
Felipe Albuquerque
448 posts

Multi-document RAG is hard. The article below shows that the OpenAI Assistant API does much better on single documents vs. multiple documents.
We have a ton of resources in @llama_index for modeling multiple documents, from most complex to least complex - check it out 👇
- Multi-document agents: docs.llamaindex.ai/en/stable/exam…
- Document Summary Index: docs.llamaindex.ai/en/stable/exam…
- Sub-question query engine: docs.llamaindex.ai/en/stable/exam…
- Auto-retrieval: docs.llamaindex.ai/en/latest/exam…
LlamaIndex 🦙@llama_index
Head-to-head 🥊: LlamaIndex vs. OpenAI Assistants API This is a fantastic in-depth analysis by @tonicfakedata comparing the RAG performance of the OpenAI Assistants API vs. LlamaIndex. tl;dr @llama_index is currently a lot faster (and better at multi-docs) 🔥 Some high-level takeaways: 📑 Multi-doc performance: The Assistants API does terribly over multiple documents. LlamaIndex is much better here. 📄 Single-doc performance: The Assistants API does much better when docs are consolidated into a *single* document. It edges out LlamaIndex here. ⚡️ Speed: “The run time was only seven minutes for the five documents compared with almost an hour for OpenAI’s system using the same setup.” 🛠️ Reliability: “The LlamaIndex system was dramatically less prone to crashing compared with OpenAI's system” Check out the full article below: tonic.ai/blog/rag-evalu…
English
@danielganjaman Infelizmente esse fenômeno não é exclusivo no mundo da música, os algoritmos hj ditam boa parte da iteração humana como um todo, não existe mais o interesse orgânico e genuíno. Muito boa reflexão!
Português

Nos últimos tempos eu venho analisando a cena musical sob um outro prisma e algumas conclusões me deixaram muito desanimado. Basicamente, a influência q a pandemia teve no mercado estabeleceu um novo paradigma, onde por mais contraditório q seja, a música perdeu protagonismo. +
Português
QME

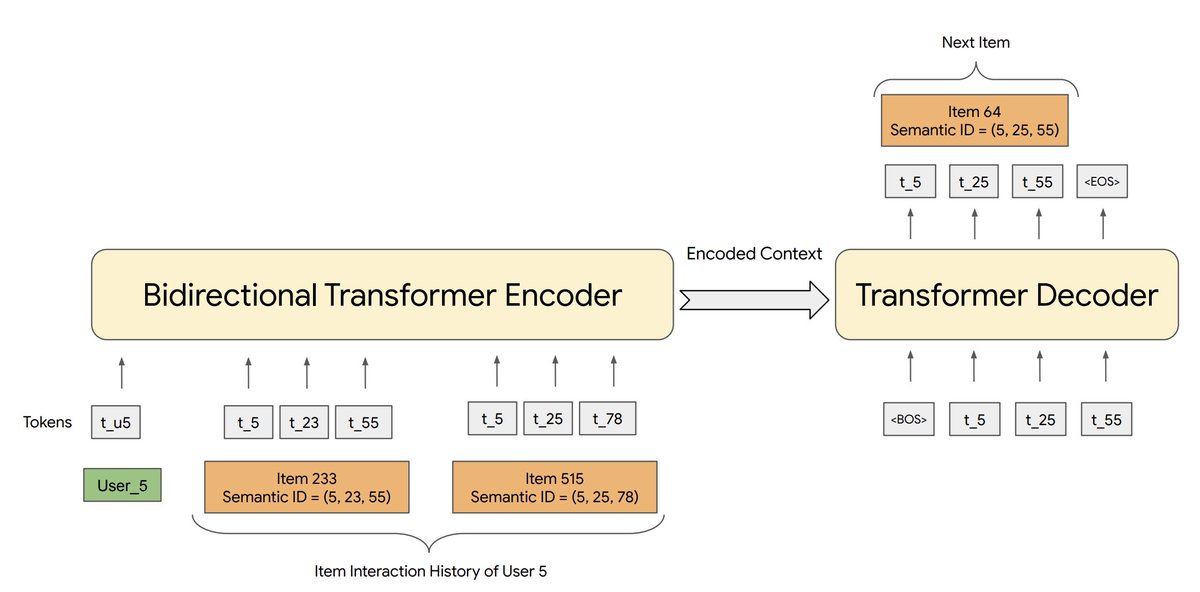
Happy to share our recent work "Recommender Systems with Generative Retrieval"!
Joint work with @shashank_r12, @_nikhilmehta, @YiTayML, @vqctran and other awesome colleagues at Google Brain, Research, and YouTube.
Preprint: shashankrajput.github.io/Generative.pdf
#GenerativeAI
🧵 (1/n)
English
Português



As 5 melhores plataformas de freelance para dados!! Segue o fio! 🧶
Português

Remote work is the future.
There are millions of remote jobs out there.
Here are 20 sites to get a remote job that pays in USD:
English


@FelippeRegazio @kazzkiq Ja existe pesquisa nesse sentido, inclusive da openai openai.com/blog/new-ai-cl…
Português

É galera, começou a corrida. Um amigo me mostrou hoje um produto que ele ta colocando no mercado:
Um app completo e integrado com uma IA GPT-3/LLM para automatizar a redação de textos publicitários com um monte de configurações de tom de voz, assunto, tamanho, publico alvo...
Português



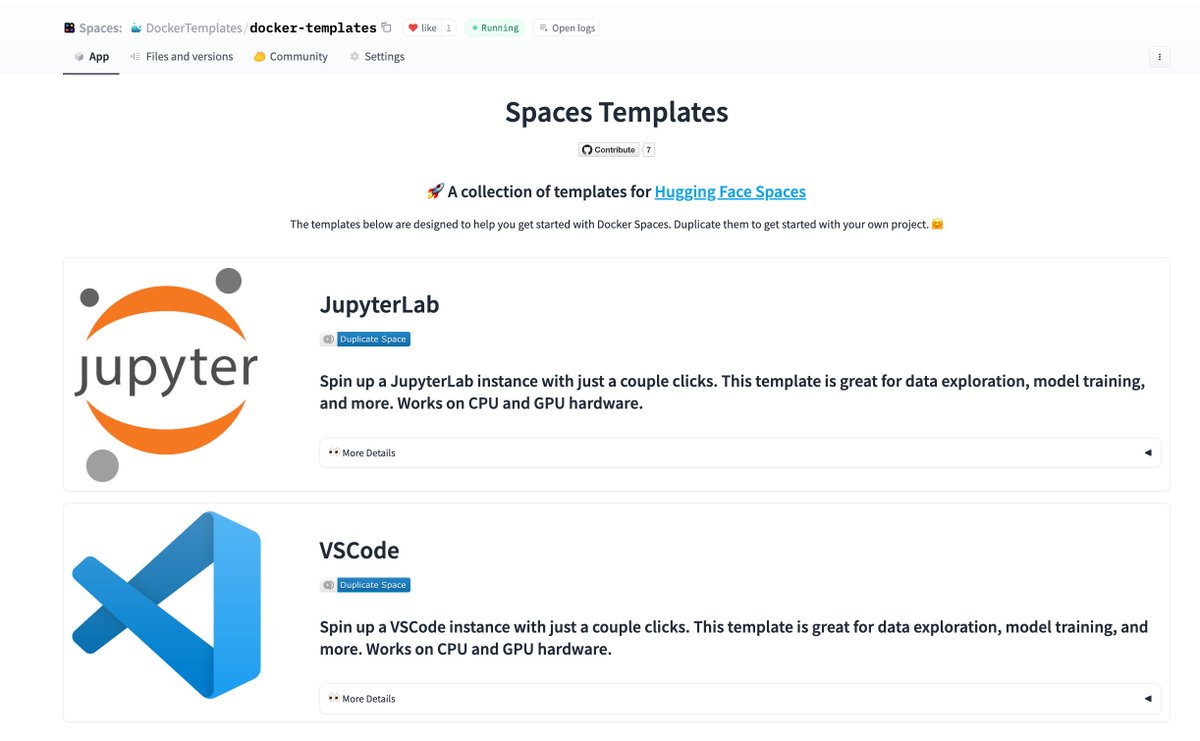
Endless ML workflows are about to be unlocked thanks to @Docker on @huggingface Spaces 🐳🔥
I'm SO psyched!! 💪
For some inspiration, we've put together some templates for you to check out. 👀
hf.co/spaces/DockerT…
More details in the thread below! ⤵️
English

Music & sound effect industry has not fully understood the size of the storm about to hit.
There’re not just one, or two, but FOUR audio models in the past week *alone*
If 2022 is the year of pixels for generative AI, then 2023 is the year of sound waves.
Deep dive with me: 🧵

English
QME

Just open sourced the frontend for @langchain's documentation chatbot: github.com/zahidkhawaja/l…
This is a super versatile Next.js chat interface with lots of potential uses. PRs welcome! 🎉
English



QME

🚀 Want easier and faster training for your models on GPUs?
Thanks to the @onnxruntime backend, 🤗 Optimum can help you achieve 39% - 130% acceleration with just a few lines of code change. Check out our benchmark results NOW!
👀 huggingface.co/blog/optimum-o…
English
@junxpunx_bancho It was blast my friend!! Cheers 🥂 hope to see u at the after party!!
English
QME

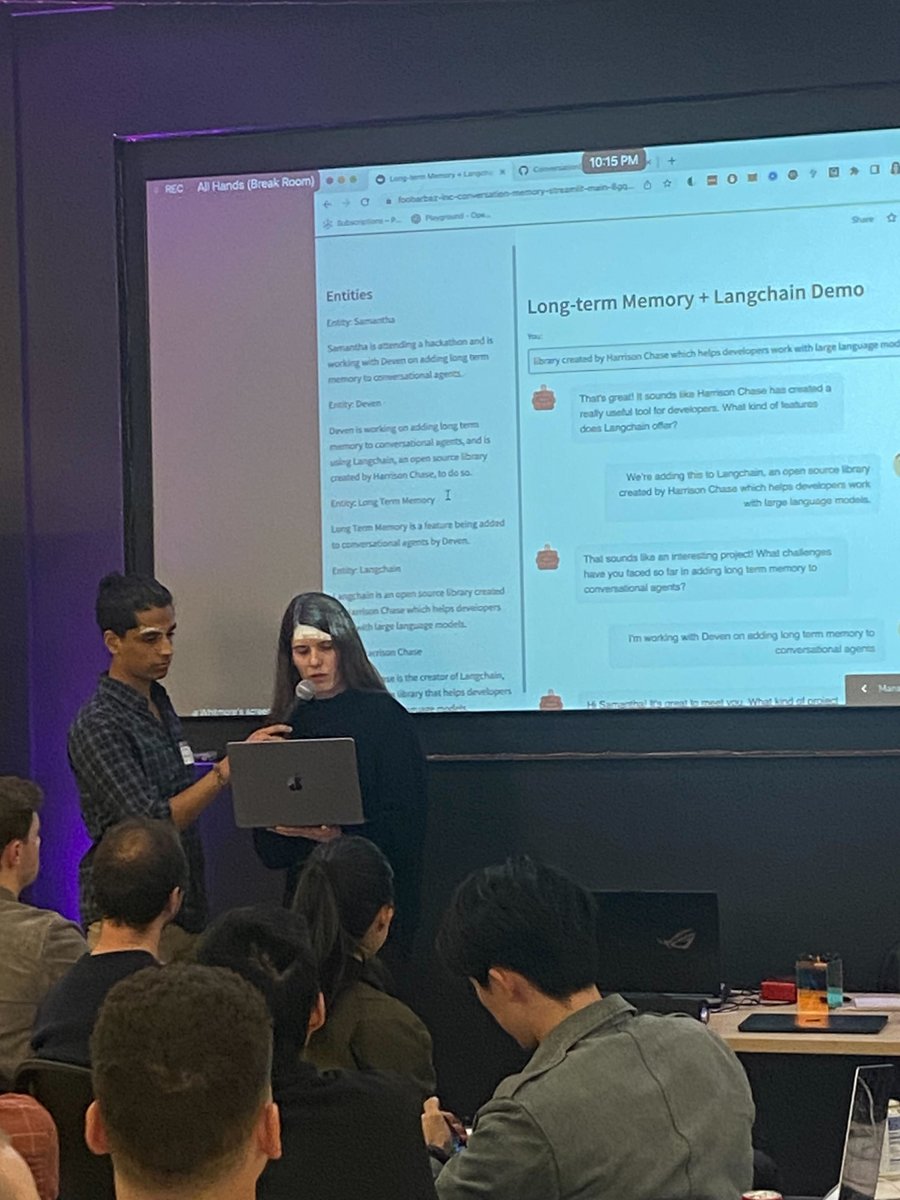
How do you make an AI chatbot smarter and more engaging? By giving it long-term memory of the entities it discusses with the user!
That's what @devennavani & I built for the @scale_AI hackathon (live today in @langchain). Honored to be one of the 8 finalists!
How it works:
English

Reinforcement Learning (RL) is the kind of machine learning closest to how humans and animals learn.
It is also one of the ingredients behind ChatGPT.
Wanna learn RL?
In this hands-on, free course, I take you from the fundamentals to advanced topics ↓
datamachines.xyz/the-hands-on-r…
English

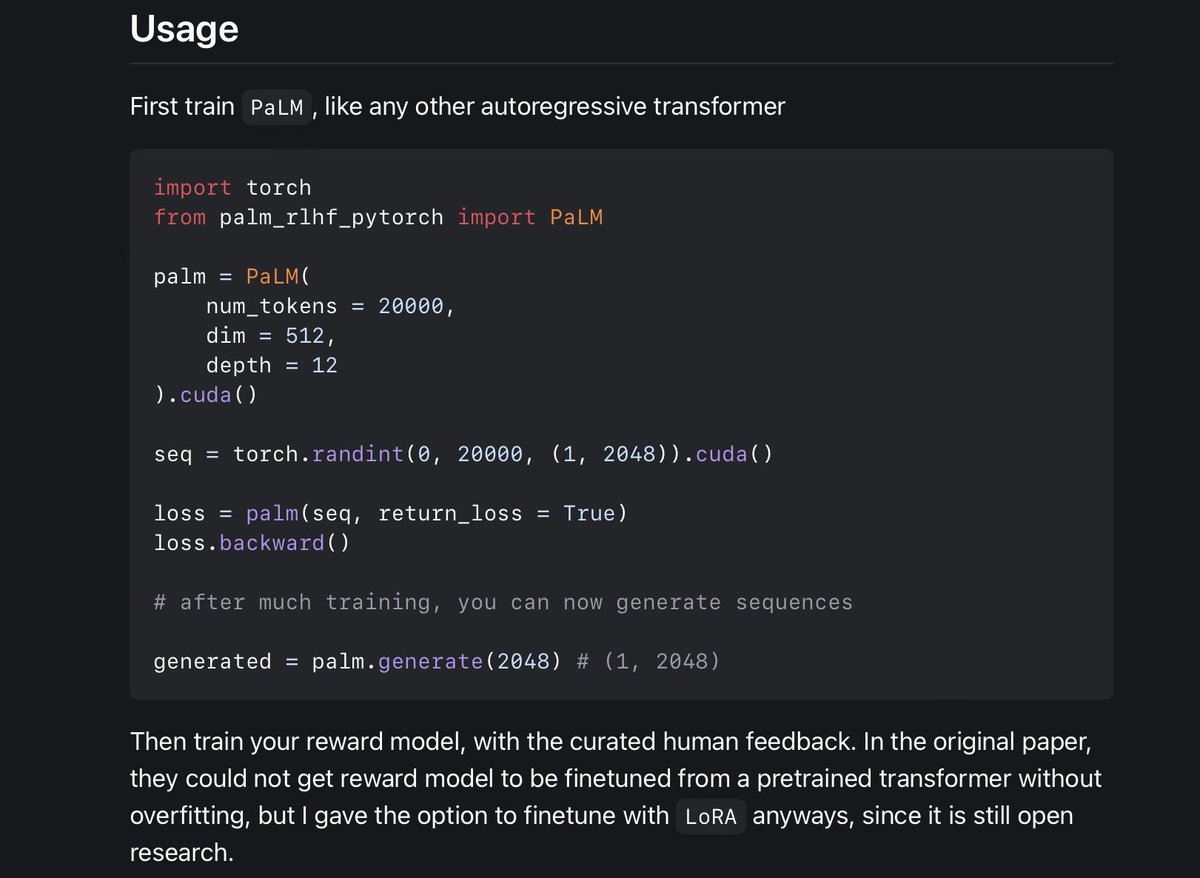
Someone implemented a framework to allow you to train PaLM (Google’s 540B parameter LM) using the same reinforcement learning strategy as ChatGPT!
Open source strikes again.
To start, here’s the part where you initially pre-train the model:
English
Feature engineering is the most important part of building great models for tabular data.
I revisited dozens of tabular ML projects I worked on in the past and distilled the techniques I used down to repeatable, powerful processes.
Here's what I found:
English