@fontamsoc For single issue, it is mostly between :
relaxed btb/branch timings (very close to what was used in the orconf talk at 200 Mhz):
- 1.45 Dhrystone/MHz 2.96 Coremark/MHz
stressed btb/branch timings + late alu :
- 1.74 Dhrystone/MHz 3.41 Coremark/MHz
@dolu1990 I noticed that you have a new cpu called VexiiRiscv which is in-order with performance matching NaxRiscv.
Does it mean out-of-order is not a performance booster ?
Do both issues handle jump/branch instructions ? Or the 2nd issue handles only ALU instructions ?
@fontamsoc Overall, to keep the Nax area "small" on FPGA, a few concession have been made :
- Rescheduling the instruction stream require to wait that all the previous instructions commits.
@fontamsoc Hi,
Hmm not realy for a few reasons :
- Coremark doesn't test the memory system performance (where OoO is great at)
- Coremark contains a big CRC loop which use random branch (Big penality for deep OoO pipelines)
- ...
@yannsionneau I only tried on Xilinx 7 so far, reason is their distributed ram are pretty good as far as my understanding goes. Not sure how well it will fit on ECP5, but it should work out the directly. everything is FPGA agnostic (but use a lot of asyncronously readed ram
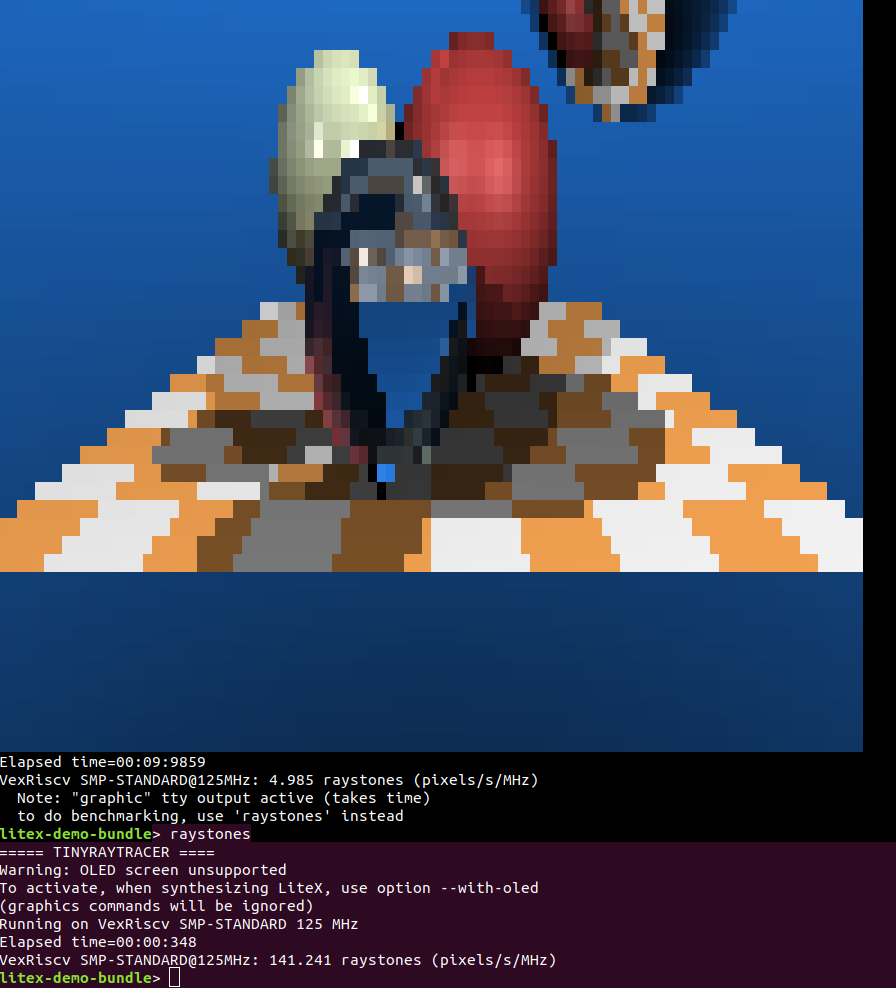
Test of @BrunoLevy01 's TinyRayTracer on Arty with VexRiscv-SMP 1 Core + FPU @ 125Mhz. Had to adapt the code a bit since was the CPU was too fast for it :): seems to give 141 raystones!
hmmmm I was discussing with @splinedrive about threading and interleaving and, we realized that a darkriscv configured with 32 threads use only 2845LUTs in a spartan-6, which means only 88LUTs per thread... (1/2) 🔥
@minut_e@pftbest@enjoy_digital One thing to know, as there is no memory coherency, can't use the litex SD controller, nor the OHCI one, as they use DMA.