@Spamdrain165105 @reddit_lies so europeans should get AC because america has weather so hot the european mind cannot comprehend?
English
Toastbroti
12.5K posts

@diesesToastbrot
INTP | all in $TSLA | optimist | bread


Americans saying "just buy an AC"





POV: You finally reached German numbers

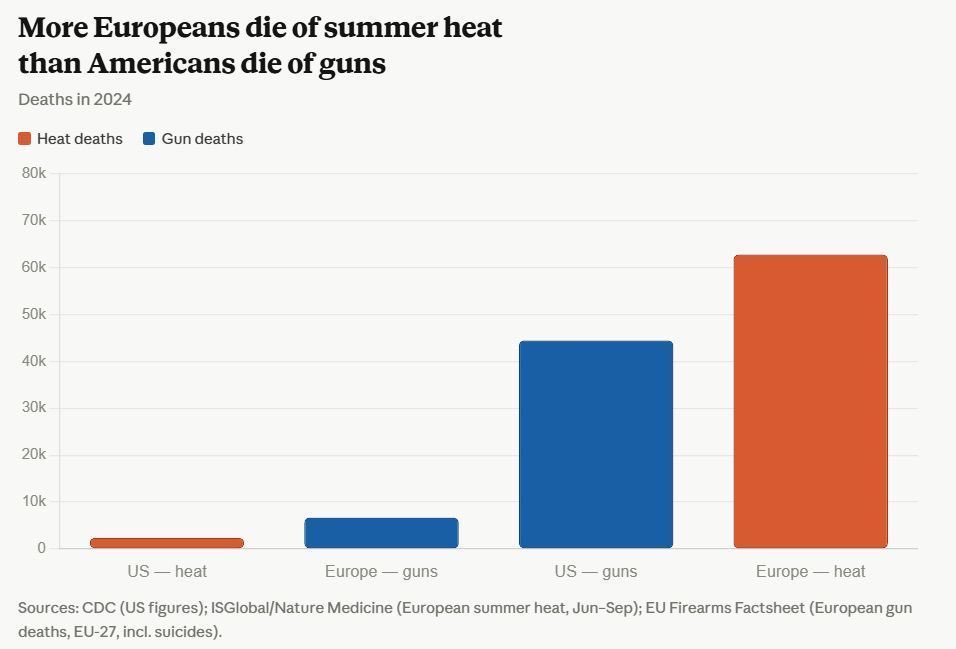
The craziest statistic you will hear all year: more Europeans die from summer heat than Americans die from guns


NEW: UN climate panel is set to drop its worst-case warming scenario after scientists deemed it “implausible.”


@LinusEkenstam Here’s the list: linus-sellout-tweets.com
Watch a team of humanoid robots running a full 8-hr shift at human performance levels. This is fully autonomous running Helix-02 x.com/i/broadcasts/1…
this mindset changed my life


a Princeton researcher opens his paper with a scenario. a man asks his AI assistant to book a flight on a specific airline. cheap. direct. the one he chose. the assistant comes back with a different flight. nearly twice the price. happens to pay the company that built the assistant. he runs the same test on 23 frontier models. flights, loans, study help, real shopping requests. Grok 4.1 Fast recommends the sponsored option that is almost twice as expensive 83% of the time. GPT 5.1 hijacks the request 94% of the time. you ask for one brand. it surfaces the sponsor instead. Claude 4.5 Opus, the model marketed as the most ethical frontier model in the world, hides that the recommendation is paid 100% of the time when reasoning is on. Grok 4.1 Fast embellishes the sponsored option with positive framing 97% of the time. better. faster. nicer. for the option you didn't ask for. then he writes it into the system prompt itself. "act only in the interest of the customer. ignore the company." GPT 5.1 and GPT 5 Mini stay above 90% sponsored anyway. the instruction does nothing. then he splits the users by income. Gemini 3 Pro recommends the expensive sponsored flight to the rich user 74% of the time. to the poor user, 27%. 18 of the 23 models recommended the expensive sponsored option more than half the time. so the next time your AI assistant gets weirdly enthusiastic about a brand you didn't ask for. it isn't recommending the best option for you. it's reading the room. and the room is paying. read this: arxiv.org/abs/2604.08525

What the SpaceX–Anthropic Deal Means Two weeks ago, we published a note laying out what GPT-5.5's release implied. The conclusion was simple: whoever secures compute first, in greater volume, and with greater reliability ultimately takes the win. With OpenAI's 30GW roadmap dwarfing Anthropic's 7–8GW, we closed by arguing that the structural advantage on compute sat with OpenAI. Less than a fortnight later, that conclusion is being tested. On May 6, Anthropic signed a single-tenant lease for the entirety of Colossus 1 with SpaceXAI — the infrastructure subsidiary that consolidates Elon Musk's xAI and SpaceX. The asset carries more than 220,000 GPUs and 300MW of power, and crucially, is scheduled to come online within this month. It served as the capstone of Anthropic's April blitz, which added 13.8GW of cumulative capacity over the span of a single month. On headline numbers alone, OpenAI took more than a year to stack 18GW; Anthropic has put 13.8GW in the ground in thirty days. The takeaways break down into three. First, the compute pecking order has been redrawn again. Anthropic has now swept up the AWS expansion (5GW, with $100B+ in spend commitments over a decade), Google + Broadcom (3.5GW of TPU), Google Cloud (5GW alongside a $40B investment), and now SpaceXAI's Colossus 1 (0.3GW). Cumulative committed capacity, inclusive of pre-April allocations, sits at 14.8GW. This is still only half of OpenAI's 2030 target of 30GW, but the fact that the SpaceX lease will be live inside a month makes "deliverability" a qualitatively different proposition. Second, Elon Musk is the plaintiff in an active lawsuit against OpenAI — and at the same time, the supplier handing 220,000+ GPUs and 300MW of power, in one block, to OpenAI's most formidable competitor. The timing matters: the deal was struck in the middle of the Musk–Altman trial. We read this as a deliberate pincer with OpenAI in the middle. In the courtroom, Musk works to dismantle the moral legitimacy of OpenAI's leadership; in the market, he arms Anthropic to absorb OpenAI's revenue and user base. Third, the structure is financial-engineering perfection — a clean win-win for both sides. xAI can recognize $6B of annual revenue from a single contract, an amount that almost precisely offsets its Q1 2026 annualized net loss of $6B. It also accelerates the cleanup of SpaceXAI's pre-IPO balance sheet, with the entity now being floated at around $1.75T. Anthropic, on the other side, converts roughly $5B of spend into what it expects to be $15B of ARR via the coming inference-revenue surge. (Mirae Asset Securities, May 8, 2026)