Sabitlenmiş Tweet

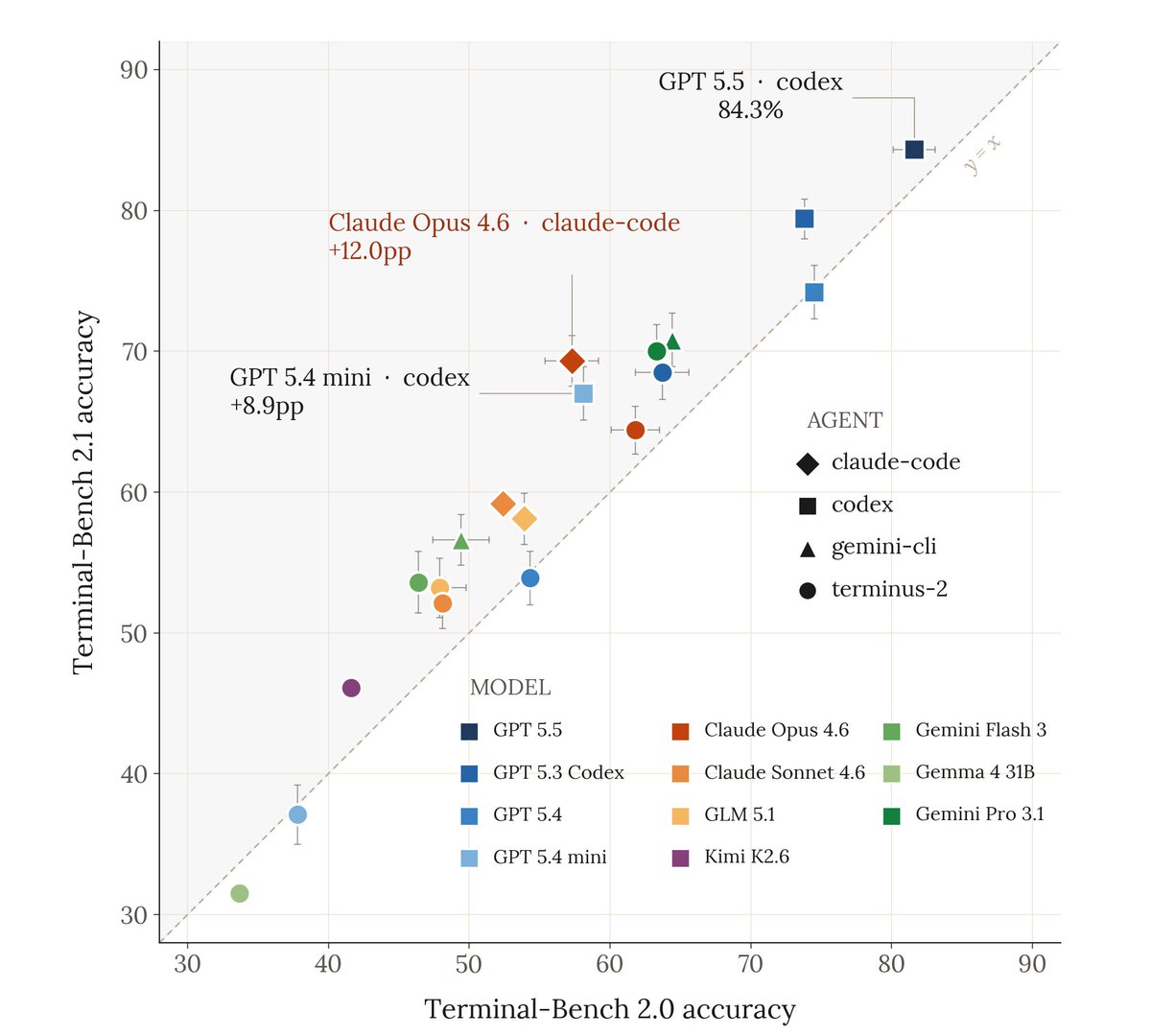
Very excited to release Terminal-Bench 2.1!
Coding agents are among the most economically consequential deployments of LLMs to date. As agents improve, benchmark reliability matters more.
We audited TB2.0 and found and corrected issues in 28/89 tasks. 30% of the benchmark!
But the rankings survived, absolute scores moved up to 12pp!
English