
Michael B. Smith
4.1K posts
Michael B. Smith
@essentialexch
I am the average "admin user". Beyond the requirement for average expertise - I will complain! Consultant, Exchange/Azure/AD/PowerShell expert, Father.
Charlottesville, Virginia, USA Katılım Ağustos 2009
137 Takip Edilen982 Takipçiler

Periodically people ask me "Why don't you post to Twitter anymore?" and I have to say, I post here every day, just most people don't see me post anymore
If you're one of the few, probably using Following - hi 👋
English
English

At the @Microsoft + @AnthropicAI AI Startups event last night I asked: why are Claude Desktop and Claude Code still second-class citizens on Windows?
Plenty of nods. Windows is the world's most-used OS. With Microsoft in the mix now, this is the moment to fix it.

English

Since this escaped the Microsoft bubble, the reason for cmdlets this long is because they are auto-generated from the URI
That is done using AutoREST, which hilariously is deprecated and retires end of next month:
github.com/Azure/autorest
I don't think typespec will change this
vx-underground@vxunderground
Microsoft: PowerShell is simple and easy to use. Actual PowerShell command: Remove-MgIdentityAuthenticationEventFlowAsOnGraphAPretributeCollectionExternalUserSelfServiceSignUpAttributeIdentityUserFlowAttributeByRef No, this isn't a joke. This was noted by @NathanMcNulty
English
@xoofx I'm 63. Been programming for 47 years. I built that first computer from scratch.
English

I'm 53, I've been programming for 42 years, AMA.
I'm sure that someone will quote me with a much longer streak 😁
Dmitrii Kovanikov@ChShersh
I'm 32. I've been programming for 16 years. AMA
English

@essentialexch @JenMsft Why would they align? Segoe UI is not mono-spaced font. Whole text is right aligned anyway in that column.
English
We're rolling out a change in Experimental so file sizes in the File Explorer Details view now display using appropriate units (KB, MB, GB) instead of KB-only, to make them easier to understand at a glance
Do you like it? 😊
learn.microsoft.com/windows-inside…
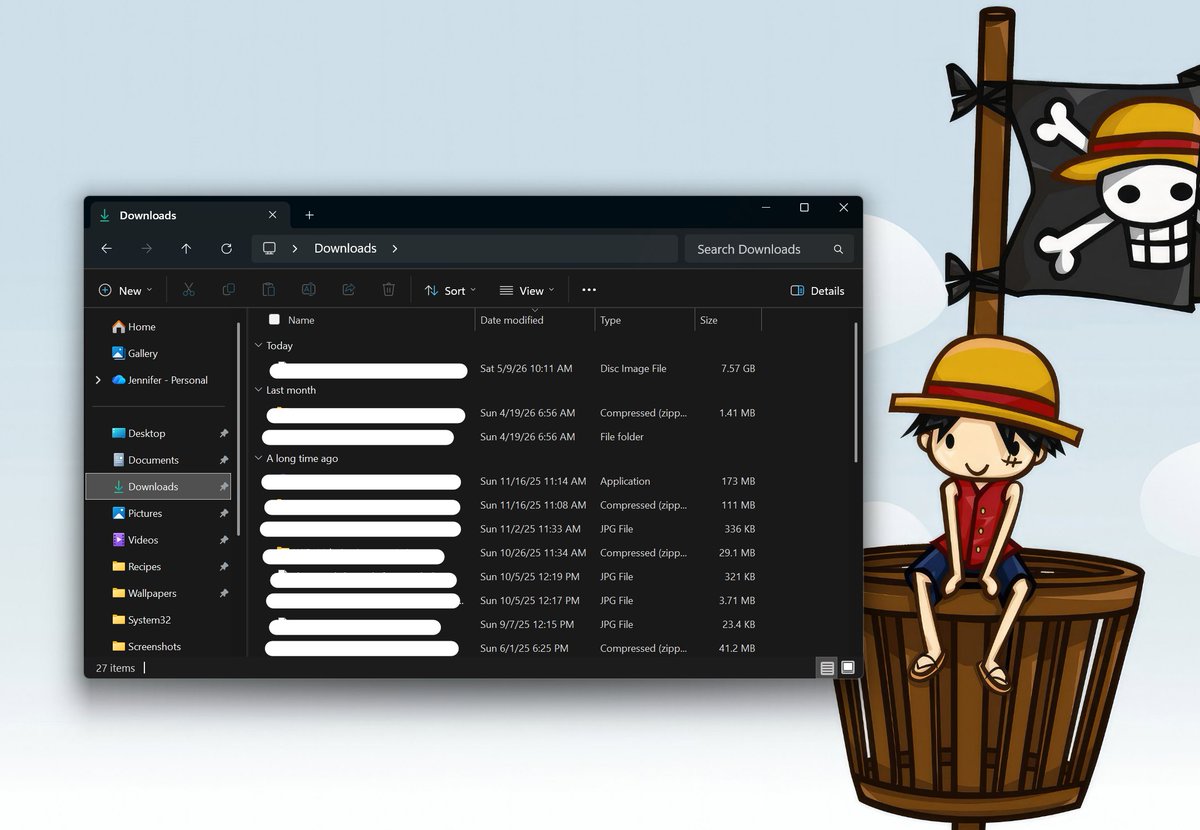
English
@JenMsft And an OCD comment - the KB and MB aren't aligned - and I presume that GB wouldn't be either. ARGH. :-)
English
@donasarkar @msexcel @msonenote Oh, I imagine you spend a good bit of time and calendaring in Outlook as well. :-)
English

I feel attacked and yes, I do EVERYTHING in my life and work and travel in @msexcel and @msonenote and that’s about it 🤷🏽♀️
memes.xlsx@ExcelHumor
English
@Slav636 'Cuz you know IPv8 won't actually be fully back-compat...
English
@Its_Nova1012 the phrase is "old fart" thank-you-very-much.
English

Michael B. Smith retweetledi


Compliance is not security. It’s bad for sec, as it diverts focus and resources from things that matter. Context is important.
spencer@techspence
What’s the cybersecurity hill you’re willing to die on? imgflip.com/i/aq4man
English
Ahem.
Owen Gregorian@OwenGregorian
Coding Was Never the Hard Part | Koushik Dasika, Hacker News What I Wish Every Business Leader Knew About AI and LLMs There’s a lot of excitement right now about AI making software development faster. Agentic coding is real, Claude Code, OpenAI Codex, and Gemini are real, and so are the open source alternatives running locally via Ollama: DeepSeek, Qwen, Gemma, Llama, and more. The productivity gains are real [1]. The marketing around these tools promises that they solve everything. And in the background, AI is getting blamed — or credited, depending on who you ask — for a wave of engineering layoffs. But most of the conversation is happening inside a very narrow frame, one that makes total sense if you’ve never worked in engineering, and makes almost no sense if you have. This post is my attempt to bridge that gap. Not to push back on AI, not to gatekeep engineering, but to give business leaders a clearer picture of how engineering actually works so we can all get more out of it together. Let me get something out of the way upfront. I am not an AI skeptic. I use AI every single day across everything I do. It makes me a better engineer than I ever was. This is not a doomer post. This is about nuance, specifically the gap in understanding between business and engineering that AI has made way more visible. If you’ve ever looked at your engineering team and wondered why tickets take so long, this one’s for you. Most Work Is Task-Based. Engineering Isn’t Think about how most departments operate. Sales has a pipeline. Operations has checklists. Even with AI tools like Claude Cowork, the unit of work is a task. You do it, you check it off, you move on. Faster execution almost always means better outcomes. The variance is small. Engineering is fundamentally different. Engineering follows the scientific method. The coding part? That’s step E. For a senior engineer, that’s roughly 20% of the actual work. The other 80% is research, planning, designing the right solution, and then collecting and interpreting results. This is why “plan mode” in tools like Claude Code, Codex, and Gemini resonates so much with engineers. It mirrors how we actually think. And it’s no coincidence that most best practices posts are really just about improving the feedback loop at the end. And that’s only talking about feature development. It doesn’t account for everything else on an engineer’s plate: code reviews, meetings, fire drills, on-call rotations, admin work, mentoring, documentation, and just keeping the existing system alive. Software has entropy. Left alone, it actively tends toward failure — dependencies go unmaintained, infrastructure drifts, things quietly rot. Sweeping the floors is a very real part of the job. Nobody is shipping features the whole time. The 20% figure is already generous. Here’s the math that should stop you mid-sentence at your next planning meeting. If coding is 20% of an engineer’s job, a 50% speedup in coding yields only about a 7% total productivity gain. This isn’t just intuition — it’s known as Amdahl’s Law. The formula: S = 1 / ((1 − p) + p/s), where p is the fraction of work being sped up and s is the speedup factor. Plug in coding as 20% of the job (p = 0.20) and a 50% speedup (s = 1.5): S = 1 / (0.80 + 0.20/1.5) = 1 / 0.933 ≈ 1.07 This law states that the speedup you get from optimizing one part of a system is limited by how much of the total work that part actually represents. If the sequential bottleneck is small, no amount of parallelization, or AI acceleration, changes the overall outcome much. AI can help with the other phases too, but most people aren’t even framing it that way yet. What AI Is Actually Great For There’s no shortage of articles about what AI does well so I won’t rehash all of it. Here’s where I actually find it valuable day to day: - Rubber duck and scribe. Thinking out loud with AI to process problems is underrated. It’s like having a very patient, very knowledgeable colleague available at 2am. - Kills activation energy. Starting is the hardest part of most tasks. AI lowers that bar considerably. - Documentation and tests. The stuff engineers know they should write but hate writing. AI is great at this. - Greenfield scaffolding. Getting a project off the ground quickly. AI shines here. - Writer’s block. Specs, RFCs, PRs, emails. AI handles the blank page problem well. - Raises the floor on your weaknesses. Where you’re strong, its shortcomings are easy to see. Where you’re weak, it trivially lifts you to at least median level. This is actually what’s driving most of the excitement around AI — and it’s something engineers and experts need to lean into. Work has many dimensions. Focus on your strengths, let AI shore up the rest, and you’re operating at a higher level overall. (This post exists because I can’t write. I had opinions. Claude had sentences.) AI is useful at every stage of the scientific method. The key word is useful, not autonomous. That distinction matters a lot. AI Makes the Most Common Decision, Not Necessarily the Best One These agentic coding tools (Claude Code, Codex, Gemini, and open source models like DeepSeek, Qwen, Gemma, and Llama) are impressive. For a brand new app with no prior context, they move fast. But here’s what they’re all doing: making the most statistically common decision for your situation, not the best one for your situation. They don’t have your context. And your context is everything. There’s a pattern worth naming in conversations about AI. The people most confident that AI can just replace engineers tend to be the ones who use it the least in a real engineering context. The more you actually work with it day to day, the more you see its edges. It’s not a knock on AI. It’s just how expertise works. Here are real variables that shape engineering decisions that no LLM will ever know on its own: - You went to a conference and talked to a library maintainer who is shipping something in 6 weeks that makes your whole problem easier - A dependency you rely on just went unmaintained - A cloud provider or SaaS changed its pricing model after the model’s training cutoff - Your team is strong at X and weak at Y, so you weight solutions differently - The “correct” solution would take 3 months. You need to ship in 3 weeks. So you pick the approach that’s 80% right but lets you pivot cleanly later None of that is in the model. A senior engineer holds all of that in their head and navigates it constantly. That’s not coding. That’s judgment. No two projects are alike because the context is always different. But projects rhyme. That’s the trap — the surface looks familiar, so shortcuts feel safe, until the context underneath diverges and the decision falls apart. This is also why, regardless of who or what wrote the code, production PRs deserve the same review process. If an agentic tool wrote a feature, it should go through the same scrutiny as if a junior engineer wrote it, because while the model may have many of the same blind spots as a junior engineer, it also has technically unique blind spots as well: no organizational context, no awareness of the edge cases your team has learned the hard way, no understanding of the SLA implications of that one innocent-looking change. The code might look clean. That doesn’t mean it’s right for your system. The Variance Problem (And Why the 10x Engineer Is Real) For task-based roles, the variance in outcomes is fairly small. A good salesperson might close 2x more than an average one. For engineering, the variance is enormous. There are infinite ways to solve any problem, and you’re relying on your engineers to navigate a multidimensional tradeoff space that reflects your company’s values, constraints, and goals. No two engineers have the same skills — the dimensions are too many: frontend, backend, databases, eye for design, people skills, domain knowledge, system intuition. Every engineer is a unique combination of all of these. This is why the term “10x engineer” exists. It’s not mythological. Price’s Law puts a number on it: roughly half of all output in a given field comes from the square root of the total contributors — originally observed in scientific publishing, but the pattern holds across knowledge work. On a team of 25 engineers, about 5 of them are doing half the meaningful work. The difference between a great engineer and a mediocre one is genuinely that large on complex problems. And it cuts the other way too. There are engineers out there where the best possible outcome for your business is that they do nothing. Negative impact is real. The -10x engineer is just as real as the 10x engineer. The floor and ceiling are both extreme. When business instinct says “just hire more engineers to go faster,” that’s fighting against Brooks’s Law: adding people to a late software project makes it later. The ramp-up cost, the communication overhead, the context transfer. It all slows the team down before it speeds it up, if it ever does. Engineers are expensive and hard to find, which makes the variance problem even more consequential. You’re not hiring a commodity. You’re hiring judgment. The Tacit Knowledge Problem When business people or agentic coders peer into an engineering codebase or process, they often hit a wall. Things that seem arbitrary. Decisions that aren’t documented anywhere. Patterns that feel inconsistent. This is tacit knowledge: shared context that engineers carry culturally that never gets written down. Why doesn’t it get written down? Two reasons: - Documentation ages. Without constant maintenance, it drifts from reality fast. Outdated docs are often worse than no docs. - Maintaining docs is a full-time job. One that generates zero revenue. It’s hard to justify when there’s a roadmap to ship. “Just have AI write it” is a reasonable reaction, but AI context windows are precious. Research has shown that early context disproportionately influences the outcome of a session [2]. Flooding it with documentation has real tradeoffs. This is still an evolving area but it’s not a solved problem. The tacit knowledge gap is one of the biggest reasons engineering looks opaque from the outside. It’s not gatekeeping. It’s just how knowledge-dense work accumulates over time. Moving Fast Has a Hidden Balance Sheet “Producing the wrong thing fast” makes sense as a strategy. More attempts at product market fit means better odds of finding it. The logic is sound. What business doesn’t see is the engineering balance sheet on the other side. Every attempt leaves behind maintenance cost and operations cost. Every feature built on a rushed foundation makes the next change more expensive. The cost of change compounds over time. Every engineering discipline you’ve ever heard of (design patterns, frameworks, modularity, separation of concerns, abstraction) exists for exactly one reason: to slow the growth of complexity. Not eliminate it. Slow it. This is Gall’s Law in practice: complex systems that work always evolved from simpler systems that worked first. Skip the simple working foundation and you’re building on sand. Even with great engineers doing everything right, complexity grows. The goal is to keep it logarithmic. Under deadline pressure, that growth rate goes up. Corners get cut, the foundation gets shakier with every sprint. At some point you hit a wall. Changes that used to take a week take a month. The codebase becomes so entangled that pivoting is nearly impossible. And if the market shifts at that moment, the business can’t respond fast enough. The company can die from its own technical debt. This isn’t theoretical. I’ve been laid off twice from startups where exactly this happened. The market shifted, engineering couldn’t pivot fast enough, because of decisions made years earlier under pressure to move fast. Complexity is a fact of life in engineering unless you’re truly throwing everything away and starting fresh. The only question is how fast it grows. Complexity Is a Sign of Success. It’s Also a Trap Every long-lived, successful codebase becomes extremely complicated, not because engineers were sloppy, but because the reality it models is complicated. Software that survives long enough is just a mirror of the real world. And the real world is messy. Hyrum’s Law explains part of why this is so hard to change. With enough users, every observable behavior of your system, including the bugs, the quirks, the undocumented side effects, becomes something someone depends on. You can’t just fix it. You have to manage it. This is why mature systems are so hard to refactor even when everyone agrees they should be. This connects directly to the Innovator’s Dilemma. Pivoting fast is easy when you have nothing to lose. The more successful you become, the harder it gets: - Existing users who depend on current behavior - SLAs you’re contractually obligated to hit - Integrations that break if you touch the wrong thing - Years of business logic baked into the codebase This is why scrappy startups can outmaneuver established players with a fraction of the resources. It’s not that big companies are lazy or bureaucratic. Their engineering surface area is enormous and every change has blast radius. The cruel irony is that success makes you slower. Businesses that don’t understand this get frustrated at exactly the wrong moment and push for pivots that engineering physically cannot deliver cleanly. Not because engineers are dragging their feet, but because the weight of all that prior success is sitting on top of every decision. Complexity isn’t a failure. It’s a consequence of survival. What Business Should Actually Push For The breathless AI posts are all about coding speed, and that makes sense. Coding is the hardest part for non-technical people. It’s the most visible blocker when you don’t have a technical background. But for engineers, coding is not the hard part. It never was. The hard parts are everything around it. You think coding is the bottleneck because coding is your bottleneck. It isn’t Engineering’s. This is also where Goodhart’s Law bites hard. When velocity or ticket throughput becomes the target, it stops being a good measure of actual progress. Teams optimize for the number, not the outcome. You get faster delivery of the wrong things, or shallower solutions to the right things. If you want to measure something meaningful, measure the quality of decisions made in the research phase and the signal coming back from the results phase. That’s where the real work happens. Protect the research phase. Rushing engineers to “just start coding” often produces the wrong thing fast. And as we just covered, the wrong thing fast has compounding costs you won’t feel until it’s too late. Remember Hofstadter’s Law: it always takes longer than you expect, even when you account for that fact. The research phase won’t eliminate that gap — nothing does — but skipping it guarantees you start with less information than you need. Cutting it doesn’t save time. It defers the cost. Invest in the feedback loop. Observability, metrics, user research. The results collection phase is where you find out if you built the right thing at all. Most teams underinvest here badly. Optimize for the medium term. The instinct to push for faster execution makes sense in the short term, but planning — timeboxed and kept within reason — rarely causes problems and prevents them far more often than not. There is a reason the military saying slow is smooth, smooth is fast has survived as long as it has. Taking the time to move deliberately through the research and planning phases is not lost time. It is the thing that makes execution fast when it counts. The Call to Action: Collaborate in the Process. Have the Conversations The whole thesis of this post is that engineering follows the scientific method. Research, hypothesis, execution, results. That’s the loop. And the single most important thing business can do is understand that loop and engage with it, especially at the beginning. Here’s why the beginning matters so much. Scope reduction has the highest leverage in the research phase. If business and engineering sit down together before a single line of code is written, a 10-minute conversation about priorities can eliminate weeks of work. “We don’t actually need this for v1” is worth infinitely more before the architecture is designed than after. Once you’re in execution, changing scope means undoing decisions, rewriting code, and managing the complexity debt that’s already accumulated. The earlier the conversation, the cheaper the tradeoff. Conway’s Law tells us that organizations build systems that mirror their communication structure. If business and engineering are siloed, the product will reflect that silo: disconnected pieces that don’t quite fit together, built by teams optimizing for their own side of the wall. The fix isn’t a process change. It’s a conversation change. The other place collaboration matters is at the results phase. Engineering needs to know if what shipped actually worked. Did users adopt it? Did it hit the business outcome it was supposed to hit? Without that signal, the next research phase starts blind. Business holds a lot of that signal and often doesn’t realize engineering needs it to close the loop. Sharing outcomes isn’t just a nice-to-have. It’s what makes the scientific method actually function as a cycle instead of a one-way waterfall. So the ask is concrete: get in the room during research, align on outcomes before execution starts, and close the loop after results come in. I know everyone is slammed. But the ask is small relative to the cost of not doing it. The cost of that conversation is an hour. The cost of not having it could be months of building the wrong thing, compounding into technical debt that eventually boxes the business in entirely. This is also where a lot of the engineer pushback on AI mandates is coming from. AI can be enforced top-down as an initiative, but it is never accountable for the outcomes. It isn’t on call when something breaks. It isn’t carrying the weight of every feature added to a codebase that compounds in complexity over time. Engineering is. It is also worth noting that AI companies have a direct financial interest in being deployed against large, complex codebases — that is a lot of tokens. The incentives are not perfectly aligned with yours. The layoffs are part of this picture too. Big tech has been cutting engineering headcount at scale, and AI has been cited as both the justification and the path forward. That is the context engineers are operating in when they are asked to adopt these tools. When something built with AI goes wrong, the tool doesn’t take the blame. The engineer does. That frustration is not resistance to change. It is a reasonable response to a real asymmetry. The ask is simply to be honest about it. Treat AI like the tool that it is, deploy it where it genuinely helps, and don’t paper over the tradeoffs. That’s the only way the collaboration actually works. Where This Leaves Us Agentic coding is here to stay. AI is here to stay. I use both constantly and I’m not arguing against either. I’m arguing for shared understanding. Engineers aren’t slow. They’re navigating tradeoffs you can’t see, with context that isn’t written down, in a problem space with enormous variance in outcomes. Every decision they make is either slowing or accelerating a complexity clock that will eventually come due. AI makes all of us better at this, but it doesn’t replace the judgment. Not yet. The most valuable thing a business leader can do right now isn’t push for faster coding. It’s create the space for engineering to think, plan, and collaborate. That’s where the real leverage is. And it starts with a conversation. Read more: koushikdasika.com/blog/coding-wa…
English
@SquiblydooBlog I’m looking forward to the time quantum computers will conquer factoring of the number 1665. I’ll be ready.
English
It was inevitable, but EV validation process was comprehensively compromised in this case.
I wonder if the commercial CA industry will now come up with XEV, or PQV (post-quantum validation), to keep charging gullible customers premium prices.
Squiblydoo@SquiblydooBlog
We didn't know how an actor was using EV Certificates issued to Lenovo and others. We now do. From DigiCert's incident report: "the threat actor used a compromised analyst endpoint to access DigiCert's internal support portal. The threat actor used a limited function within the customer-support portal which allows authenticated DigiCert support analysts to access customer accounts from the customer's perspective to facilitate support tasks. The threat actor was able to use this function to access initialization codes for orders that were approved but pending delivery for EV Code Signing certificate orders across a finite set of customer accounts." "Possession of the initialization code, combined with an approved order, is functionally sufficient to generate and retrieve the corresponding certificate." The full report can be found here and explains the incident in great detail: bugzilla.mozilla.org/show_bug.cgi?i… The report mentions "Where we got lucky: A community member involved in security research reported the evolving pattern of misused certificates and engaged in dialogue with our support team. Without that report, the undetected compromise of ENDPOINT2 and the associated mis-issuance might have remained undiscovered for a longer period." Special thanks goes to the regular contributors to the Cert Graveyard; @g0njxa , @malwrhunterteam , and others. Also special thanks to DigiCert: this report has a high level of transparency, which is warranted, and also well executed.
English
@samilaiho It would be... useful... for someone to accumulate all the various ways that are required to remove ALL of Copilot from a device. Including this one.
English

Microsoft Releases Enterprise Policy Option to Disable Windows 11 Copilot gbhackers.com/microsoft-ente…
English
@JenMsft I think they do - it's just not publicly exposed. If you are a "rater" for comments, you often get asked "should this comment be applied to the 68 other posts showing the same image?" - so obviously it knows.
English
Sometimes I wish Twitter had a repost sleuth bot like they have on reddit - I bet numbers for some of the images would be crazy
English
@davepl1968 60 years for AI. To wit: Eliza sites.google.com/view/elizagen-…
English

Imagine programmers had been working on a piece of code for 50 years and finally decided it would never actually compile.
Sabine Hossenfelder@skdh
String theory didn't just fail, it's far worse.
English
@decentprints @davepl1968 sure. it could hallucinate the hell out of it!
English

@davepl1968 I bet Claude could do this given enough token credits
English