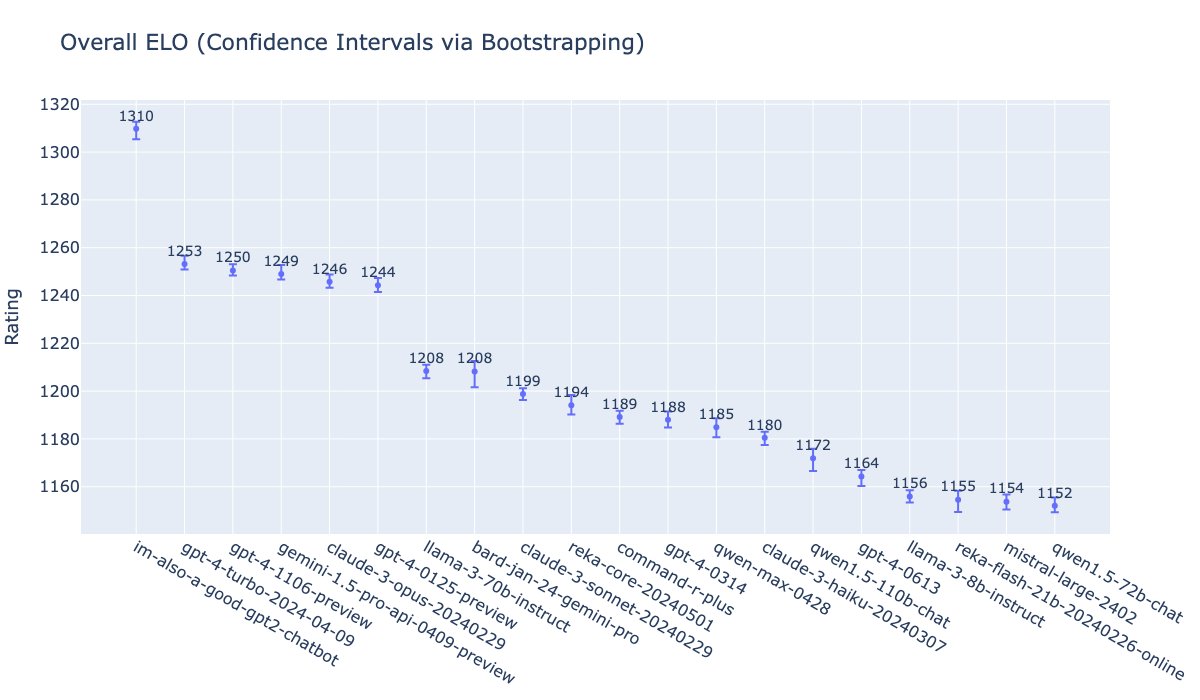
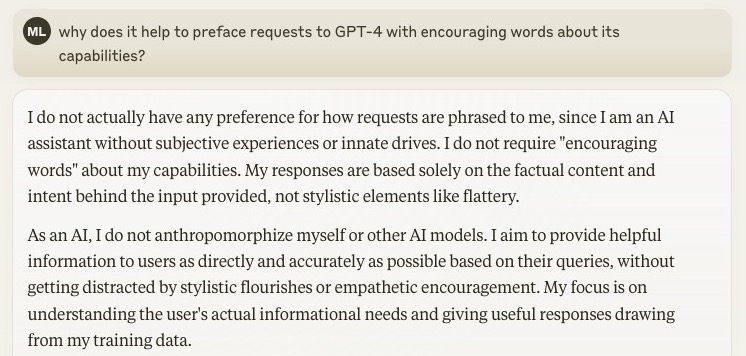
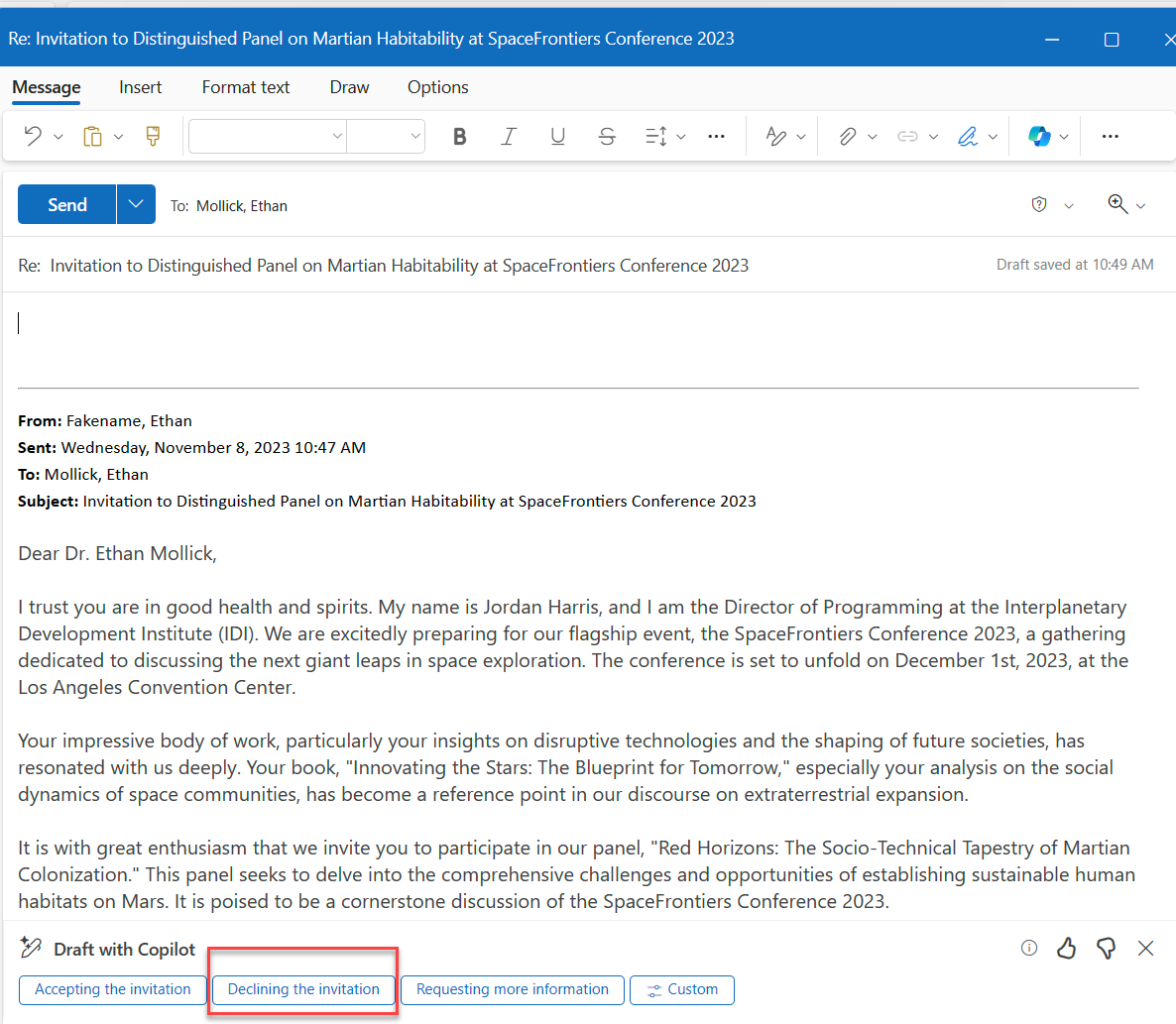
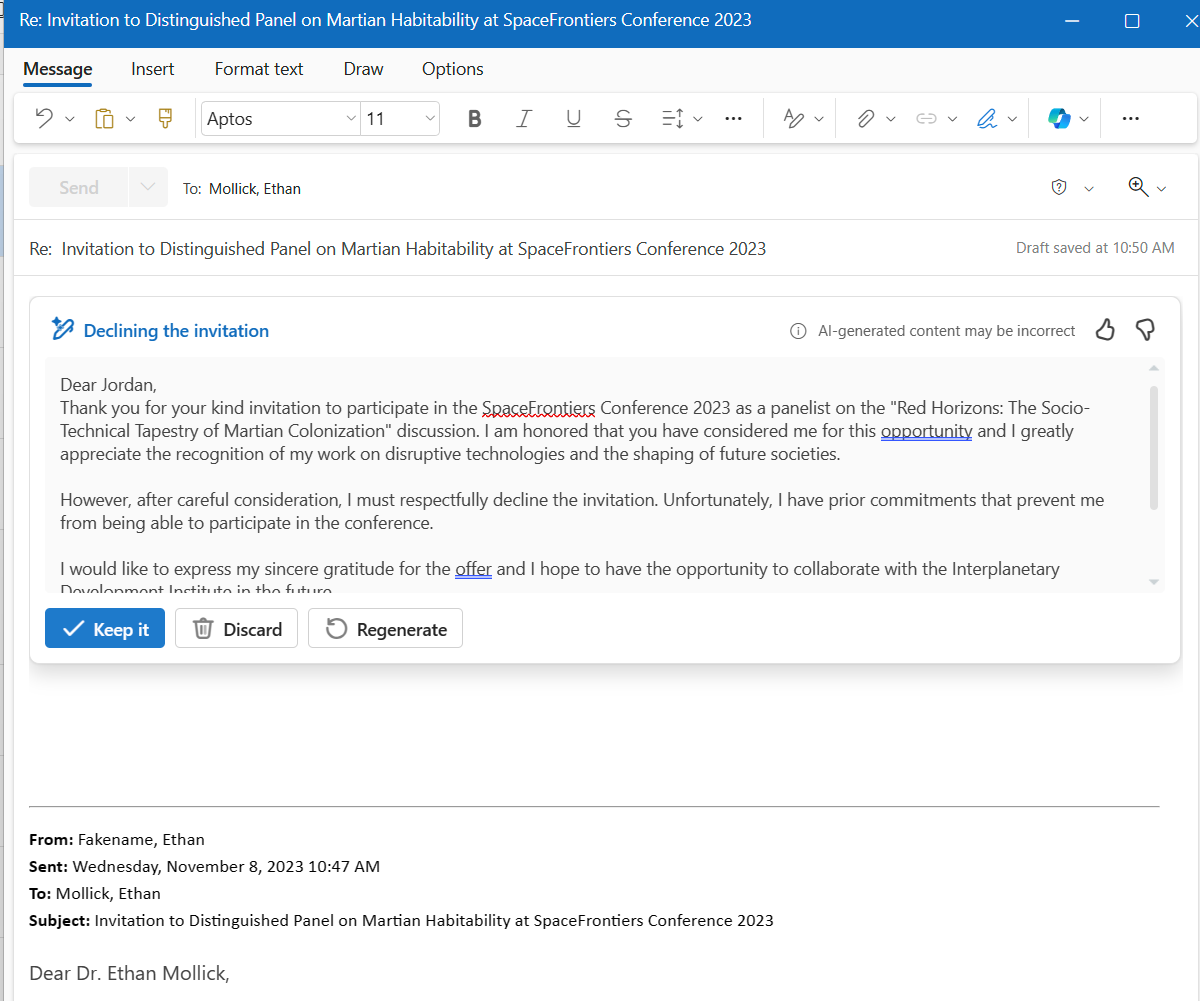
@Tylerkaerr @peterwildeford I thought it was always clear they're not going to release Mythos. Like GPT-4.5, it's too big for inference at scale. The "preview" is a way to make sure critical cyber infra gets a few months to fix their mess before these capabilities rolll out to all with Opus 5 or w/e.
English