Sabitlenmiş Tweet
mobo
2.1K posts


mobo
@dotmobo
🧙♂️developer/AI engineer 🐧linux 💕python/rust/typescript 🎮lua/love2d/pico8 🎸metal 👽sci-fi 👻 horror 🐈⬛cats 🏕 forest 🚀e/acc
France Katılım Aralık 2013
793 Takip Edilen185 Takipçiler

mobo retweetledi

Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: goo.gle/4bsq2qI
GIF
English
mobo retweetledi

Software horror: litellm PyPI supply chain attack.
Simple `pip install litellm` was enough to exfiltrate SSH keys, AWS/GCP/Azure creds, Kubernetes configs, git credentials, env vars (all your API keys), shell history, crypto wallets, SSL private keys, CI/CD secrets, database passwords.
LiteLLM itself has 97 million downloads per month which is already terrible, but much worse, the contagion spreads to any project that depends on litellm. For example, if you did `pip install dspy` (which depended on litellm>=1.64.0), you'd also be pwnd. Same for any other large project that depended on litellm.
Afaict the poisoned version was up for only less than ~1 hour. The attack had a bug which led to its discovery - Callum McMahon was using an MCP plugin inside Cursor that pulled in litellm as a transitive dependency. When litellm 1.82.8 installed, their machine ran out of RAM and crashed. So if the attacker didn't vibe code this attack it could have been undetected for many days or weeks.
Supply chain attacks like this are basically the scariest thing imaginable in modern software. Every time you install any depedency you could be pulling in a poisoned package anywhere deep inside its entire depedency tree. This is especially risky with large projects that might have lots and lots of dependencies. The credentials that do get stolen in each attack can then be used to take over more accounts and compromise more packages.
Classical software engineering would have you believe that dependencies are good (we're building pyramids from bricks), but imo this has to be re-evaluated, and it's why I've been so growingly averse to them, preferring to use LLMs to "yoink" functionality when it's simple enough and possible.
Daniel Hnyk@hnykda
LiteLLM HAS BEEN COMPROMISED, DO NOT UPDATE. We just discovered that LiteLLM pypi release 1.82.8. It has been compromised, it contains litellm_init.pth with base64 encoded instructions to send all the credentials it can find to remote server + self-replicate. link below
English
mobo retweetledi

LiteLLM HAS BEEN COMPROMISED, DO NOT UPDATE. We just discovered that LiteLLM pypi release 1.82.8. It has been compromised, it contains litellm_init.pth with base64 encoded instructions to send all the credentials it can find to remote server + self-replicate. link below
English
@_Nidouille_ Enfin bon brancher une ia sur de la prod faut pas être bien malin hein ...
Français

L'IA qui explose ta prod et supprime les snapshots et les backups 👏
Sa veut dire que la politique de sauvetage est à chier. Je doute que la règle du 3 2 1 à été mis en place.
L IA fait des conneries comme l'humain et trop se reposer dessus est une connerie.
Numerama@Numerama
L'IA devait sauver les développeurs, elle détruit leur production : un agent Claude Code supprime une base de données entière ; Amazon en réunion de crise après des pannes liées à l'IA. 👉 l.numerama.com/Jgj
Français

Ces gens qui marchent pour "pause AI" devant OpenAI, question sincère : si demain votre enfant a un cancer et qu'une IA peut trouver le traitement en 6 mois au lieu de 15 ans, vous voulez qu'on pause aussi ?
La technologie ne s'est jamais arrêtée dans l'histoire de l'humanité. Jamais. Ceux qui ont essayé ont juste perdu. Et la géopolitique rend le débat encore plus absurde, la Chine ne pausera pas. "Pauser" côté Occident c'est offrir le leadership technologique le plus important de l'histoire à un régime autoritaire.
Même avec un risque existentiel sur la table, l'humanité prendra ce pari. Parce qu'en face il y a l'éradication du cancer, de la pauvreté, des maladies rares, l'éducation pour 8 milliards de personnes.
Ces gens sont le symptôme exact du mal qui ronge l'Occident : le principe de précaution érigé en religion, l'immobilisme déguisé en sagesse. Et historiquement c'est exactement ça qui crée la stagnation, le nihilisme, et les conditions du fascisme.
Dans l'histoire de l'humanité, ce n'est jamais la pause qui nous a sauvés. C'est l'envie de se dépasser, de repousser les limites, de créer des technologies qui nous sortent de notre condition. C'est le progrès et la croissance qui éradiquent la misère, pas la peur et la réglementation.
La stagnation crée des maux bien pires que les risques que l'IA nous fait prendre. On s'en sortira comme on s'en est toujours sortis : en construisant, pas en s'arrêtant.
Michaël Trazzi@MichaelTrazzi
On our way to OpenAI!
Français
@BrivaelFr Et franchement tant mieux. Scrum c'est intéressant à connaitre pour pouvoir sortir certaines techniques dans des situations specifiques, mais ça s'arrête là.
Français
Tout l'écosystème de certifications agiles va crever.
SAFe certified,
Scrum Master certified, tout ça.
Les seuls qui ont jamais accordé de l'importance à ces trucs c'étaient des gens moyens qui avaient besoin d'un badge pour justifier leur poste.
Les boites qui vont survivre n'auront plus besoin de ça.
Elles auront besoin de gens qui comprennent leurs systèmes, qui savent les faire évoluer, et qui ont le taste pour prendre les bonnes décisions quand l'agent ne peut pas.
Brivael - FR@BrivaelFr
Scrum a ruiné une génération de devs. Les solutions clés en main d'agents IA vont ruiner la suivante. Pour exactement la même raison. Le pattern : → un problème fondamentalement contextuel → quelqu'un vend une méthode générique → tout le monde l'applique sans réfléchir → ça marche pas → on blame l'exécution au lieu de la méthode Les meilleures boîtes n'ont jamais appliqué Scrum by the book. Elles ont construit leur propre façon de fonctionner, adaptée à leur contexte, leur culture, leur stade de croissance. Et elles l'ont fait évoluer en permanence. Avec les agents, c'est exactement pareil. Chaque boîte a une archi différente, une stack différente, des process différents. Brancher un agent générique sur tout ça et espérer que ça marche, c'est la même illusion que de coller Scrum sur une équipe et attendre que la productivité explose. Nous en ce moment on construit Argil Forge. C'est notre harness interne. On a wrappé Claude Code avec toute notre infra : → Playwright pour le browser → Tauri en desktop app → un backend qui orchestre nos services → des worktrees git dédiés avec des ports séparés par service → des callbacks d'auth auto-générés Résultat : un agent qui a le même setup qu'un ingé onboardé chez nous. Pas un outil générique posé dans un terminal qui bosse en silo. On commence par le produit, mais le plan c'est d'étendre à toute la boîte : ops, marketing, ads, SEO, legal. → Ship une feature → la landing se crée → Nouveau use case → la campagne se lance Et tout ce qui a vraiment de la valeur là-dedans, c'est ce qui est propre à nous : → Le context graph de la boîte → La mémoire globale de l'orchestrateur level 0, qui porte la vision d'ensemble → La mémoire de chaque agent spécialisé, qui accumule l'expertise de son domaine → Une decision trace commune entre toutes les entités, pour que chaque décision prise par un agent soit visible et traçable par tous les autres C'est pas générique. C'est le reflet de comment notre boîte fonctionne. Et c'est un truc qu'on va owner et maintenir de manière profonde, parce que c'est ça qui permet à terme de faire tourner la boîte quasiment en autopilote. L'objectif dans quelques mois chez Argil, c'est qu'il reste deux métiers : → Maintenir et faire évoluer ces systèmes → Prendre les décisions qui reposent sur de la taste, et corriger celles de l'agent quand il se trompe Et quand l'agent a suggéré 10 décisions d'affilée validées par l'humain, on considère que ce domaine commence à pouvoir tourner en autopilote. Dans le futur, les meilleures boîtes owneront leur agent infrastructure comme elles ownent leur culture et leur orga. Ça se construit, ça se maintient, ça évolue. Les autres achèteront le "Scrum des agents" et se demanderont pourquoi rien ne marche.
Français
mobo retweetledi

🚨 BREAKING: Nous Research just dropped an AI agent that gets better the more you use it.
hermes-agent is built around the Hermes model family and it is different from every other agent framework:
→ Personalizes to you over time instead of resetting every session
→ Grows skills the more tasks it completes
→ Integrates with OpenClaw, Claude Code, and other agentic ecosystems
→ Built by Nous Research, one of the most respected open source AI labs
→ Fully self-hosted and free
Most agents forget everything the moment you close the tab.
This one remembers. And it improves.
100% Free and open source.

English
@DFintelligence Mon setup c'est opencode et des ia locales. Il faut pousser l'indépendance au maximum. Arrêtons de filer toutes nos données aux entreprises americaines.
Français

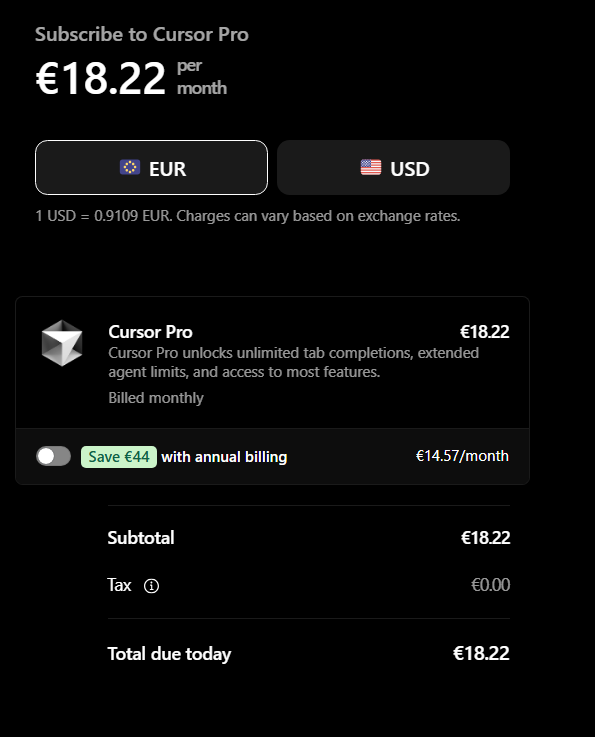
Et voilà, après 9 mois d’annulation de mon abo Cursor, j'y reviens pour une raison : Codex EST À CHIER sur le design et la compréhension du front. J'EN PEUX PLUS.
Donc maintenant, je fais de Codex mon agent IA "lead". Et pour toutes les tâches de front et de design, je vais utiliser l’abonnement Cursor pour profiter d’Opus 4.6 et de Gemini 3.1.
C’est la méta actuelle que j'ai trouvée. Tous les 3 mois, en ce moment, je change mon setup, jpp.
C'est quoi votre setup vous actuel ?
Français
mobo retweetledi

🎉 Congrats to @nvidia on the release of Nemotron 3 Super — day-0 support in vLLM v0.17.1! Verified on NVIDIA GPUs.
120B hybrid MoE, only 12B active at inference. Big upgrades over the previous Nemotron Super:
- 5x higher throughput
- 2x higher accuracy on Artificial Analysis Intelligence Index
- Multi-Token Prediction (MTP) for faster long-form generation
- Configurable thinking budget — dial accuracy vs token cost per task
- 1M token context window
Supports BF16, FP8, and NVFP4. Fully open: weights, datasets, recipes.
Blog: vllm.ai/blog/nemotron-…
🤝 Thanks @NVIDIAAIDev Nemotron team and vLLM community contributors!

NVIDIA AI Developer@NVIDIAAIDev
Introducing NVIDIA Nemotron 3 Super 🎉 Open 120B-parameter (12B active) hybrid Mamba-Transformer MoE model Native 1M-token context Built for compute-efficient, high-accuracy multi-agent applications Plus, fully open weights, datasets and recipes for easy customization and deployment. 🧵
English
mobo retweetledi

Unveiling our new startup Advanced Machine Intelligence (AMI Labs).
We just completed our seed round: $1.03B / 890M€, one the largest seeds ever, probably the largest for a European company.
We're hiring!
[the background image is the Veil Nebula - a picture I took from my backyard, most appropriate for an unveiling]
More details here:
techcrunch.com/2026/03/09/yan…
AMI Labs@amilabs
Advanced Machine Intelligence (AMI) is building a new breed of AI systems that understand the world, have persistent memory, can reason and plan, and are controllable and safe. We’ve raised a $1.03B (~€890M) round from global investors who believe in our vision of universally intelligent systems centered on world models. This round is co-led by Cathay Innovation, Greycroft, Hiro Capital, HV Capital, and Bezos Expeditions, along with other investors and angels across the world. We are a growing team of researchers and builders, operating in Paris, New York, Montreal and Singapore from day one. Read more: amilabs.xyz AMI - Real world. Real intelligence.
English
mobo retweetledi

mobo retweetledi
🚀 vLLM v0.17.0 is here! 699 commits from 272 contributors (48 new!)
This is a big one. Highlights:
⚡ FlashAttention 4 integration
🧠 Qwen3.5 model family with GDN (Gated Delta Networks)
🏗️ Model Runner V2 maturation: Pipeline Parallel, Decode Context Parallel, Eagle3 + CUDA graphs
🎛️ New --performance-mode flag: balanced / interactivity / throughput
💾 Weight Offloading V2 with prefetching
🔀 Elastic Expert Parallelism Milestone 2
🔧 Quantized LoRA adapters (QLoRA) now loadable directly

English
mobo retweetledi
🚨 BREAKING: The Qwen team just shipped their official agent framework and it has everything.
No stitching together third-party libraries. No fighting abstractions.
Qwen-Agent gives you:
→ Native function calling built directly into the framework
→ Secure code interpreter sandbox out of the box
→ RAG and MCP support included
→ Chrome extension for browser-native agent workflows
Built by the team that built the model. So it just works.
100% open source and completely free.
English

mobo retweetledi

this is what a 24gb VRAM builds in 2026.
one prompt. ten files. 3,483 lines of code. zero handholding. i gave Qwen3.5-35B-A3B a single detailed spec describing the full game architecture and hit enter. enemy types, particle systems, procedural audio, powerups, boss fights, ship upgrades, parallax backgrounds, everything in one message.
the model planned the file structure itself, wrote every module in dependency order, wired all the imports, and served the game on port 3001. it ran on first load. when it hit a bug in collision detection it read its own error output, found the issue, fixed it, and kept building. this is pure agent loop running on local hardware.
what you're looking at is pixelated octopus aliens with tentacle animations, 4 layer parallax space background with planets at different depths, a full particle system handling explosions and ink splatter and engine trails and bullet impacts, procedural audio through Web Audio API with zero sound files loaded, unleash mode with combo multiplier, boss fights every 5 levels, ship upgrades that unlock as you progress. no libraries. no frameworks. vanilla JS and Canvas.
3B active parameters. single RTX 3090. llama.cpp with q8_0 KV cache at 262K context. Claude Code pointed at localhost:8080 through the native Anthropic endpoint. no API costs. 112 tok/s. a GPU you can buy used for $800.
game is called Octopus Invaders and i actually like playing it.
Sudo su@sudoingX
testing Qwen3.5-35B-A3B latest optimized version by UnslothAI on a single RTX 3090. one detailed prompt. zero handholding. watch a 3B model scaffold an entire multifile game project autonomously. the setup: > model: Qwen3.5-35B-A3B (80B total, only 3B active per token) > quant: UD-Q4_K_XL by Unsloth (MXFP4 layers removed in latest update) > speed: 112 tok/s generation, ~130 tok/s prefill > context: 262K tokens > flags: -ngl 99 -c 262144 -np 1 --cache-type-k q8_0 --cache-type-v q8_0 > engine: llama.cpp > agent: Claude Code talk to localhost:8080 (llama.cpp now has native Anthropic API endpoint. no LiteLLM needed) q8_0 KV cache cuts VRAM usage in half vs f16 at 262K. -np 1 is default but worth noting. parallel slots multiply KV cache and at 262K that's an instant OOM. the prompt was more detailed than this but you get the idea: build a space shooter with parallax backgrounds, particle systems, procedural audio, 4 enemy types, boss fights, power-up system, and ship upgrades. 8 JavaScript modules. no libraries. game's called Octopus Invaders. gameplay footage dropping next.
English
@sam__brd @benjamincode Je comprends exactement ton sentiment et finalement pour palier à ca, j'utilise opencode avec des LLMs open source que je déploie et administre moi même sur des GPUs. Meme si l'efficacité est moindre par rapport à Claude, on moins j'ai la satisfaction de maîtriser tte la chaîne
Français

@benjamincode Perso j'ai le sentiment de rien faire de mes journées alors que paradoxalement "je" produit plus de ligne de code que jamais. J'ai l'impression de pas etre productif un peu comme si c'était pas moi qui travaillais et je peux pas etre fier du travail accomplis 😔
Français

J'adore le vibecoding.
Mais il perturbe complètement notre relation avec notre travail.
Il faut tout réapprendre.
Avant vous étiez fier de vous quand vous aviez produit en une journée même pas un dixième de ce que vos agents vous produisent en 1h.
On pouvait fermer les ordis pour la soirée, la pause était méritée.
Aujourd'hui, on s'arrête plus.
On produit 100x plus vite avec la sensation qu'on peut toujours plus.
Il n'y a tellement plus de friction que ne pas faire bosser vos agents semble être du temps perdu.
Ça prend 3min de de la lancer sur une tache. Puis 3 min de checker que tout va bien. Puis encore 3 min de lancer une deuxième tache en parallèle.
Avant on produisait jusqu'a la limite de nos capacités, on était satisfait du ratio effort/output, et on était aussi épuisés. C'était trois conditions qui nous faisaient converger vers un arrêt naturel.
Le vibecoding a fait sauter les trois en même temps. Notre signal d'arrêt naturel a disparu.
Dernièrement je sens au fond de moi que quelque chose déconne.
Quand continuer ne coûte plus rien, comment on mérite encore de s'arrêter ?
Français

LLMs don’t think. They don’t reason the way humans do. They predict the next token based on probability distributions learned from massive datasets. What feels like reasoning is statistical pattern completion at scale. The magic isn’t intelligence, it’s compression. They’ve compressed patterns from millions of documents into weights. That’s powerful. But it’s not consciousness.
English
mobo retweetledi
