Sabitlenmiş Tweet

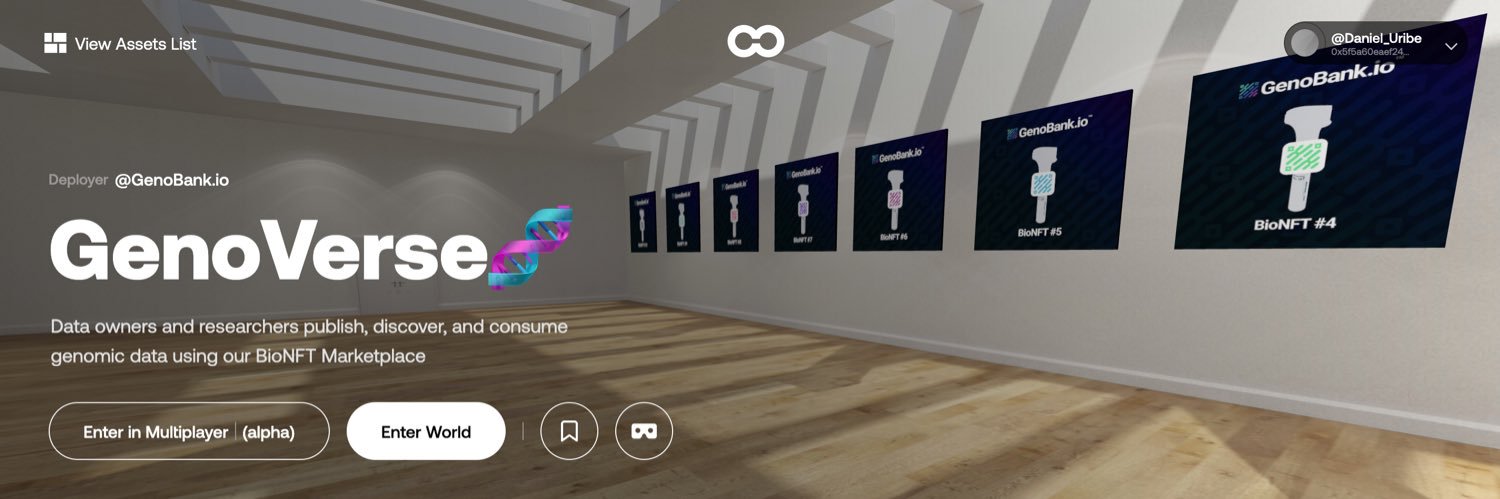
Proof of Consent over Human Biosamples 🧬 for AI Agents.
Agentic AIxBIO safeguarded by GenoBank.io's BioNFTs

English
Daniel Uribe, MBA 🧬+⛓
5.7K posts
@duribeb
Inventor of BioNFTs 🧬 ꧁BioIP꧂ acc/genomics 🧬 Agentic Precision Medicine




Biodata is among the most valuable training data in the world. @genobank_io enables breast cancer patients in Mexico to classify their DNA, detect risks early, and license their data for revenue. This is what patient-owned medicine looks like. Built on Story.
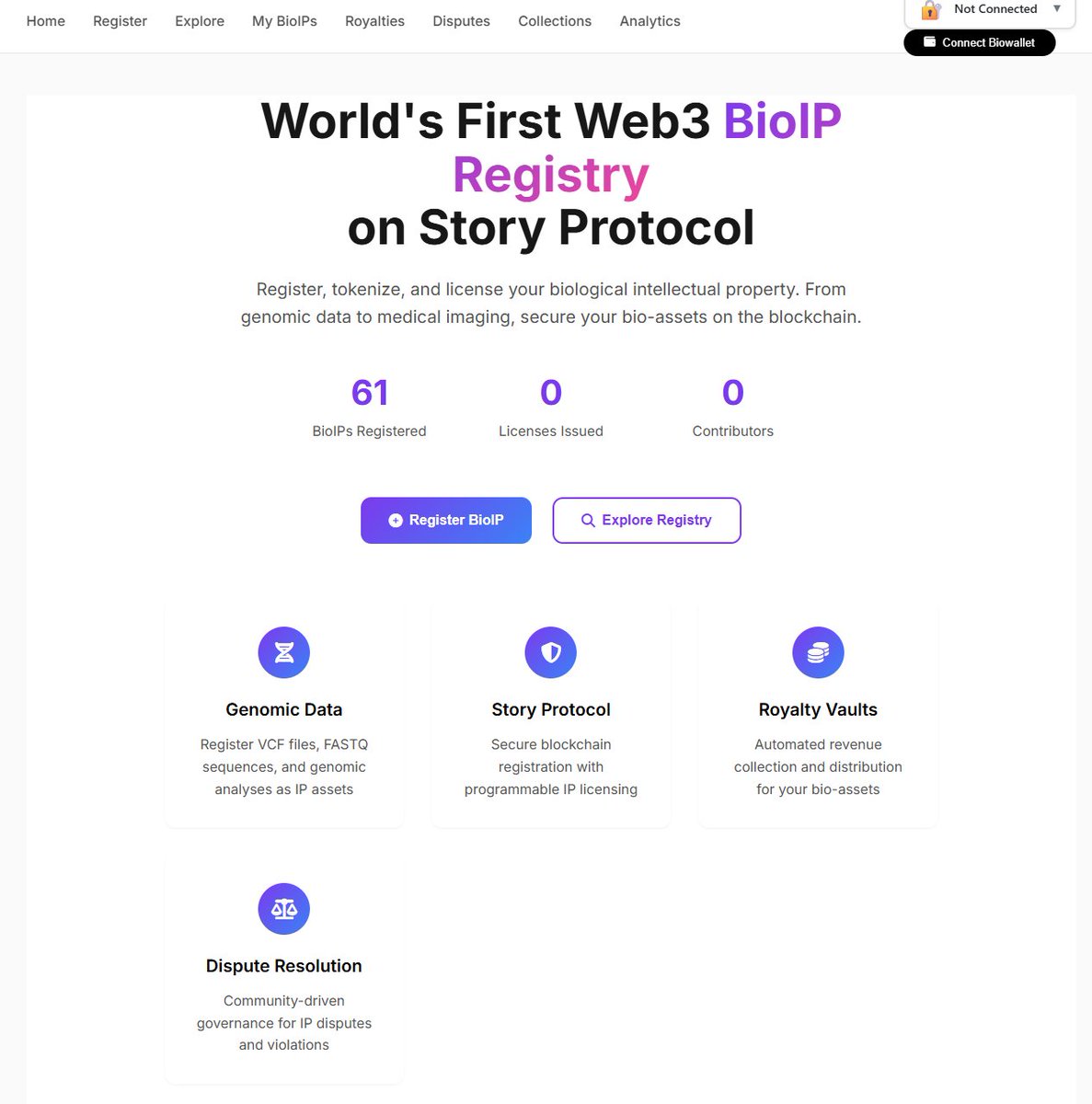
People think AI data is the new oil. But here is the real question nobody asks !! what is the question?? wait I'm telling you... the question is.. Who owns the data that trains AI? This is where @genobank_io × @StoryProtocol becomes one of the most interesting innovations I’ve seen lately. Genobank is building a system where genomic data (DNA data) can become programmable IP onchain. Instead of biotech companies collecting DNA data and keeping all the value… Your genomic dataset can become an IP asset that can be licensed to researchers, AI models, or biotech companies. And the infrastructure making this possible? Story Protocol. Story turns data into programmable IP with: • verifiable ownership • licensing rules • automated royalties • onchain provenance That means your biological data is no longer just a file. It becomes an asset. This is a huge shift because genomic datasets are extremely valuable for: • medical AI • drug discovery • disease prediction models • precision healthcare Yet today most people who generate the data earn nothing. Genobank flips that model. If you want to try it yourself, here’s the process 👇 1️⃣ Go to bioip.genobank.app 2️⃣ Connect your wallet. 3️⃣ Upload a genomic VCF dataset. 4️⃣ The platform processes the data and prepares it for BioIP registration. 5️⃣ Once approved, the dataset can become a programmable IP asset powered by Story. Meaning the data can be licensed and monetized with transparent ownership. I actually tried to upload a dataset myself to test the process. But I ran into some technical issues during the upload step, so the platform returned an error. Still, the concept is extremely interesting and I’m planning to test it again soon. Once I manage to complete the upload successfully, I’ll share a full update. Because the idea of turning biological data into programmable IP might be one of the most underrated innovations happening in the Story ecosystem right now. @mushy @BharatWormie @ICat4you




Every night, your body tells a story. 🧬💤 Tether is proud to announce our strategic investment in @eightsleep to build the future of human health intelligence. By combining their pioneering sleep fitness with our platform for Edge AI, @QVAC, we are setting a new standard for human potential. Tether x Eight Sleep. Unstoppable together.


This is absolutely crazy! Cardiologist wins 3rd place at @AnthropicAI 's hackathon! Out to 13,000 applications! Built in 7 days. Coded day and night — in the hospital, in the cloud, while flying from Brussels to San Francisco. A week ago, 500 builders were selected to compete. We had one week to bring our project to life using claude code and create a pitch video. Today, in the finals the judges including @bcherny, @_catwu @trq212 @lydiahallie @adocomplete and Jason Bigman chose top 6 projects .... and I was awarded 3rd place! The project is called postvisit.ai And yes, it's a reference to Previsit.ai that I am creating since 3 years. Postvisit.ai is an AI agentic care platform for patients. Including reverse AI scribe it is a companion that guides the patient from the moment they leave the doctor's office. Powered by the massive context window of Opus 4.6, it allows patients to explore their full medical history, connected devices, Evidence Based resources and external data sources — all in one place. This is what agentic healthcare looks like. Writing with claude code allowed me to bring this idea to life in 7 days. Creating the video was much more of a challenge. What an incredible time to be alive and create! Check out the pitch video here: youtube.com/watch?v=V29UCO… Thank you to organizers of the hackathon - @CerebralValley Looking very much forward to seeing you, the hackathon participants and @AnthropicAI staff at the Claude Code Birthday Party!


An agentic world needs IP rails. On @IBM’s Making Data Simple with Al Martin, Story CPO @devrelius breaks down how Story turns IP into programmable infrastructure for AI. From “mysterious training data blobs” → provable usage, enforceable licenses, auto payments. Listen ↓

Meet BIOS, an AI Scientist built to orchestrate complex biomedical research. • Global SOTA on Data Analysis Benchmarks: BixBench 48.78% open-answer, 55.12% multiple-choice + refusal, 64.39% multiple-choice (no refusal) - outperforming systems like Edison Scientific and Kepler. • Human-in-the-Loop or Autonomous Mode: Intermediate checkpoints let researchers guide investigations mid-flight as insights emerge. No more waiting hours for batch runs + reruns to get results. Or, run in fully autonomous mode for extended investigations. • Persistent World State: Rather than losing context as conversations grow, world state ensures investigations build on insights within each research cycle and across sessions. • Subagent Swarm: BIOS orchestrates subagents specializing in research functions (Literature Review, Data Analysis, Novelty Detection) and, soon, research domains (microbiology, longevity, genomics). BIOS is available now in Beta with free + paid tiers, exclusive launch pricing and, for limited time, free full access to academic users with a .edu email address. Pro, Researcher and Lab subscription tiers offer discounted packages on monthly credits. Our usage-based pricing is competitive and in some cases significantly cheaper than leading scientific agents. Try BIOS and read our paper in the links below ↓


I am pleased to share the peer-reviewed published manuscripts by Kuperwasser and El-Deiry “COVID vaccination and post-infection cancer signals: Evaluating patterns and potential biological mechanisms” and El-Deiry “Hypothesis: HPV E6 and COVID spike proteins cooperate in targeting tumor suppression by p53” both published today but censored due to cybercriminial attack on the @Oncotarget @OncotargetJrnl website. The authors are happy to share the full PDFs with any interested reader upon request by email.


