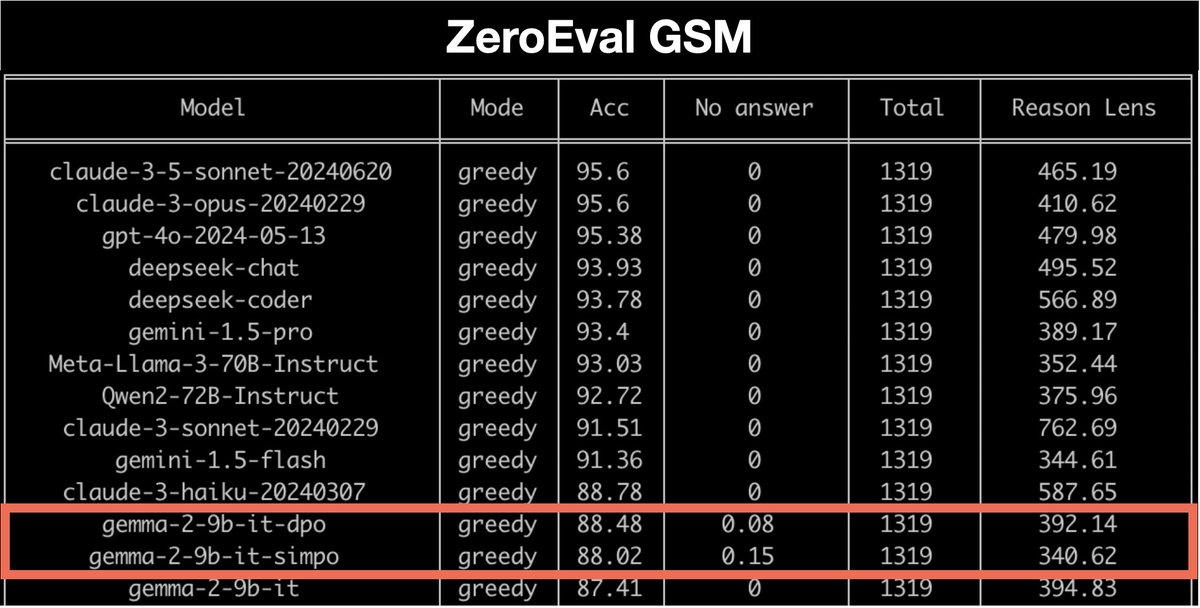
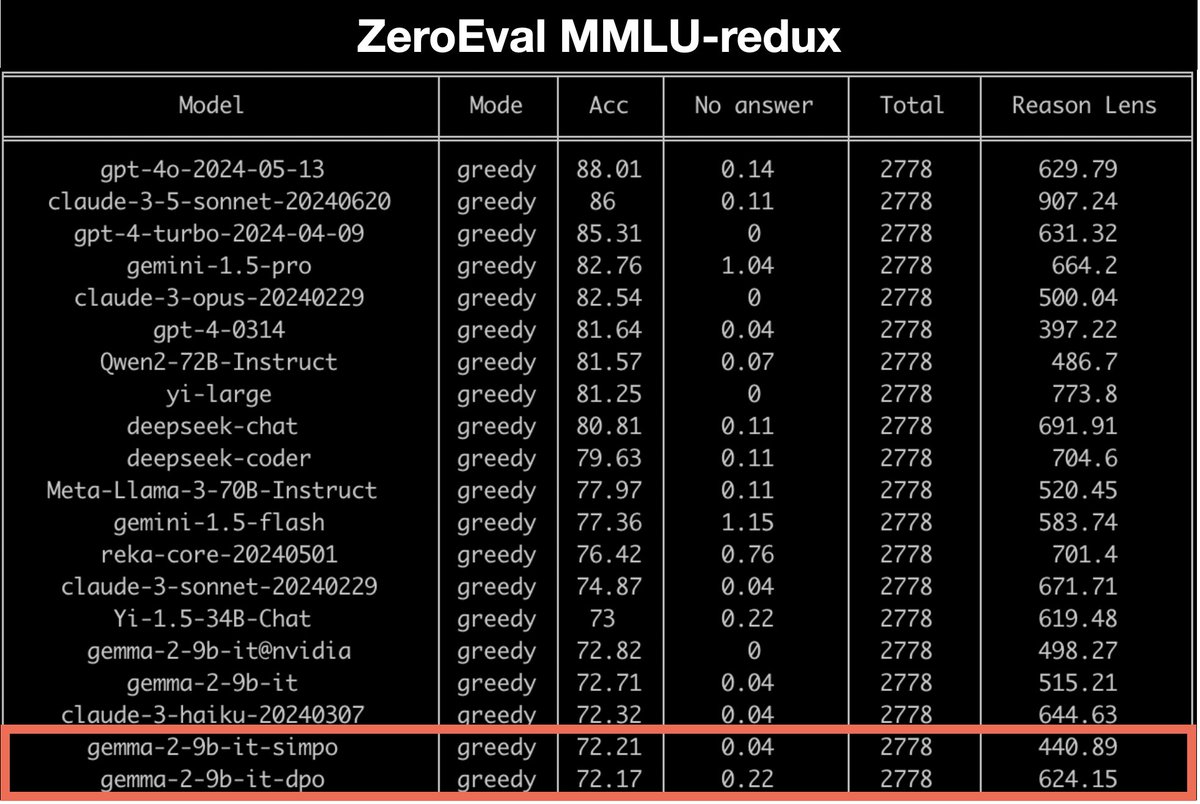
Sabitlenmiş Tweet

How can we understand neural chatbots in terms of interpretable, symbolic mechanisms? To explore this question, we constructed a Transformer that implements the classic ELIZA chatbot algorithm (with @Abhishek_034 and @danqi_chen). Paper: arxiv.org/abs/2407.10949 (1/6)

English