@samat Нужен скорее не навык ставить задачи, а навык работы мейнтейнером: ревьювить изменения, глубоко понимать их последствия, сохранять архитектуру поддерживаемой.
Русский
Andrew Luzin
5.1K posts

@dronnix
Software development, Linux, Distributed systems, etc. Forest, mountains, alpine skiing, cycling, trail riding, etc.



generalists are about to win big If you understand a little of tech, business, and people, and can connect everything fast. you're sitting on a goldmine right now.

Дежурно напоминаю, что нормальное состояние большинства — быть мидлом. Если все синьоры и лиды, то скорее всего никто не сеньор и не лид, просто всех подтянули, чтоб никому обидно не было.


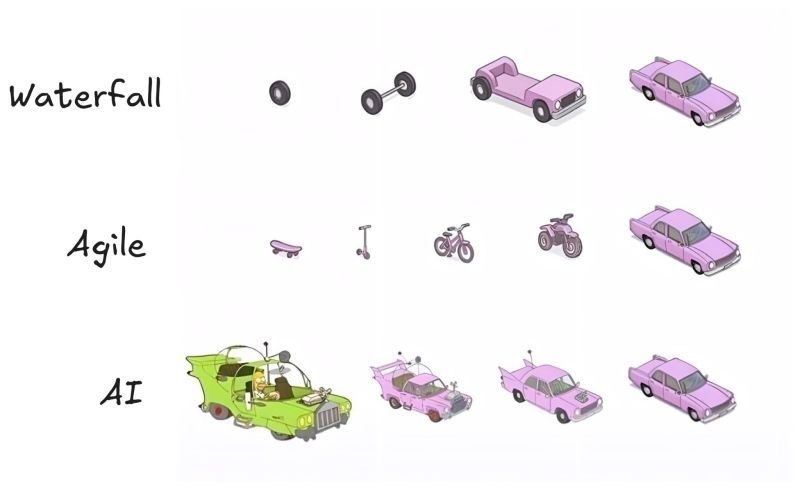
POV: you’re a developer in 2026😂

Striking image from the new Anthropic labor market impact report.




Russia’s hope that it can create tech “national champions” by banning all their competitors is delusional. Every real national super app was forged in fierce private competition (WeChat, KakaoTalk, LINE). Competition and innovation are two sides of the same coin.

I've been doing open source since I was a teenager (over 20yrs). And for the first time ever, I'm considering closing external PRs to my OSS projects completely. This will throw the baby out with the bathwater and I hate that, but we close auto-opened slop PRs every single day.