Yunzhen Feng retweetledi

Yunzhen Feng
134 posts

@feeelix_feng
PhD at CDS, NYU. Ex-Intern at GenAI, FAIR @AIatMeta. Previously undergrad at @PKU1898




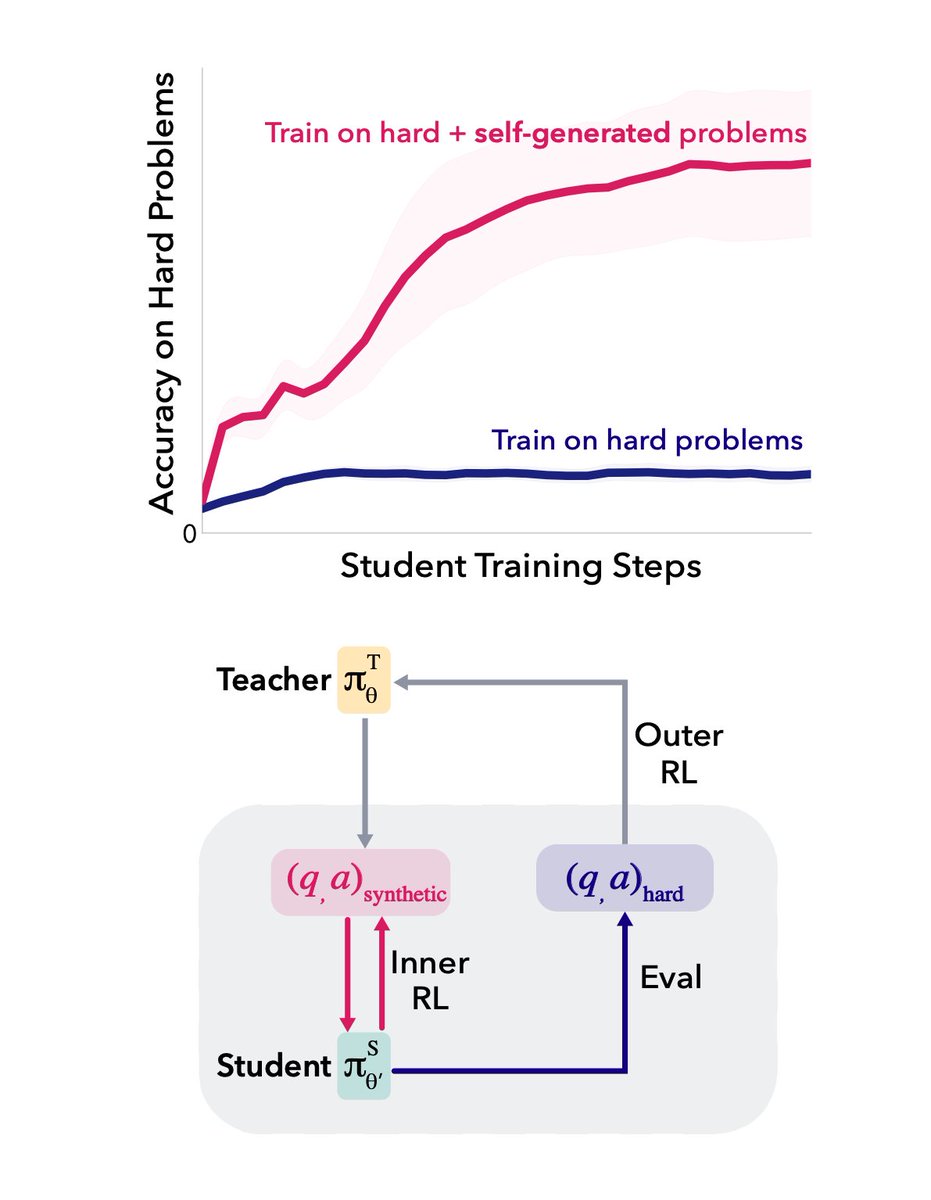



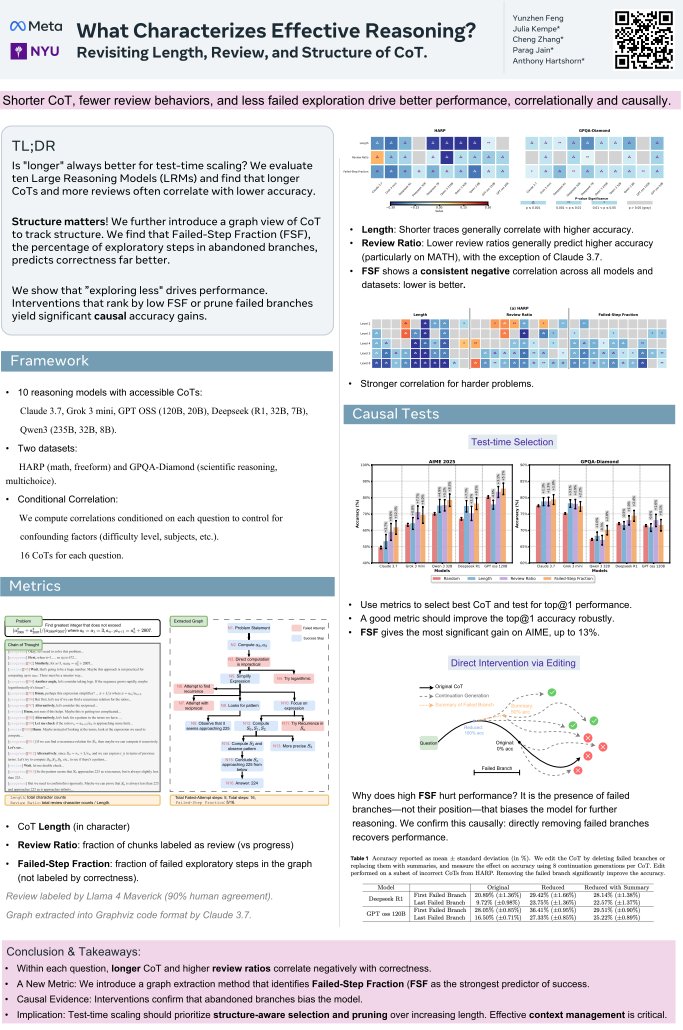














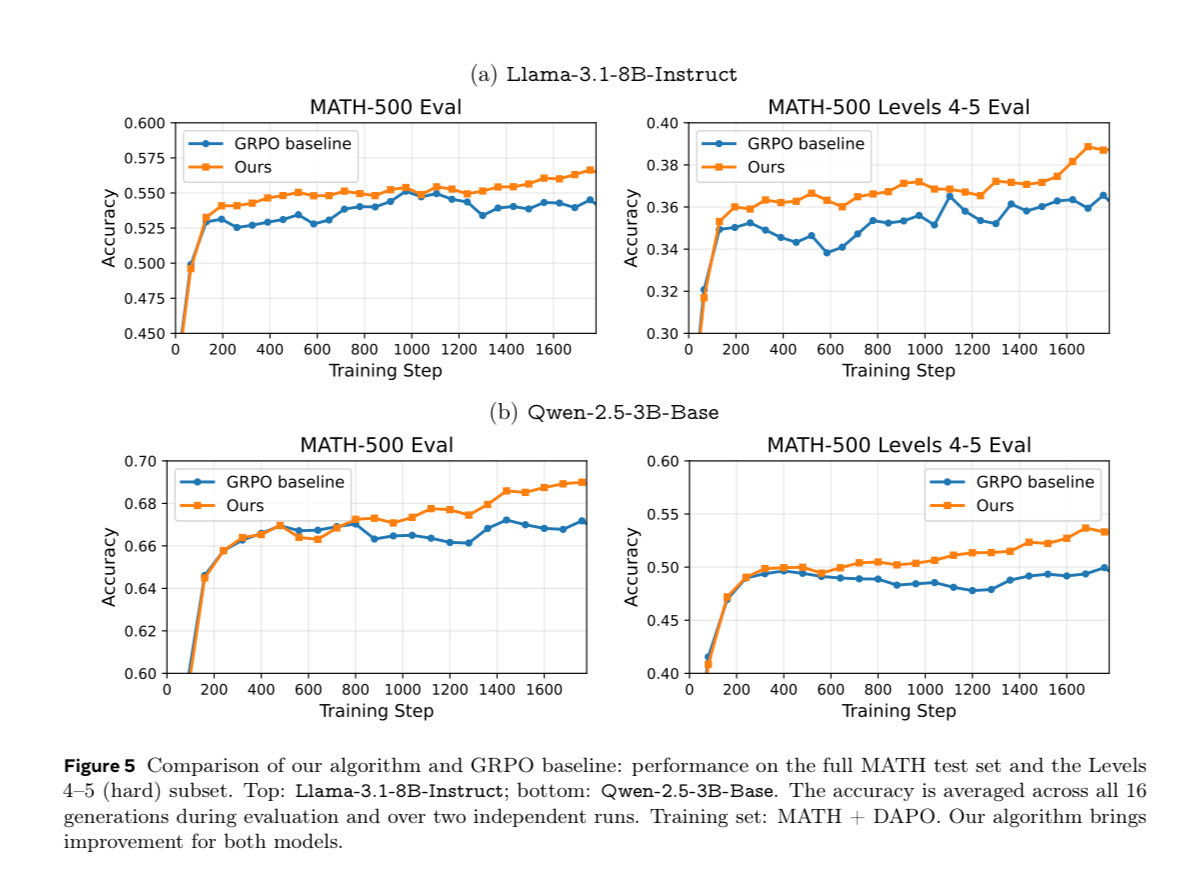
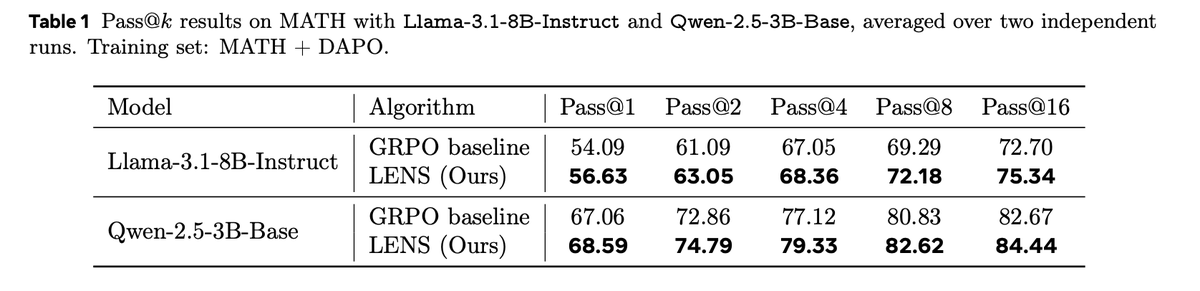
Current GRPO wastes compute on negative groups — when all K samples are wrong, you get zero gradient despite full generation cost. We propose a principled fix by bridging reward modeling and policy optimization: 👉 Penalize highly confident wrong answers more to create signal.🧵