
@natolambert “Within 12 months AI may make up 30% of a F500’s workforce, but within 30 years Nathan Lambert will never be on this panel
English
Chris Griffin
123 posts

@csgriff_
Helping LLM’s to predict the future. Founder. Company not linked here so banter is possible






me and my pal Jensen












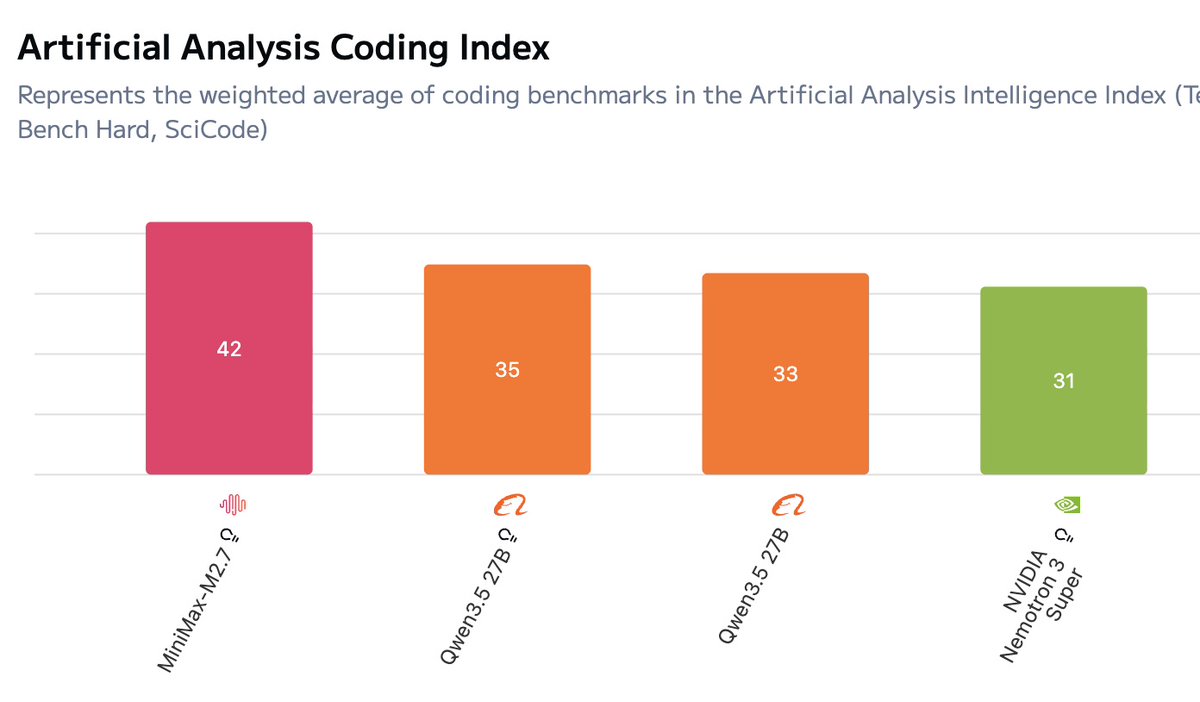
Based on the data I see, I think: - Anthropic🇺🇸/Google🇺🇸/OpenAI🇺🇸 all ~tied - Meta🇺🇸 / xAI🇺🇸 each ~7mo behind - Moonshot🇨🇳/- Deepseek🇨🇳 / zAI 🇨🇳 / Alibaba🇨🇳each ~9mo behind - Mistral🇫🇷 ~1.5 years behind - No other companies competitive







