
fidgety
332 posts


@ycombinator @TryLance Can it check me into the hotel in under 10 minutes?
English

Congrats to @TryLance on their $5M seed!
Lance builds AI agents that run hotel operations, handling guest communication and executing the work behind the scenes.
Hotels still rely on calls, radios, and manual coordination. Staff miss inbound calls, juggle requests across disconnected systems, and spend hours on repetitive tasks instead of serving guests.
Lance acts like an autonomous operator. Their agents answer calls and messages, create and route work orders, update systems, and coordinate staff in real time. This means faster responses, fewer missed bookings, and a more efficient operation overall.
lance.live/blogs/announci…
English
@ericzakariasson I’m seeing a lot bugs with the file system:
1. Doesn’t immediately update with new files/folders
2. Clicking a file doesn’t open it
3. cmd+p doesn’t show the obvious file / sometimes shows file from a different project
Also for really long chats I have seen it hang/crash
English

how can we make cursor 3 better?
send us any bugs, feature requests, or feedback you have!

English

🚨 SAM ALTMAN: “We see a future where intelligence is a utility, like electricity or water, and people buy it from us on a meter.”
English

nice to see someone prove this
been rolling with this technique for years, it's a huge edge
BURKOV@burkov
LLMs process text from left to right — each token can only look back at what came before it, never forward. This means that when you write a long prompt with context at the beginning and a question at the end, the model answers the question having "seen" the context, but the context tokens were generated without any awareness of what question was coming. This asymmetry is a basic structural property of how these models work. The paper asks what happens if you just send the prompt twice in a row, so that every part of the input gets a second pass where it can attend to every other part. The answer is that accuracy goes up across seven different benchmarks and seven different models (from the Gemini, ChatGPT, Claude, and DeepSeek series of LLMs), with no increase in the length of the model's output and no meaningful increase in response time — because processing the input is done in parallel by the hardware anyway. There are no new losses to compute, no finetuning, no clever prompt engineering beyond the repetition itself. The gap between this technique and doing nothing is sometimes small, sometimes large (one model went from 21% to 97% on a task involving finding a name in a list). If you are thinking about how to get better results from these models without paying for longer outputs or slower responses, that's a fairly concrete and low-effort finding. Read with AI tutor: chapterpal.com/s/1b15378b/pro… Get the PDF: arxiv.org/pdf/2512.14982
English

Kinda crazy lol
BURKOV@burkov
LLMs process text from left to right — each token can only look back at what came before it, never forward. This means that when you write a long prompt with context at the beginning and a question at the end, the model answers the question having "seen" the context, but the context tokens were generated without any awareness of what question was coming. This asymmetry is a basic structural property of how these models work. The paper asks what happens if you just send the prompt twice in a row, so that every part of the input gets a second pass where it can attend to every other part. The answer is that accuracy goes up across seven different benchmarks and seven different models (from the Gemini, ChatGPT, Claude, and DeepSeek series of LLMs), with no increase in the length of the model's output and no meaningful increase in response time — because processing the input is done in parallel by the hardware anyway. There are no new losses to compute, no finetuning, no clever prompt engineering beyond the repetition itself. The gap between this technique and doing nothing is sometimes small, sometimes large (one model went from 21% to 97% on a task involving finding a name in a list). If you are thinking about how to get better results from these models without paying for longer outputs or slower responses, that's a fairly concrete and low-effort finding. Read with AI tutor: chapterpal.com/s/1b15378b/pro… Get the PDF: arxiv.org/pdf/2512.14982
English
@Rafael_ Also, I think BlueCo has the right model and foundations in place vs. Abramovich era. Previously, new manager was given full control which resulted in a lot of player turnover and no sustained success. BlueCo, has centralized talent and then finding a coach that fits the squad.
English

Sorry but I ain’t eating up this Liam Rosenior prop.
It’s not his fault, but BlueCo is the real enemy and we can’t let the flame of anger from their actions be extinguished so easily.
Maresca should not have been sacked for asking for higher standards. It’s as simple as that.
English

@zeeg @mitchellh Nearly everytime I login to Sentry I get a CSRF error page and have to login a 2nd time
English


@SaifullahKomol @Marescaholic @CFCPys If you have any comprehension skills and were intellectually honest, you’ll realize that Chelsea with a better net spend and more major trophies is in a much better position, while Arteta still finds excuses.
English
@SaifullahKomol @Marescaholic @CFCPys Second, we have won more trophies and far more important ones while Arteta has been at Arsenal. But now suddenly trophies doesn’t matter. Which should have been obvious to be since you are an Arsenal fan lol
English

@SaifullahKomol @Marescaholic @CFCPys lol first of all look at the thread, it was Arteta complaining about having 1 less day to prepare. Second, after all the money Arteta has spent, he only has an FA cup and Community Shield to show for it lol.
English

@fidgetswishy @Marescaholic @CFCPys That doesn't mean anything. You had 2 billions to improve your squad during last two seasons and here you are complaining.
English
@SaifullahKomol @Marescaholic @CFCPys Our net spend is less than Arsenal over the last 5 and 10 years.
transfermarkt.us/premier-league…
English
@Marescaholic @CFCPys Chelsea had 2 billion euro head start. Let's not do this.
English

A human right cannot be dependent on the labor of others. This is tautological.
Pramila Jayapal@PramilaJayapal
Health care is a human right.
English
English

@markbrooks @irishScott2 You're stating a distinction without a difference.
It's not optional for emergency services to take a call. If you're a firefighter, whether collective arrangement or not, you have a mandatory individual obligation that you accepted.
Explain how healthcare should be different.
English

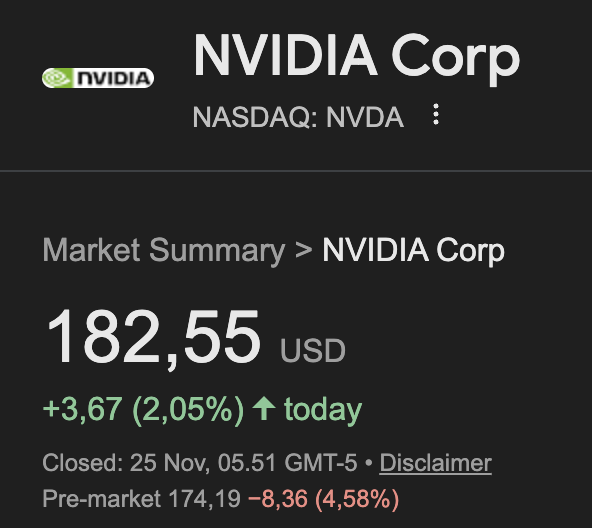
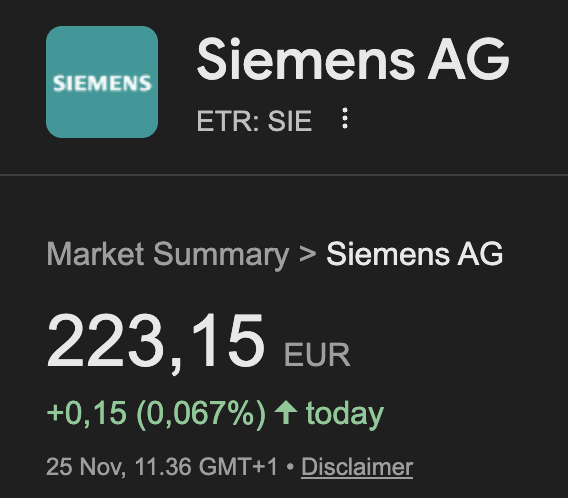
Why do we pretend US is a tech superpower when numbers say otherwise?
Siemens (the biggest European tech company) is worth 22% MORE than your overhyped Nvidia
Stock prices don't lie
Maybe if US companies spent less time on creating hype and more time building real products, they wouldn't be destroyed by European tech
Never been more bullish on Europe
English

My man out here getting triggered by jokes. How ironic. Well don't worry about me, Myron. I got no issue putting a bitch in her place. For example:
Myron Gaines@MyronGainesX
I'm never wrong about these women... Stupid ass jeet @AkaashSingh tried to lecture me about women years ago with his equally retarded co-host @andrewschulz aka AnJew Schulztein... Here's this jeet's stupid ass wife making a mockery of him and herself on a podcast. youtu.be/Z-LTSDfS9ek?si… I'm about to cook him and her like curry when I get back to Miami...
English



You finally did it. You dockerized your entire app.
Your Node API, your React frontend, your Postgres DB all neatly packaged. Your docker-compose file brings it all up perfectly on your machine. You feel like a genius.
Then comes production.
You need reliability. You need scale. So you think, "I'll just run my containers on a few servers."
Suddenly, the simplicity vanishes.
- How do your frontend containers find the API containers when their IPs keep changing?
- What happens when a server dies at 3 AM? Who restarts those containers?
- How do you update your API image without bringing everything down?
Manually scripting this across multiple machines turns into a nightmare, fast. Your beautiful Docker setup is now tangled in SSH scripts and hope.
You've heard of Kubernetes (K8s). Maybe you think it's just Docker Swarm but way more complex or something only huge companies need.
That's missing the core idea.
Kubernetes isn't just about running containers. It's about managing them automatically, at scale. It's an orchestrator.
The fundamental shift is this: You stop telling servers what to do (imperative). You tell Kubernetes what you want the end result to look like (declarative).
You define your application's desired state in YAML files:
- I want 3 replicas of my API container running image v1.2.
- They need to be reachable via a stable network name called api-service.
- They need 500MB of RAM each.
You give this to Kubernetes. Its entire job is to constantly watch the actual state and force it to match your desired state.
This is how it solves all those production nightmares:
Automatic Bin Packing & Scheduling:
- K8s looks at your servers (Nodes) and figures out the best place to run your containers based on available resources. You don't manually assign containers to machines.
Self-Healing:
- A container crashes. K8s notices. Actual state (2 replicas) doesn't match desired state (3 replicas).
- It automatically starts a new container to replace the failed one. No human intervention needed.
Horizontal Scaling:
- Traffic spikes. You need 10 API containers, not 3.
- You change one line in your YAML file (replicas: 10). K8s handles the rest, starting new containers across your available servers. You can even set it to autoscale based on CPU or memory usage.
Service Discovery and Load Balancing:
- How do containers find each other? You create a Kubernetes 'Service'.
- K8s gives this service a stable internal IP and DNS name (like api-service).
- When another container calls api-service, K8s automatically routes the traffic to one of the healthy API containers, balancing the load. No more hardcoded IPs.
Automated Rollouts (and Rollbacks):
- Need to update your API to v1.3? You update the image version in your YAML.
- K8s performs a rolling update by default: it gradually starts new v1.3 containers and stops old v1.2 containers, ensuring zero downtime.
- Update goes wrong? K8s can automatically roll back to the previous stable version.
Kubernetes isn't just running containers.
It's the automated, resilient operating system for your entire distributed application. It lets you manage complexity declaratively, so you can focus on your code, not on firefighting servers.

English