 20 minutes of booting up a fresh 8xH100 machine. It also works with {1,2,4}xH100 or A100. These attributes make the new benchmark more accessible than any prior work.
The rules are simple: The optimization algorithm can be changed arbitrarily, with the goal being to minimize the number of training steps needed to reach 3.28 val loss on FineWeb (this is the same target loss as in the main speedrun). Modifying the architecture or dataloader, on the other hand, is not allowed. Wallclock time is unlimited, in order to give a fair chance to optimizers which would need kernel work or larger scale to become wallclock-efficient.
Like the main NanoGPT speedrun, submissions are open, and new results will be publicly broadcast. Beyond just improving the step count record, another goal of the benchmark is to collaboratively produce well-tuned baselines for as many optimizers as possible. For example, any improvement to the benchmark's best hyperparameters for AdamW would be considered a worthwhile new result.
This benchmark is not intended to be the final measure of optimizer quality across all domains. Convenient shared experimental infrastructure which covers the full space of possibilities -- across varying batch size, tokens per parameter, model scale, epoch count, and architecture -- is desirable, but far beyond the current status quo. This benchmark is only meant to be one step towards that goal.
To start the benchmark off, I've spent ~20 runs tuning baselines for Muon and AdamW. From time to time over the next few weeks, I'll add another optimizer from the literature, with my best effort at finding good hyperparameters. Researchers interested in neural network optimization are invited to join in by picking an optimizer and giving it a try on the benchmark. All optimizers are welcome, and even runs that don't necessarily have the best hyperparameters are desirable additions to the repo, because each new run adds to the collective knowledge.

English

It would be very fun to apply all the data augmentation/data effeciency techniques we've learned over the years but weren't applicable to LLMs due to the abundance of data + all the new ones.
dropout, layer looping, massive overparameterization, muon, optimal hparams, etc.
David Duvenaud@DavidDuvenaud
Announcing Talkie: a new, open-weight historical LLM! We trained and finetuned a 13B model on a newly-curated dataset of only pre-1930 data. Try it below! with @AlecRad and @status_effects 🧵
English
serdarml retweetledi

@amigodesupadre @iScienceLuvr There were results showing Qwen models benefit even from random rewards. Shouldn’t be too hard to find.
English


just your friendly reminder to throw away any RL paper that only tests their method on Qwen models :)
English

@teortaxesTex >tfw there was a period of time where Mixtral was the best open weights MoE
English

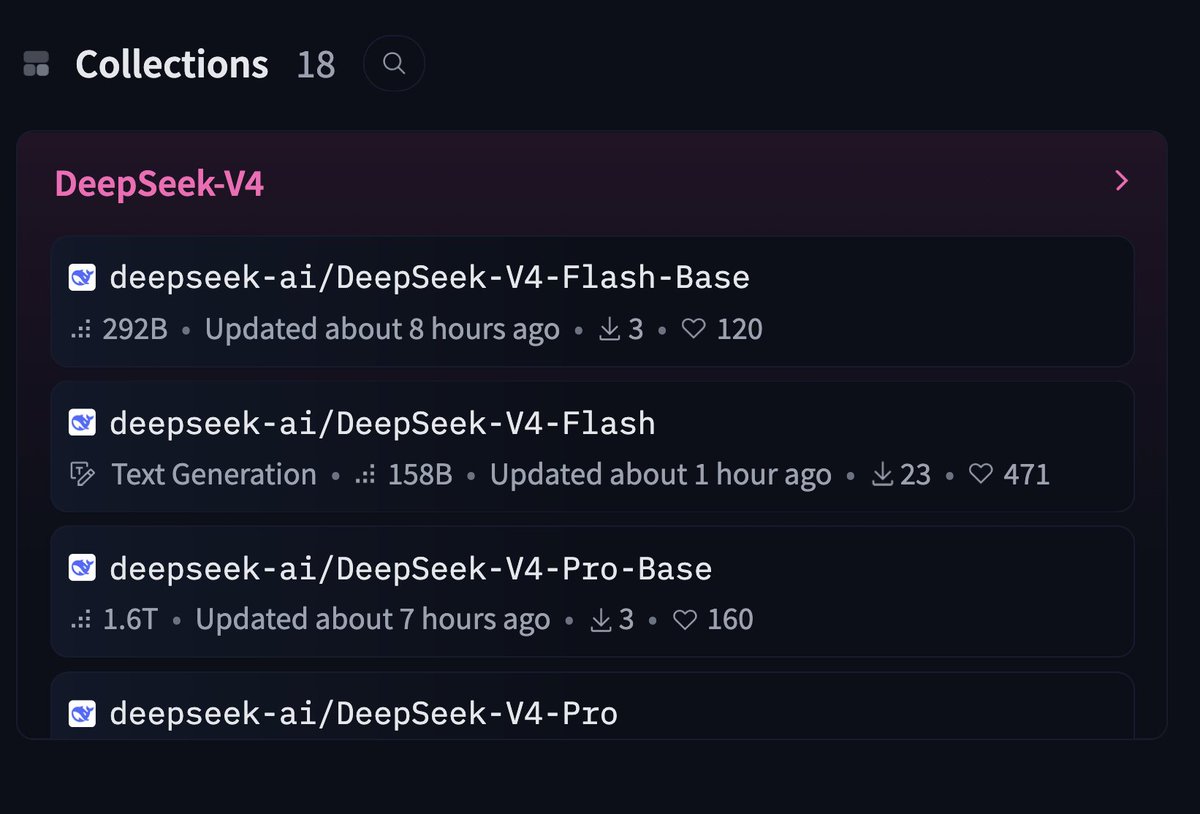
anon do you realize that V4-Pro is straight up the strongest pretrained model we have? Like… 1.6T@49AB (≈280B dense), 33T – even by meme formula it's > LLaMA 3. Add Muon, mHC, most steps 64K context + extended to 1M…
No excuses now. Every "unicorn" can have its brand AGI.
English
serdarml retweetledi

@scaling01 afaik it's going to be a multimodal LLM trained on around 384 h100s
English

oh looks like they are not even doing language models but multimodal stuff and robotics
English
look at Germany go
they are finally ready to compete with Llama-2 7B
Andreas K. Maier@maier_ak
Open Source Bavarian AI Foundation Model is coming soon!
English
Something feels broken about our current learning algorithms. Given unlimited compute, the fitted parameters should not require more bits to describe than the dataset trained on. Yet the frontier of sample efficiency is overparameterization and ensembling.
I believe looping is a step in the right direction, but we need a more fundamental shift than architecture alone. Humans are vastly more sample efficient.
English
@davidsamuelcz @DmitryRybin1 @gklambauer Yet we still don't have any frontier models on a RNN based architecture.
English

@DmitryRybin1 @gklambauer Yes, but doing the same computation is much less efficient when you resort to these extensions.
English

Transformers have limited expressivity, and cannot solve problems of higher complexity, like class P.
Sepp Hochreiter@HochreiterSepp
xLSTM more expressive than transformer, Mamba: arxiv.org/abs/2603.03612 *nonlinear RNNs: sLSTM, LSTM *DPLR linear RNNs: mLSTM, RWKV, DeltaNet *Non PNC1: Mamba, Transformer “fundamental expressivity gaps between linear and nonlinear RNNs” World models require nonlinear RNNs.
English
serdarml retweetledi


