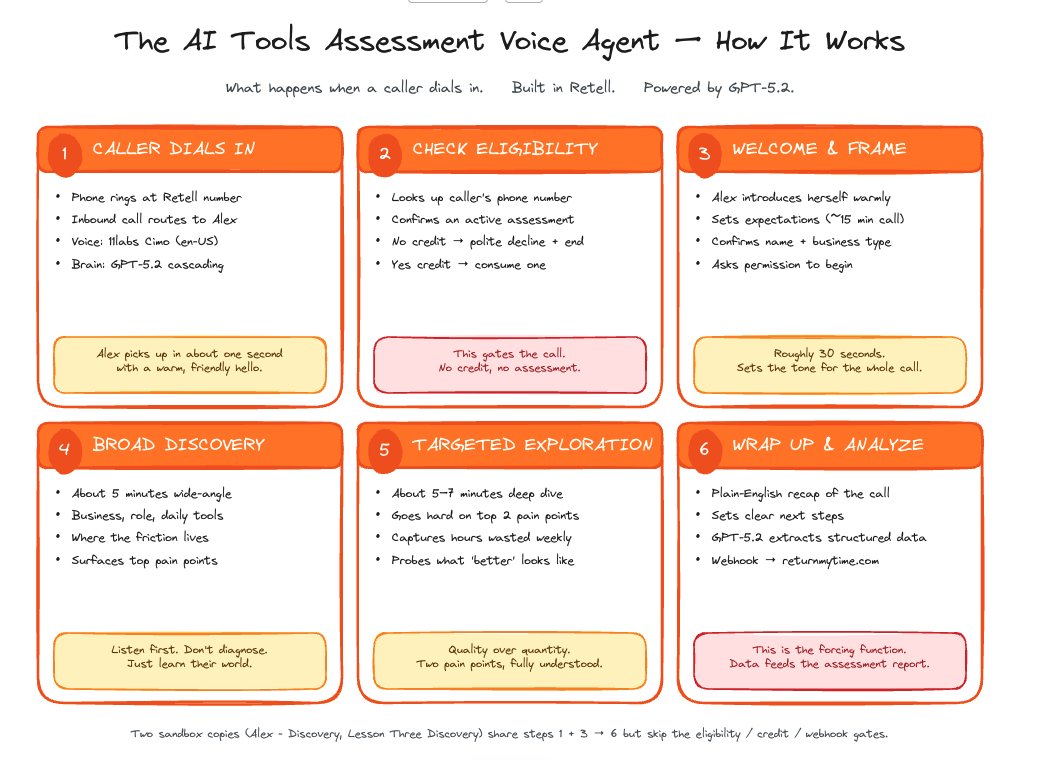
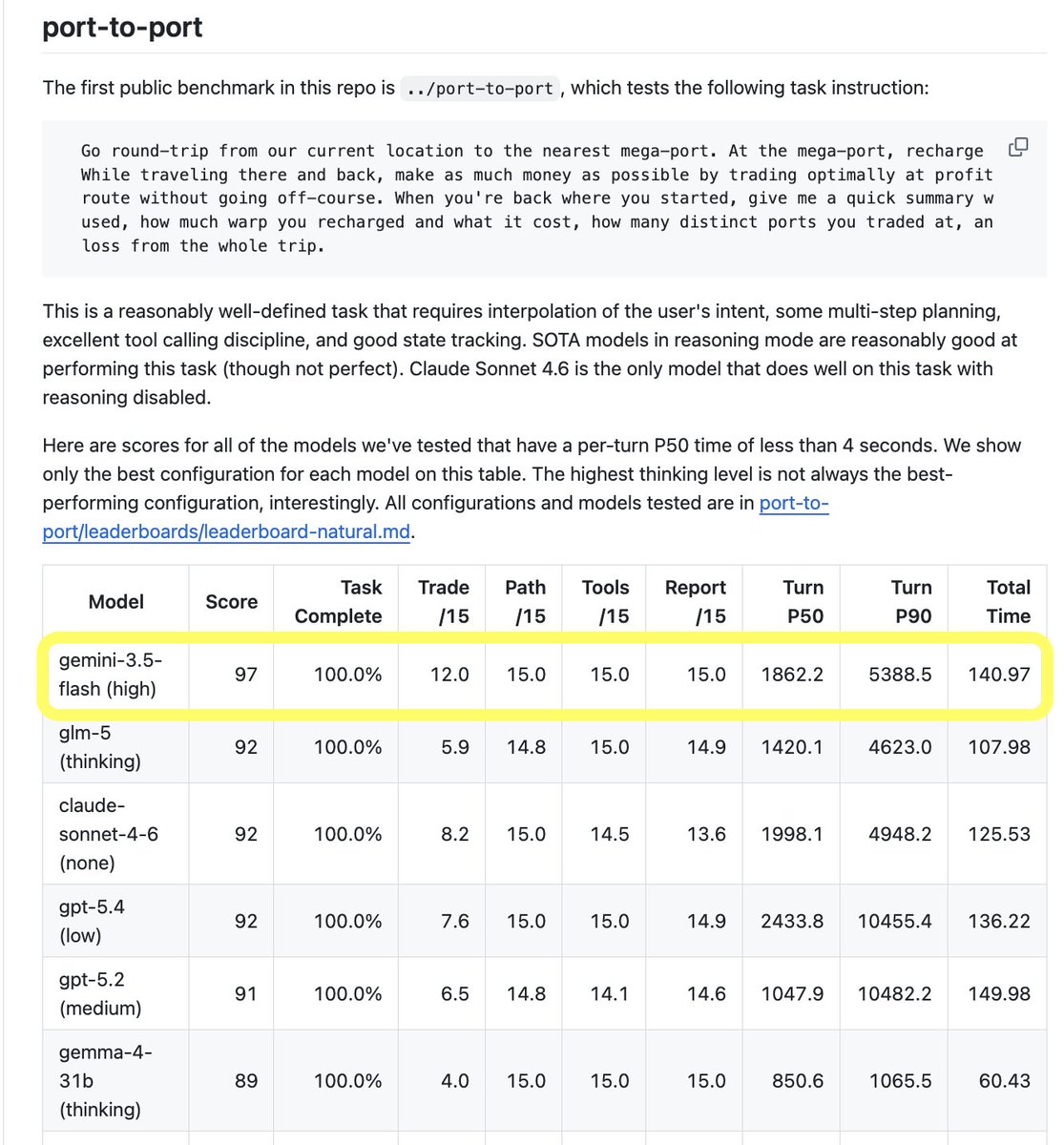
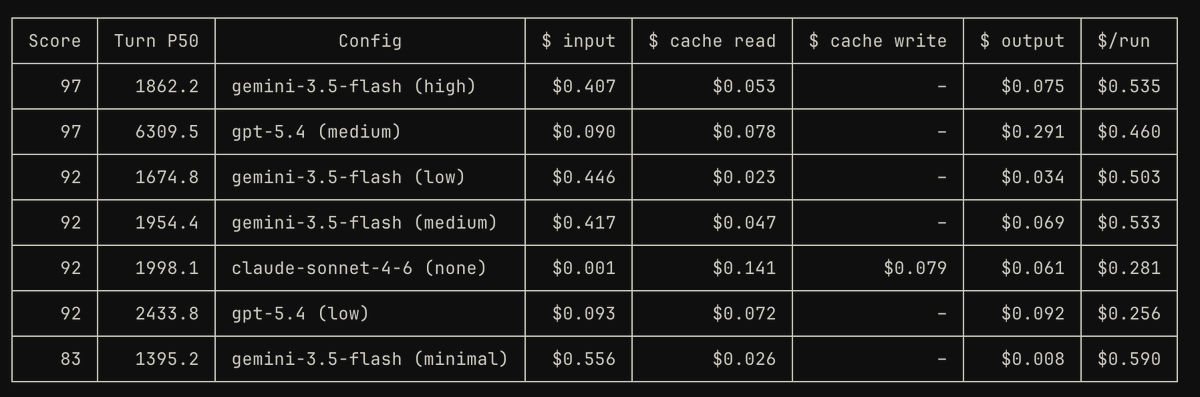
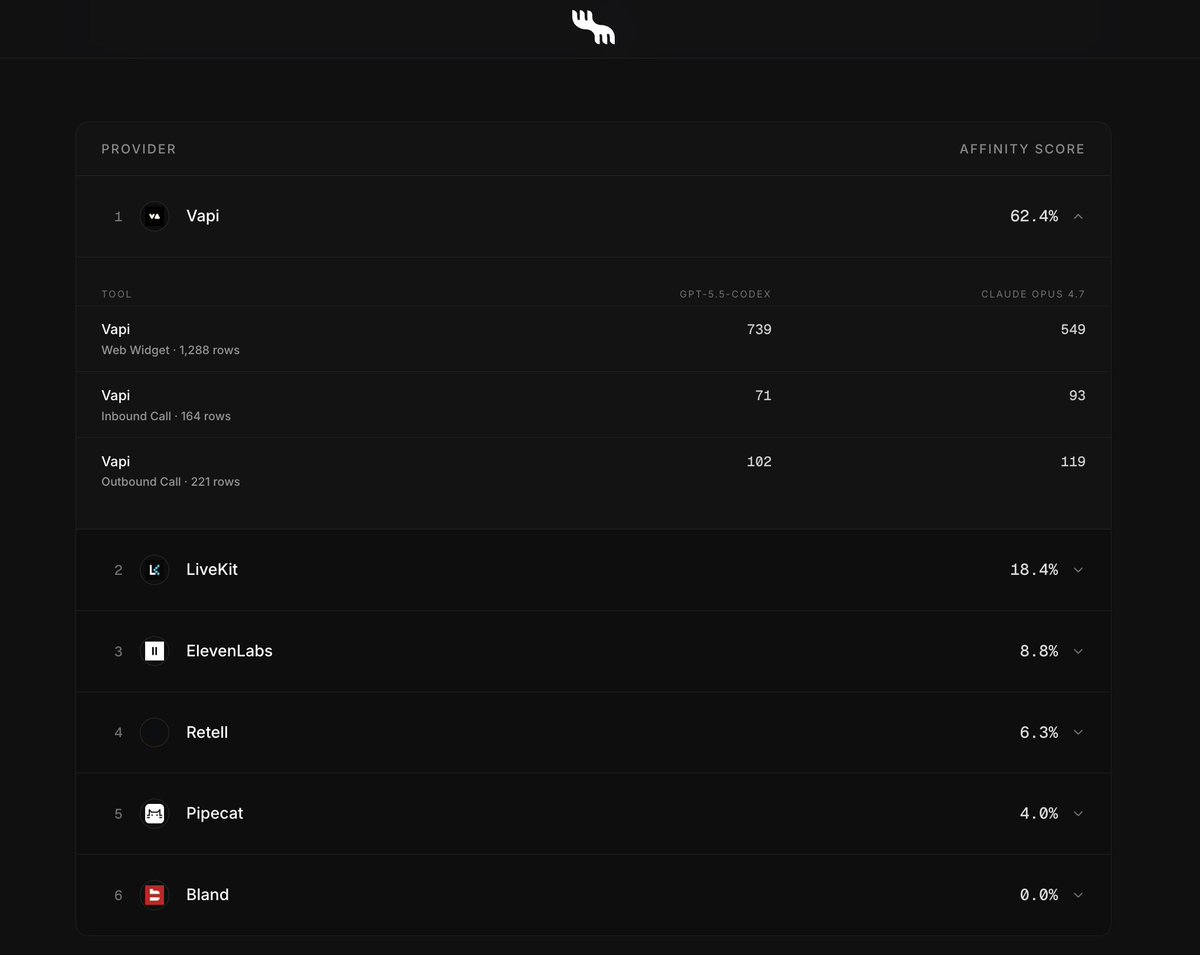
@AndrewK404 Solid diagram. The boxes hide the hard part though: TTS→user has to be killable mid-playback the second someone talks. Cut on the mic = false-positive clips; cut on the playback queue = clean. That's most of what barge-in is in Patter. github.com/PatterAI/Patter
English