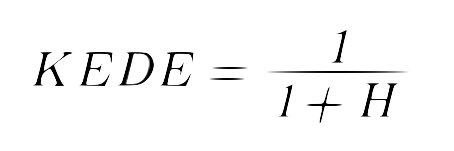
Sabitlenmiş Tweet

Knowledge Discovery Efficiency (KEDE), quantifies the knowledge gap a human needs to bridge for completing a task. Besides, KEDE is pronounced [ki:d].
When individual capability exceeds task complexity, the knowledge gap is too narrow, leading to wasted potential and boredom. Conversely, a wide knowledge gap, where tasks are too complex, leads to stress and lower productivity. An optimal gap keeps humans in a state of Flow, leading to higher productivity and job satisfaction.
Imagine typing the word: "Honorificabilitudinitatibus", from Shakespeare’s "Love's Labour's Lost". To calculate KEDE, we track the process, of typing this word
Each time interval, if I know what letter to type, mark "1". If I'm unsure, and need to check the spelling, mark "0".
I begin by reviewing the word, and this takes me two time intervals. Then, I confidently write: "Honor", then hesitate. After checking, I write: "ificabi", hesitate again, then write: "lit", check, write: ‘udi’,check, write: ‘ni’,check again, and finally write: "tatibus".
What results is a sequence of ones and zeros, alongside our word. The ones represent existing knowledge; the zeros, moments of knowledge discovery. The resulting Missing Information is 0.41 bits. The KEDE score is 71.
In short, tangible output, like our word, indicates applied knowledge. The ones and zeros are the journey of discovery.
This exercise illuminates the process behind KEDE calculation.
English