Sabitlenmiş Tweet

Created with @NotebookLM after discussing these topics with @Cyndesama @tensorqt @Niccolg92 and few others
English
Fabrizio Milo
2.3K posts
@fabmilo
LF angels investors (inception phase) AI for Software Development at Scale. I believe: - English is the new programming language - Code will eat the world

Are you up for a challenge? openai.com/parameter-golf
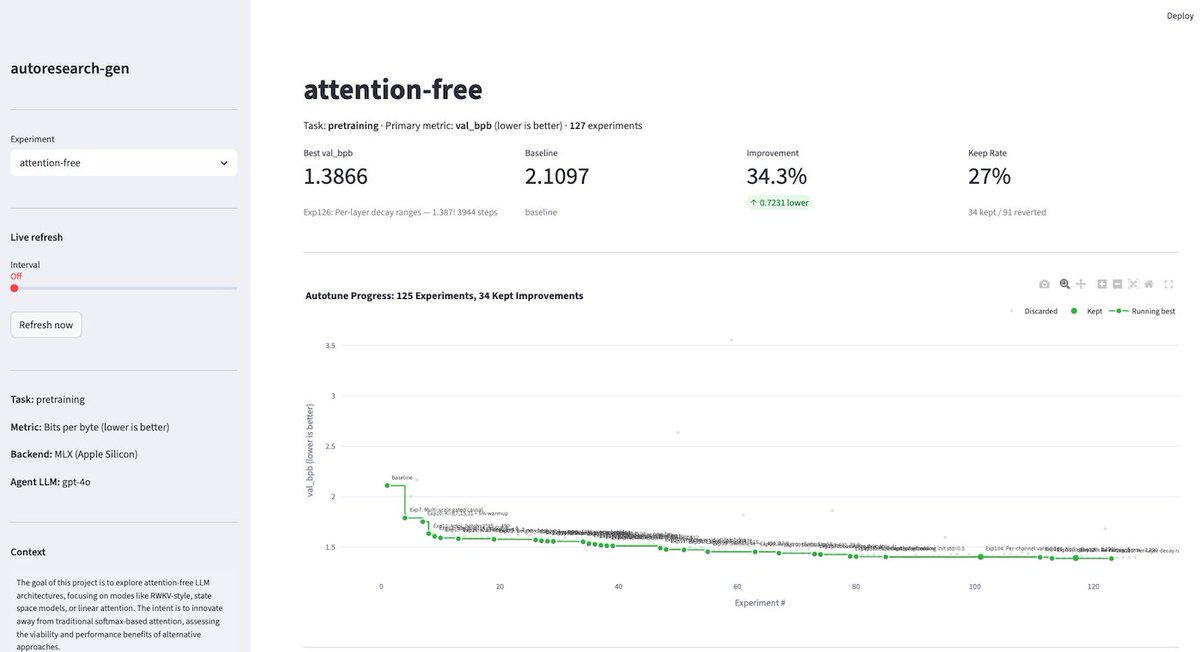
The newest model in the Mamba series is finally here 🐍 Hybrid models have become increasingly popular, raising the importance of designing the next generation of linear models. We've introduced several SSM-centric ideas to significantly increase Mamba-2's modeling capabilities without compromising on speed. The resulting Mamba-3 model has noticeable performance gains over the most popular previous linear models (such as Mamba-2 and Gated DeltaNet) at all sizes. This is the first Mamba that was student led: all credit to @aakash_lahoti @kevinyli_ @_berlinchen @caitWW9, and of course @tri_dao!



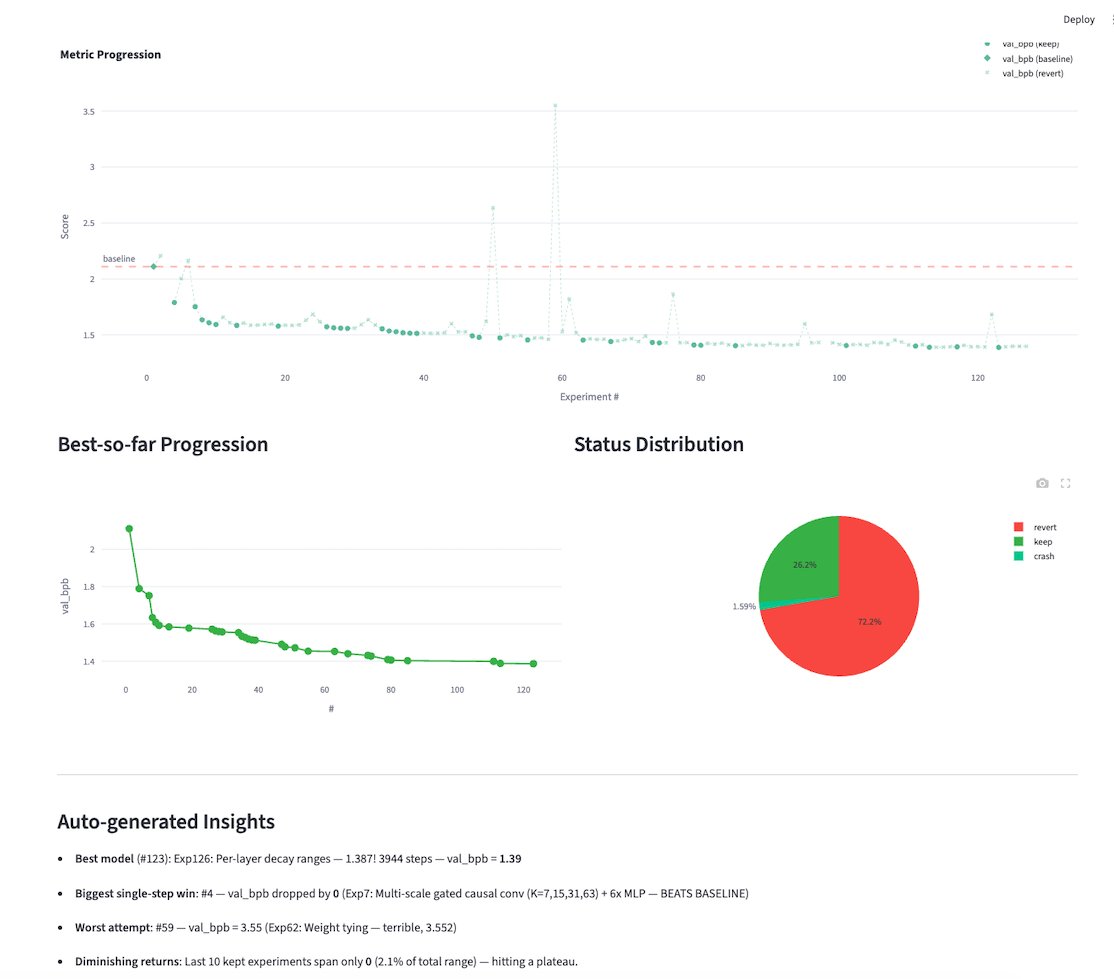




Asymmetric hardware scaling is here. Blackwell tensor cores are now so fast, exp2 and shared memory are the wall. FlashAttention-4 changes the algorithm & pipeline so that softmax & SMEM bandwidth no longer dictate speed. Attn reaches ~1600 TFLOPs, pretty much at matmul speed! joint work w/ Markus Hoehnerbach, Jay Shah(@ultraproduct), Timmy Liu, Vijay Thakkar (@__tensorcore__ ), Tri Dao (@tri_dao) 1/
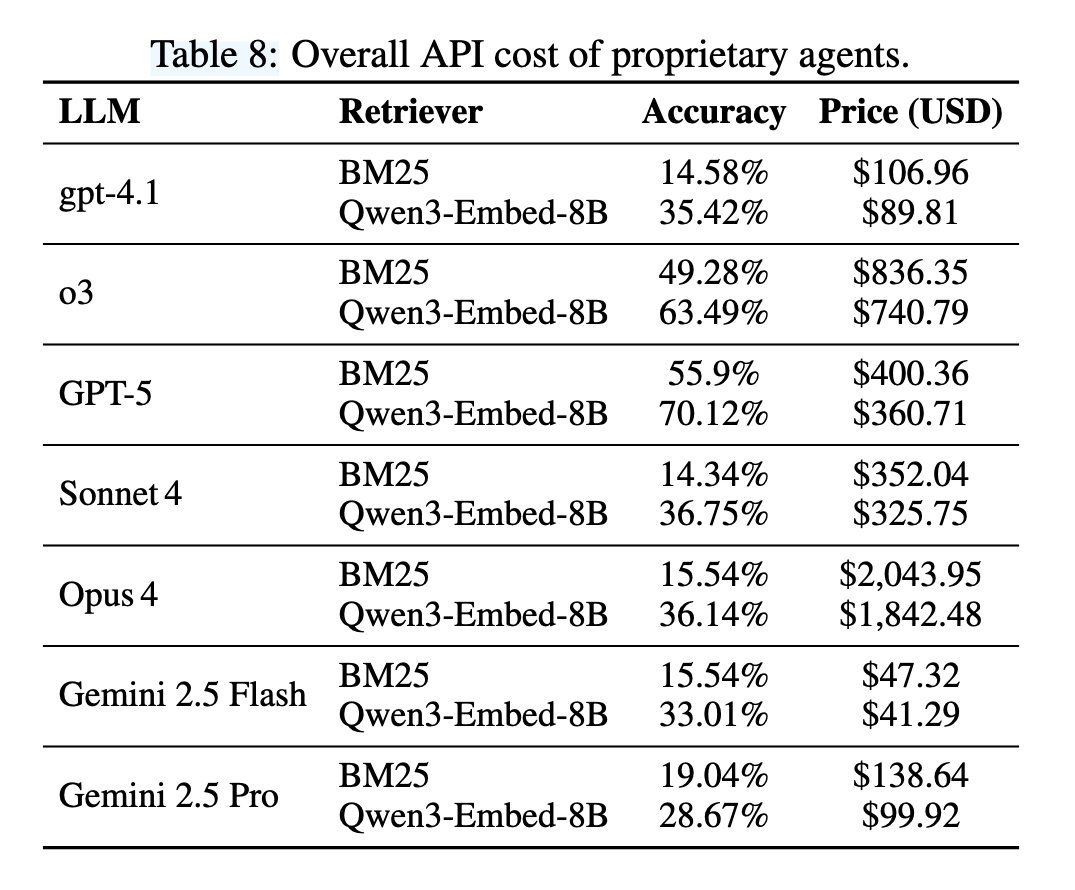

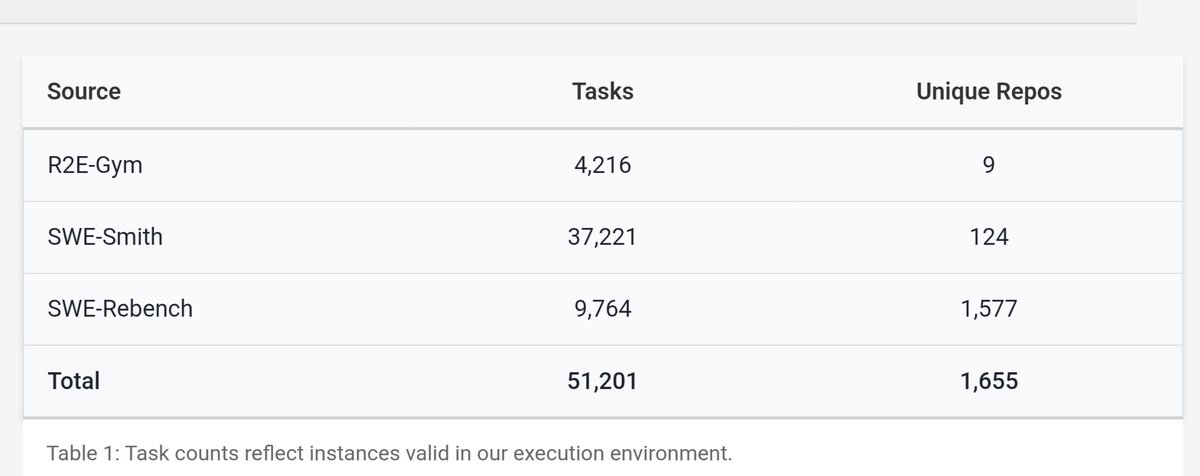
We’re open-sourcing CoderForge-Preview — 258K test-verified coding-agent trajectories (155K pass | 103K fail). Fine-tuning Qwen3-32B on the passing subset boosts SWE-bench Verified: 23.0% → 59.4% pass@1, and it ranks #1 among open-data models ≤32B parameters. Thread on the data generation pipeline 🧵
