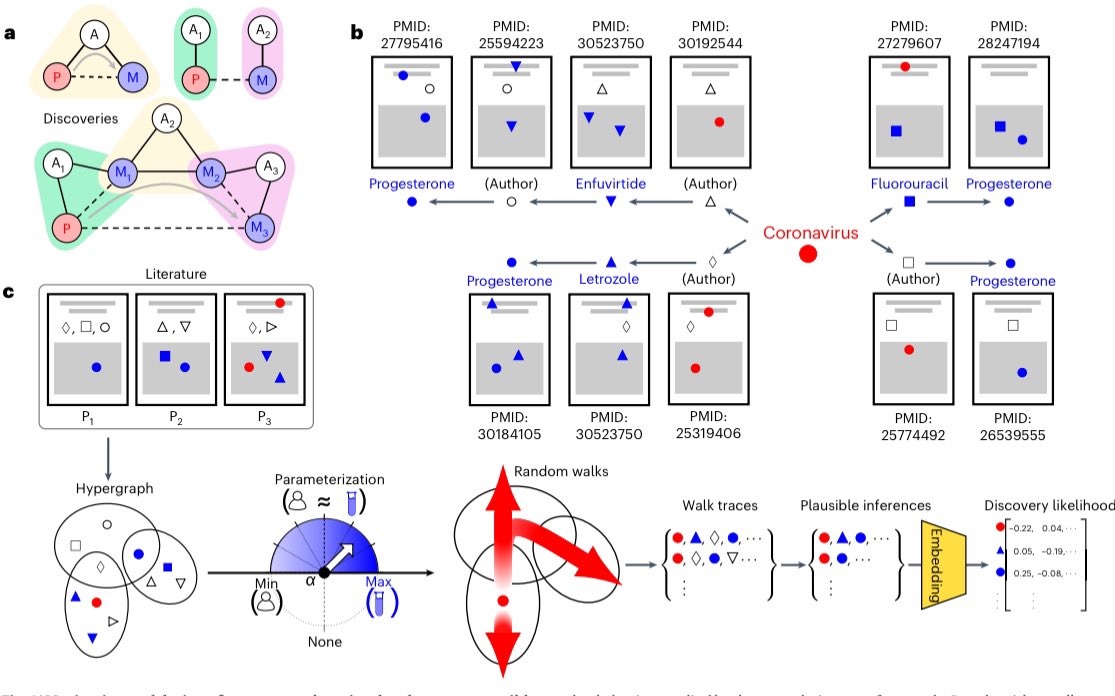
Sabitlenmiş Tweet

I am thrilled to share my first article as a first author. Last semester while working as a T.A we implemented a set of 12 tutorials related to different bioinformatics topics within Jupyter Notebooks running on Google Colab. pubs.acs.org/doi/10.1021/ac… (1/4)
English