New research from Databricks AI Research: FlashOptim cuts training memory by over 50% with no measurable loss in model quality.
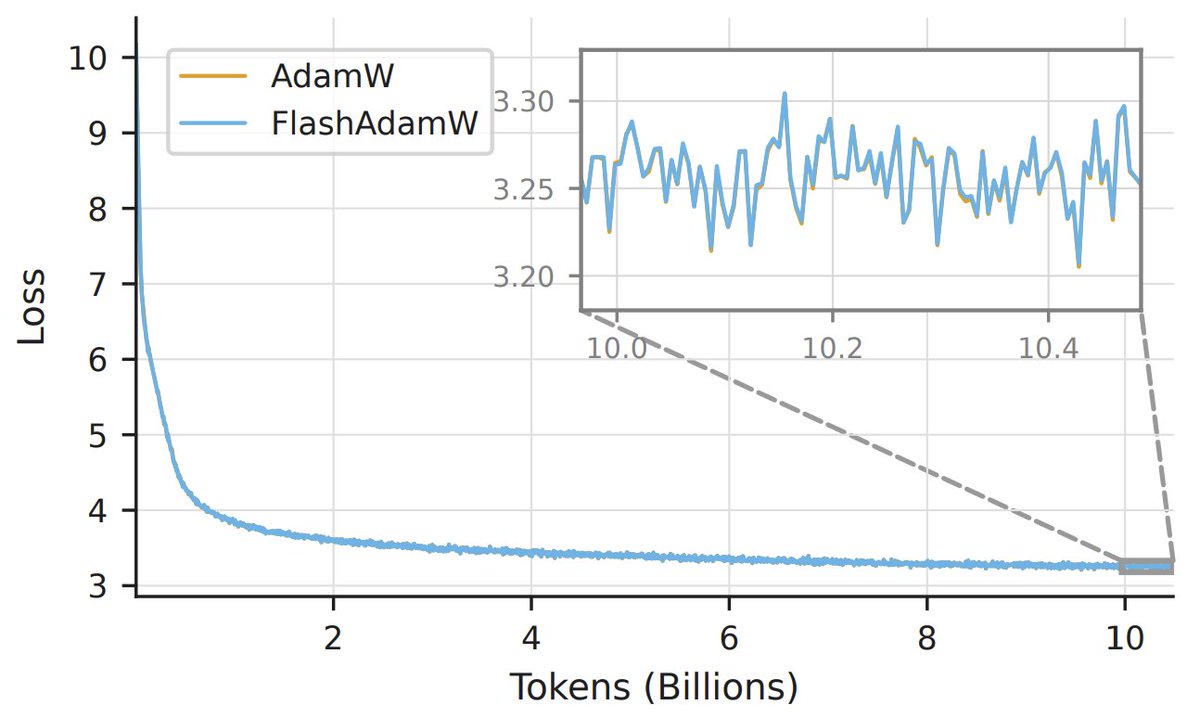
Training a model with AdamW typically requires 16 bytes per parameter just for weights, gradients, and optimizer state. FlashOptim brings that down to 7 bytes, or 5 with gradient release. For Llama-3.1-8B finetuning, peak GPU memory drops from 175 GiB to 113 GiB.
Two techniques drive this: improved master weight splitting using tighter ULP-normalized error correction, and companded optimizer state quantization that reduces quantization error and improves convergence.
FlashOptim works as a drop-in replacement for SGD, AdamW, and Lion, supports distributed training with DDP and FSDP2, and is open source.
Paper: arxiv.org/html/2602.2334…
Source code: github.com/databricks/fla…
Today, I'm heading to #Germany to take part in the inaugural Berlin Freedom Conference. I look forward to sharing #Taiwan's unwavering commitment to freedom & democracy with friends from Germany & around the world.
Announcing a significant upgrade to Agentic Document Extraction!
LandingAI's new DPT (Document Pre-trained Transformer) accurately extracts even from complex docs. For example, from large, complex tables, which is important for many finance and healthcare applications. And a new SDK makes using it require only 3 simple lines of code. Please see the video for technical details. I hope this unlocks a lot of value from the "dark data" currently stuck in PDF files, and that you'll build something cool with this!