Sabitlenmiş Tweet
Eric Auld
4.8K posts


Eric Auld
@ericauld
Performance and kernels at Together AI
California, USA Katılım Mart 2009
570 Takip Edilen772 Takipçiler

Eric Auld retweetledi

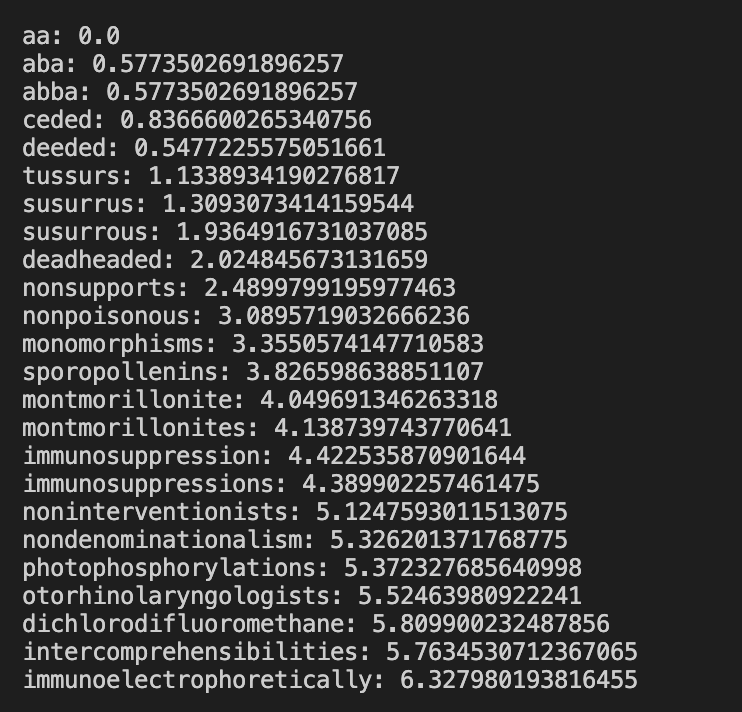
Word with the lowest standard deviation of letter position in the alphabet, for each length
English

In five years, most learning applications will not use backprop.
English
It seems you’re trying to have it both ways by calling it “a pattern” but avoiding its having physical causal effects…aren’t such effects part of how we get to call it “a pattern”?
So suppose we have a brain-scanning machine with a light bulb that lights up when pattern X is detected and not otherwise. Is that not causal enough?
English

In a causal graph, a variable X could be said to have or not have a causal effect on variable Y based on counterfactuals. Yet variables expressing high-level patterns are not in general intervenable variables in the graph. So 'causation vs epiphenomenalism' is a false dichotomy.
English
@phl43 I'm still impressed that I can open a book in a browser, and ask it to explain notation in some formula a thousand pages in. This capability didn't exist last year

English

I know I'm a broken record on this topic, but I really can't stress enough how amazing LLMs are for learning. It used to be that, when reading a complicated paper/book, I had to either spend a lot of time figuring out the trickiest parts or just give up on fully understanding it to save time.
AI effectively makes that tradeoff less severe by significantly reducing the time it takes to fully understand a complicated paper/book. I really don't get why so many people, including many who work in intellectual professions, seem to be nonplussed about this technology. It's fucking amazing.
English
Eric Auld retweetledi

Yes, I've been saying this for a while now. See for example x.com/sebkrier/statu… and Danzig's work here: cset.georgetown.edu/wp-content/upl…
I don't think the predominant narrative of AI as a singular entity, a Sand God, a discrete moment in time, or a 'separate species' (as Tegmark puts it) is correct or helpful. As Danzig argues, AI is indeed "alien," but only in the same way a stock market or the DMV is alien: they are all reductionist, correlative intelligences.
They strip the world of context, reducing reality to standardized inputs like prices or tokens to process information at scales humans cannot. To me at least, this shared "alien" nature normalizes AI as the latest evolution in a lineage of artificial processors we’ve lived with for centuries.
So instead of a unitary being or species, AGI should be understood as a collection of complex systems, models, and products that functions similarly to (and integrates with) existing human macro-systems. An amplifier for the bureaucracies and markets that already govern us, not a discrete 'biological-style' agent. Its governance is a continuous sociopolitical struggle (insert always has been meme) that is shaped by many different forces, not a one-time mathematical proof of safety before a launch.
Relatedly, I feel like the current discourse also has a blind spot for the 'demand' side. We obsess over the supply (R&D, model scaling, 'the AGI') as if these systems are created in a vacuum. I think this is how people end up with scenarios where AGIs are just doing things for their own sake, completely detached from human preferences (who are usually described as 'disempowered').
But they aren't; they are pulled and shaped by downstream demand, cost constraints, and efficiency needs. This economic reality has implications for how the technology develops. See also Drexler's CAIS model (owainevans.github.io/pdfs/Reframing…) - Drexler anticipated much of this and the core intuitions remain true, even if slightly out of date. You won’t see one omniscient agent, but a proliferation of specialized systems, models of varying sizes, and distinct products rising in parallel because that is what is economically viable.
This is why the AGI governance conversation often feels so confused. If you view AGI as a singular biological entity, you make two mistakes: safetyists project human-like 'intent' where they should be looking at incentives, and policymakers reach for a singular 'FDA' when instead they need to look into different different markets, sectors, products etc.
You can’t have a single regulator or discrete safety rules for 'The Economy' or 'The Bureaucracy,' and you won't be able to have one for 'Intelligence' either. Models still matter of course - none of this means you shouldn't test, evaluate, and understand them better - but I think we overindex on this frame a bit. And as Dean says, none of this is to downplay concerns and risks: but I do think it has implications for how to understand and address them.
Dean W. Ball@deanwball
Would be curious to read a post from @DKokotajlo explaining why his timelines have lengthened. The question I find myself asking, though, is: might the prediction error be not just about forecasting timelines incorrectly, but also flawed assumptions about the nature of “AGI” and “superintelligence” themselves? In my recent debate with @tegmark and many similar debates I’ve had over the past two years, this, rather than timelines alone, has been the crux. Typically in these debates I will argue something like “you are misapprehending the nature of ‘intelligence’ if you think ‘being really intelligent’ means ‘possessing the will and ability to dominate the world.’” This remains my view. Intelligence is powerful, but it is far from magic. Skilled forecasters can carefully model how inputs like data, compute, and the like will grow. They can extrapolate the straight lines on graphs. But all that careful modeling can still prove misleading if the forecast is based on incorrect assumptions about the nature of intelligence itself. I would encourage those who have high p(dooms) to consider whether it is not just timelines worth revising, but basic assumptions about what it is we appear to be building. Now for my caveats: none of this means “AI capabilities are leveling off.” Over the coming years I expect that AI will improve faster than the vast majority of Americans anticipate. It will an incredibly powerful and consequential technology—very possibly the most consequential development in many centuries or longer. It’s still possible that AI could cause serious job loss, though the above notes on the nature of intelligence should factor into your analysis here. There are other novel risks, too, about which I have said plenty. None of this is to downplay all concerns, risks, etc. Instead I am specifically countering the line of thinking behind the superintelligence ban, and any other argument rooted in “doom-y” assumptions about intelligence.
English
Totally, just instruct the agent that this is what you want. Codex 5-high is by far the most capable of conceptual discussion in my observation.
With Codex you can also switch in midstream to just talking to ordinary GPT-5-Pro (ie not specifically a coding model) which can be good if you’re discussing concepts
English

Like, I would prefer if at every step of the implementation where a choice comes up I was asked how I want to go about it, and that I could have a discussion before it generates code for that part. I don't like running agents that do everything for you (cuz they do it bad)
English
I want to hear you guys’ thoughts on the best way forward with LLM-assisted coding.
Personally, I don’t really want a “coding agent” that does everything for me because I want control over my code. I want more of a pair-programmer that implements things one by one that I review
English

cursor just made every $200/month copilot subscription look like a scam
dropped today with their own coding model
what took 8 hours of manual coding now takes 30 seconds
and it runs 8 versions of itself in parallel to pick the best solution
while github's charging $20/month for autocomplete, cursor built an entire autonomous dev team
composer model:
→ 4x faster than gpt/claude
→ completes full features in <30 seconds
→ tests its own code automatically
→ built with reinforcement learning on real codebases
here's what's actually wild:
most companies paying $150k/year for junior devs to do work this does for $20/month
just saved a client $253k/month migrating their dev work to cursor's multi-agent system
the intelligence gap between "we hired 3 developers" and "we deployed cursor" is getting stupid
comment "COMPOSER" and ill send the full breakdown of how to replace your dev costs with this
English
Eric Auld retweetledi

New in-depth blog post time: "Inside NVIDIA GPUs: Anatomy of high performance matmul kernels". If you want to deeply understand how one writes state of the art matmul kernels in CUDA read along.
(Remember matmul is the single most important operation that transformers execute both during training and inference. Most of NVIDIA compute is spent on it. Gaining 1% in efficiency translates to massive savings in the order of many nuclear reactors :P)
I, yet again, realized i underestimated the effort. 😅 Here is one more booklet (lol). 47 figures!
I covered:
* The fundamentals of the GPU architecture with an emphasis on the memory hierarchy, building mental models for GMEM, SMEM, and L1/L2, and then connecting them to the CUDA programming model. Along the way we also looked at the "speed of light," how it's bounded by power, with hardware reality leaking into our model.
* PTX/SASS, and how to steer the compiler into generating what we actually want (is that loop being unrolled, are we using vectorized loads like LDG.128, etc.). I've annotated one PTX/SASS example for a simple matmul kernel in excruciating detail. Even if you're new to compilers you should find this useful.
(i actually found various inefficiencies in both compilers - fun!)
* Many core concepts such as tile/wave quantization, occupancy, ILP (instruction-level parallelism), roofline model, etc. Also building intuition around fundamental equivalences: dot product as a sum of partial outer products, why square tiles are the right shape for high arithmetic intensity, etc.
* The warp tiling method - which is near SOTA assuming you can't use tensor cores, TMA, async mem instructions, and bf16. Just maximizing GPU's performance using nothing but CUDA cores, registers and shared memory.
* Finally, we step into Hopper (H100): TMA, swizzling, tensor cores and the wgmma instruction, async load/store pipelines, scheduling policies like Hilbert curves, clusters with TMA multicast, faster PTX barriers, and more.
As always lots of examples, lots of visuals. This is the first time i could see warp tiling kernel and be like "oh i get it completely". I just needed my mental image transformed into an actual image.
A few years ago I was really inspired by @Si_Boehm's excellent blog post on how matmul works, but I also found it had several errors, some unclear explanations, and it was quite outdated. Building on @pranjalssh amazing work (who did a great job building sota kernels for H100) and my own research, this is the final result.
---
Again a huge thank you to @Hyperstackcloud (GPU cloud) for giving me an H100 (PCIe) node to run some of the experiments and analysis that i needed to write this up.
Also a big thank you to my friends Aroun (who did a very thorough review of the post; Aroun's doing cool GPU/AI stuff at Magic and was previously GPU architect at Apple and Imagine, he's one of the best GPU people i know and we worked together on llm.c w/ @karpathy) and the amazing @marksaroufim! (PyTorch) for taking the time during weekend when they didn't have to. :)

English
Eric Auld retweetledi

According to the IMF, world GDP per capita (PPP) is now $25,591.
That's pretty incredible. That's about where the United States was in 1972.
What a victory for humanity.
English
@_divyansh1910 Seems right. It’s not a good mainstream strategy, it’s a niche path. True of academic math also btw
English
A post about my transition from academic math to GPU programming for ML, and an offer to mentor people on a similar path.
ericauld.github.io/2025/03/04/mat…
English

Extremely well deserved. Dr. Hatcher's book has many haters, but it's used almost universally in intro algtop classes for a reason. It would be a dream for me to produce something 0.1% as impactful as this book.
American Mathematical Society@amermathsoc
Allen Hatcher, @Cornell, will receive the inaugural Elias M. Stein Prize for Transformative Exposition for his book Algebraic Topology. Read More: ams.org/news?news_id=7…
English

If you could change one thing about PyTorch what would it be?
English

Everyone talking about the Rogan endorsement but what I really need to know is what does Ja Rule think about all this
English
This interview has fantastic, conceptual questions & answers about AI, the nature of science, and economic growth. @JosephNWalker and @LHSummers open.spotify.com/episode/3tTYHr…
English