
@theo I like to switch between claude and codex during different stages of development, and have a custom CLI for injecting project context into either, so the CLI agents work great for me.
English
Elizabeth Hutton
33 posts
@ehutt_
ML Engineer | Phoenix OSS | always learning unsupervised

Just learned it's literally impossible to paste images into Claude Code over SSH. How do you CLI people live like this??



🧠 One AI Question with Ankur Duggal We asked our AI Solutions Architect: Why use an LLM to evaluate another LLM? His answer: It's like human-to-human evaluation. By using specific prompts, an LLM acts as a judge to grade performance—leading to more accurate results and better AI model scaling. It's one of the most powerful patterns in modern AI development. #AI #LLM #MachineLearning #AIEvals #LLMAsAJudge

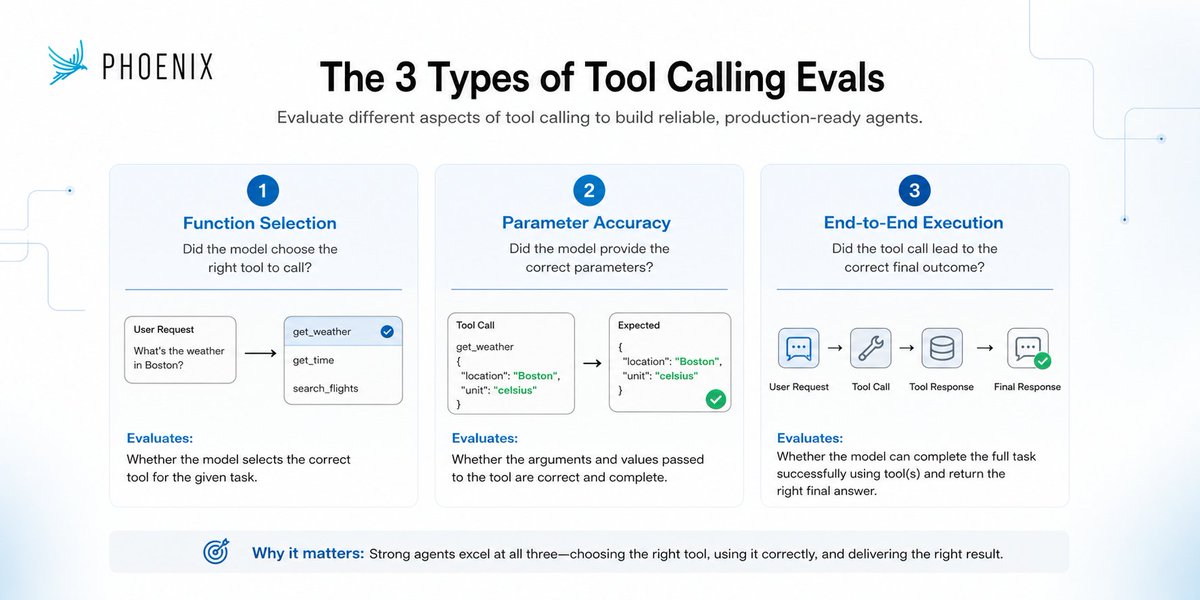




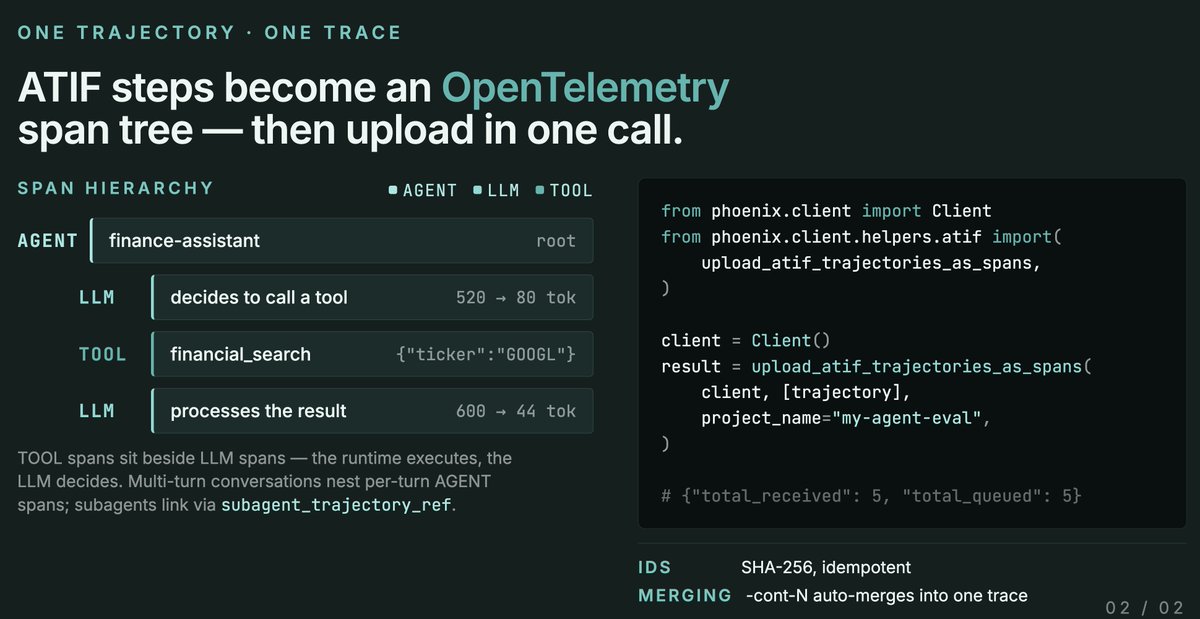
We just shipped ATIF support in @ArizePhoenix ATIF (Agent Trajectory Interchange Format) is an emerging standard for logging agent runs, supported by Harbor across @claude_code, @OpenHandsDev, @geminicli , @OpenAICodexCli and other agent frameworks.



